MediaWiki 1.23.0 发布了,这是一个大的更新版本,包含很多新特性和 bug 修复,详细介绍请看 这里。
MediaWiki全球最著名的开源wiki程序,运行于PHP+MySQL环境。MediaWiki从2002年2月25日被作为维基百科全书的系统软件,并有大量其他应用实例。目前MediaWiki的开发得到维基媒体基金会的支持。

MediaWiki 1.23.0 发布了,这是一个大的更新版本,包含很多新特性和 bug 修复,详细介绍请看 这里。
MediaWiki全球最著名的开源wiki程序,运行于PHP+MySQL环境。MediaWiki从2002年2月25日被作为维基百科全书的系统软件,并有大量其他应用实例。目前MediaWiki的开发得到维基媒体基金会的支持。
select *
from (select v.sql_id,
v.child_number,
v.sql_text,
v.elapsed_time,
v.cpu_time,
v.disk_reads,
rank() over(order by v.elapsed_time desc) elapsed_rank
from v$sql v) a
where elapsed_rank <= 10;
select *
from (select v.sql_id,
v.child_number,
v.sql_text,
v.elapsed_time,
v.cpu_time,
v.disk_reads,
rank() over(order by v.cpu_time desc) elapsed_rank
from v$sql v) a
where elapsed_rank <= 10;
select *
from (select v.sql_id,
v.child_number,
v.sql_text,
v.elapsed_time,
v.cpu_time,
v.disk_reads,
rank() over(order by v.disk_reads desc) elapsed_rank
from v$sql v) a
where elapsed_rank <= 10;
我们已经看到使用物联网概念,在多种领域提供家庭自动化系统的一系列创业公司出现。有了 Spark, Thingsquare, Carriots这些已经预先建好的系统提供多种功能,这些公司实际上可以帮助你构建自己的物联网设备。所谓“物联网设备解决方案”这样的字眼,对门外汉来说只不过是一堆黑话而已,但是这些公司已经强调了自己动手做(DIY)的重要性,即使是完全不懂的人也可以亲自去操作。
让我们用一个例子来明白这一点:假设你正在做一项任务,要求你调查茶和咖啡之间的咖啡因含量,与不同情况下工作日在办公室之内的消费量之间的关系,以及它们对员工带来的兴奋程度作出评价。这就只能通过DIY来实现,并且下面三个解决方案都为你提供更简单和更精确的结果。
解决方案建议你在咖啡壶和水龙头之间安装一个流量计。这个流量计装备一个可以发送电脉冲信号的传感器,水流通过内部叶片的时候,就会被转化成电信号。在设立水流的单位(毫升)转化成电脉冲信号强度的方法之后,整个工作就完成了。使用一块Arduino板,可以获得更加精确的电脉冲记录。当这些脉冲信号被读出的时候,收集到的信息随后会被运送到Raspberry Pi电脑上。随后Raspberry Pi可以处理读取,保持日志,以及向云发送数据等任务。每次一杯咖啡被倒出来的时候,这个信息就被传到云端去,然后所有的数据都被储存,并且推送到外部的信息系统,供智能商业情报人员提取有用的信息。

类似这样的解决方案可以使用不同的组件来建造,不管是硬件还是软件,都可以由Spark, Thingsquare 和 Carriots这三家公司提供。举例说,Carriots 可以提供云服务以及其自己的情报平台,包括监听器(可以校准以及统计目标数据),触发器(可以推送数据)以及不同的API。自动化的控制面板可以使用任何互联网技术建造,前提是可以通过API和Carriots平台进行交流。它同时还提供多种不同的授权方案。
Spark( 参见动点此前报道)同样也是一个开源平台。它提供一个叫做Spark Core的解决方案,同时提供一款Wi-Fi的开发板,使得创造和互联网相连的硬件更加容易。这块开发板是一个可以安装在任何你想要远程遥控的设备上的芯片,设备是可以通过C/C++语言或者是汇编语言编程,无需通过电脑就实现无线连接。它可以被重新编程,可以直接通过芯片上的无线模块,连接到由Spark提供的云服务当中。有了这样的云服务,这个设备就可以在安全和有保障的情况下经由REST API被连接到任何其他地方去。设备同样还可以使用不带云支持的TCP 和 UDP通讯协议对外联系。工具包的售价是39美元。

Thingsquare 是用类似的方式工作的,通过他们提供的解决方案,芯片可以附加在想要控制的设备上。这些芯片运行开源的固件,是通过无线或者局域网连接到云端。这种方式可以构建家庭或者办公室的自动化系统,而付出的代价是最低的。后端是和API相连接的。这家公司已经和德州仪器合作共同制造无线芯片,典型的来说,这个芯片可以兼容灯具,测量仪器,以及无线传感器设备。
这些创业公司提供的方案,向你提供了控制自己设备的理想的平台,以及远程,安全的存储和评估数据的方式。这是一种平台即服务(PaaS)的典型案例;当然,有些需要内置的硬件和微处理器芯片来支持。(译:dio)
图片来源:Shutterstock
3 Startups That Help You Build Your Own Internet of Things
本文 三家企业帮助你建造自己的物联网来自 动点科技.
还记得OpenSSL 心脏滴血漏洞么?几周前,这一漏洞的披露曾震惊互联网,全球有上百万使用OpenSSL对通信进行加密的网站受到该漏洞的影响。
无独有偶,OpenSSL基金会最近又发布了一些更新,修复了六个OpenSSL中的安全漏洞,其中两个为严重级别。
中间人攻击(CVE-2014-0224)
OpenSSL中的第一个严重漏洞(CVE-2014-0224)被称为“CCS 注入”。在OpenSSL建立握手连接的阶段,会发送一种名为ChangeCipherSpec(CCS)的请求,在发送该请求时,攻击者可以通过中间人攻击来劫持服务端与客户端之间的加密通信。
利用该问题,攻击者能够解析加密的链接并将其解密,读取或对通信数据进行操作。但该问题如想成功利用必须服务端域客户端双方均存在该问题。
根据OpenSSL的 报告,“攻击者使用精心构造的握手包能够强制客户端和服务端之间使用弱密钥进行通信。”客户端的OpenSSL所有版本均受影响。只有1.0.1及以上版本是影响服务端的。尤其是一些SSL VPN产品,在该漏洞前几乎全军覆没。
OpenSSL CCS注入漏洞是由一位来自日本Lepidum安全公司的安全研究人员Masashi Kikuchi发现的。根据他的描述,该问题在OpenSSL第一版发布时就已经存在了。RedHat随后也在他们的安全博客中解释了该漏洞的一些 细节。
无效的DTLS碎片漏洞(CVE-2014-0195):向OpenSSL DTLS的客户端或服务端发送无效的DTLS碎片能够导致缓冲区溢出攻击。潜在的攻击者能够利用该漏洞在受影响的客户端或服务端中执行任意代码。
DTLS死循环DOS攻击(CVE-2014-0221):远程攻击者能够发送无效的DTLS握手请求来使目标的处理逻辑进入死循环状态并最终耗尽资源而崩溃。该攻击仅影响将OpenSSL作为DTLS客户端的应用。
好消息是这些 漏洞都没有心脏滴血漏洞那么严重。打过补丁的版本是0.9.8za,1.0.0m和1.0.1h,在OpenSSL官网中已经提供下载了。OpenSSL官方呼吁各厂商尽快更新他们的SSL实现。
via:http://thehackernews.com/2014/06/openssl-vulnerable-to-man-in-middle.html
一般来说,电子商务网站数据分析包括:流量来源分析、流量效率分析、站内数据流分析和用户特征分析四个部分。
我们先来说说流量来源分析。
企业电子商务网站要想在网上接到生意,流量是保证。但是流量的获得是需要成本的,如何降低流量成本就成为了企业电子商务网站运营的很重要的一部分。其中流量来源分析可谓是重中之重,主要是要明白:你的用户都是从那些网站来的,哪些网站的给你带来更多的订单、哪些网站的流量是真实的,哪些是虚假等。
流量分析一般包括以下内容:
搜索引擎关键词分析:根据关键词的来源分析来查看网站产品分布和产品组合。如果关键词查询多的产品却不是网站的主推品,可以进行适当调整。
网站流量趋势分析:网站的流量是否均衡稳定,是不是有大幅度波动。一般来说流量突然增加的网站,如非发生突发事件,购买的广告位作弊的嫌疑比较大。
网站流量核对:查看是否有莫名流量来源,流量来源大不大。如果莫名来源流量很大的话,有可能是您购买的CPC或者其他资源被注水了,将您的广告链接分包给了点击联盟。
推介网站与直接访问的比例:推介网站可以理解为外部广告,直接访问就是用户直接输入网址。一般来说,直接访问量越大说明网站的品买知名度越高。
其次是流量效率分析
流量效率是指流量到达了网站是不是真实流量,主要分析指标如下:
到达率:到达率是指广告从点击到网站landing page的比例。一般来说,达到率能达到80%以上是比较理想的流量。这个也跟网站的速度有关,综合来分析一下。
PV/IP比:一般来说,有效的流量,网站内容比较好的话,一个独立IP大概能有3个以上的PV。如果PV/IP比能达到3以上的话,一般说明流量比较真实,网站内容也不错。但是如果低于3的话,并不代表流量不真实,也可能是网站本身的问题。如果PV/IP过高的话,也可能有问题,比如人力重复刷新等,要谨慎对待。
订单转化率:这个是最最核心的数据了,没有订单转化率,其他一切都是免谈!
站内数据流分析,主要用来分析购物流程是否顺畅和产品分布是否合理,一般如下:
页面流量排名:主要查看产品详情页的流量,特别是首页陈列的产品详情页。参照最终的销售比例,优胜劣汰,用以调整销售结构。
场景转化分析:从首页-列表页-详情页-购物车-订单提交页-订单成功页,的数据流分析。比如说,首页到达了10000用户,各页面数据分别是10000-8000-5000-1000-50-5,购物车到订单提交页的相差比较大,大概就能看出来是购物车出了问题,需要改进。
频道流量排名:各个频道流量的排名,主要用来考虑产品组织的问题。
站内搜索分析:这个反应的是用户关心的产品有哪些,产品调整的最直接数据。
用户离开页面分析:用户在那些也页面离开最多?是首页还是频道页?是购物车还是订单提交页。突然的大比例的离开网站,往往预示这问题的存在。
最后是用户特征分析:
用户停留时间:这个放在用户特征分析里有些牵强。而且目前监控用户停留时间的方式是:用户到达时间-用户离开时间,但是用户什么时候离开很难准确判断,这种数据仅作参考,一般停留时间越长网站粘性越好。如果用户停留时间超过1个小时,基本就是假流量,或者打开网页忘记关了。
新老用户比例:老用户比例越高,证明用户忠诚度不错。但是还要考虑绝对量,不能靠新用户越来越少来衬托老用户比例越来越高。
用户地域分析:用户地域与订单地域分布基本一致,基本上就是用过互联网用户的分布比例以及经济发达程度等。这个对于提升区域配送及服务比较有帮助。
电子商务网站的基本数据分析就是以上这些,作为实际操作人员要根据数据分析的情况来发现问题和总结问题,进而优化网站的结构和用户体验、来提升网站的专转化率和用户忠诚度。这些都是电子商务很重要的基础工作。
现在的App开发已经进入到了必须靠推广运营才能上位的时代,有用户不代表什么,有活跃度稍表欣慰,有留存率稍表欣慰,看到真金白银才会喜上眉梢,毕竟最近最火的是游戏应用,它们才是捞到钱的新晋金主,但是它们赚到钱都是有过程的,各位开发者从开发到运营过程中都应该一步一步过来,着重关心下面几个数据:
1. 真实用户数
虽然说用户不代表什么,但是获取用户是推广的第一步。这个阶段你需要做的是①让App在十几秒内抓住你的用户②通过应用市场下载③通过广告渠道④通过适合自己的推广渠道。
然后统计用户数,要注意的是,因为下载量、安装量这些数据都比较虚,不能真实反映用户是否已经被获取。所以大家都要看激活,这才是真正获取到了新的用户。另一个非常重要的数据,就是分渠道统计的激活量,这样可以知道哪个渠道是最有效果的。
2. 每周、每月活跃度
因为获得的用户数中有一部分以广告、预装的的形式进来的用户,并非主动进入的用户,这时候就要通过应用本身内涵、体验良好的新手教程、有噱头的设计、向热门的东西靠拢来吸引这些“偶然误闯”的用户,并及时记录用户转化率、新手引导过程流失情况,而活跃度应该记录好周活跃、15天活跃、月活跃度。
3. 日留存率、周留存率
有活跃度后你要考虑你的用户粘性,这时要以保住老客户优先,因为成本低很多,怎么保存呢?
1)先统计,日留存率、周留存率(有些应用是不需要每日启动的)、月留存率(曾经有游戏行业的行家指出,如果想成 为一款成功的游戏,1-Day Retention要达到40%, 7-Day Retention要达到 20%。)
2)区分你的App类型,比如游戏的首月留存率比社交高,工具的首月留存率又比游戏高
3)然后在这些用户流失之前想办法提高他们的积极性。

4. 盈利:收入—成本
目前国内开发者被证实可行的盈利方式包括应用内付费和依靠合作者的运营支付和广告平台这两种,前面3个环节做好了,基数大了,平均转化成本和回报率提高了,盈利就实现了。
关于收入,大家最耳熟能详的指标就是ARPU(平均每用户收入)值 。利润最简化的计算公式是:利润=收入-成本。收入如何计算? ARPU是一个和时间段相关的指标(通常讲的最多是每月的ARPU值),还不能完全和CAC(用户获取成本)对应,所以我们还要多看一 个指标:LTV(生命周期价值)。用户的生命周期是指一个用户从第一次启动应用,到最后一次启动应用之间的周期。LTV就是某个用户在生命周期内为该应用创造的收入总计,可以看成是一个长期累计的ARPU值。每个用户平均的LTV = 每月ARPU * 用户按月计的平均生命周期。LTV – CAC的差值,就可以视为该应用从每个用户身上获取的利润。
5. 后续传播指数
后续传播的一个典型媒介就是社交网络,如果产品自身足够好,有很好的口碑。从自传播到再次获取新用户,应用运营会形成了一个螺旋式上升的轨道。而那些优秀的应用就很好地利用了这个轨道,不断扩大自己的用户群体。
以K因子(K-factor)为衡量指标,K = (每个用户向他的朋友们发出的邀请的数量) * (接收到邀请的人转化为新用户的转化率)。假设平均每个用户会向20个朋友发出邀请,平均转化率为10%的话,K =20*10%=2。当K>1时,用户群就会象滚雪球一样增大;K<1的话,那么用户群到某个规模时就会停 止通过自传播增长。
最后,记住如果只看推广,不重视运营中的其它几个层次,任由用户自生自灭,那么应用的前景必定是暗淡的,所以不同阶段应该关心好每个阶段的数据。
改编自 知乎 VS 189works
Hbase 全称是Hadoop DataBase ,是一种开源的,可伸缩的,高可靠,高性能,面向列的分布式存储系统。
类似于Google的BigTable,其分布式计算采用MapReduce,通过MapReduce完成大块数据加载和全表扫描操作。文件存储系统是HDFS,通过Zookeeper来完成状态管理协同服务。不过BigTable只支持一级索引,而Hbase支持一级和二级索引。
需要指出的是:Hbase是面向列的数据库是说的Hbase以列簇的模式进行存储,而不是说Hbase本身是面向列的数据库。Hbase充分利用Lee磁盘上列存储格式的特性,它和传统的Columner databases 还是有区别的。Columner databases擅长做实时数据分析访问,而hbase在基于key的单值访问和范围扫描比较突出。
由于Hbase是基于Hadoop Mapreduc来处理数据的,而且数据也是存储在HDFS中,所以您需要先安装hadoop,本文是单机环境。您需要参考本人博客的CDH4_hadoop2.0安装来完成hadoop安装。
安装完成启动之后你只需要下边命令即可完成安装:
Yum install hbase-master
Yum install hbase-rest
启动hbase-master服务
Service hbase-master start
Service hbase-rest start
启动完成之后你需要下边命令进入hbase的控制面板
hbase shell
查看Hbase服务状态
hbase(main):001:0> status
1 servers, 0 dead, 15.0000 average load
查看Hbase版本
hbase(main):003:0> version
0.94.6-cdh4.3.0, rUnknown, Mon May 27 20:22:05 PDT 2013
操作一个信息表来演示HBase用法。创建一个student表,结构如下:
RowKey | address | info | ||||
| City | contry | province | Age | Birthday | sex |
zhangsan | Bj | Cn | Bj | 23 | 90 | man |
这个表中address和info都是有三个列的列簇。
①创建一个表student
hbase(main):007:0> create 'student' ,'class' , 'class_id' , 'address' , 'info'
0 row(s) in 1.7210 seconds
=> Hbase::Table - student
②列出所有表
hbase(main):001:0> list
TABLE
student
③查看表结构
hbase(main):019:0> describe 'student'
DESCRIPTION ENABLED
{NAME => 'student', FAMILIES => [{NAME => 'address', DATA_BLOCK_ENCODING => ' true
NONE', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSIONS => '3', COMP
RESSION => 'NONE', MIN_VERSIONS => '0', TTL => '2147483647', KEEP_DELETED_CEL
LS => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', ENCODE_ON_DISK =>
'true', BLOCKCACHE => 'true'}, {NAME => 'class', DATA_BLOCK_ENCODING => 'NONE
', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESS
ION => 'NONE', MIN_VERSIONS => '0', TTL => '2147483647', KEEP_DELETED_CELLS =
> 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', ENCODE_ON_DISK => 'tru
e', BLOCKCACHE => 'true'}, {NAME => 'class_id', DATA_BLOCK_ENCODING => 'NONE'
, BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSI
ON => 'NONE', MIN_VERSIONS => '0', TTL => '2147483647', KEEP_DELETED_CELLS =>
'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', ENCODE_ON_DISK => 'true
', BLOCKCACHE => 'true'}, {NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLO
OMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSION =>
'NONE', MIN_VERSIONS => '0', TTL => '2147483647', KEEP_DELETED_CELLS => 'fal
se', BLOCKSIZE => '65536', IN_MEMORY => 'false', ENCODE_ON_DISK => 'true', BL
OCKCACHE => 'true'}]}
1 row(s) in 0.0980 seconds
④删除一个列簇。删除一个列簇 需要2步,首先disable表,最后要enable表。
之前简历了3个列簇,但是class和class_id我们用不到,所以准备删除他。
命令如下:
hbase(main):041:0> disable 'student'
0 row(s) in 2.4160 seconds
删除:
hbase(main):042:0> alter 'student' , {NAME=>'class',METHOD=>'delete'}
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 2.4710 seconds
启用student
hbase(main):006:0> enable 'student'
0 row(s) in 2.2060 seconds
⑤删除表
hbase(main):012:0> disable 'abc'
0 ro(s) in 2.1720 seconds
hbase(main):014:0> drop 'abc'
0 row(s) in 1.1720 seconds
⑥验证表是否存在
hbase(main):001:0> exists 'abc'
Table abc does not exist
0 row(s) in 1.0410 seconds
⑦判断表是否enable
hbase(main):005:0> is_enabled 'student'
true
0 row(s) in 0.0220 seconds
⑧判断表是否disable
hbase(main):009:0> is_disabled 'student'
false
0 row(s) in 0.0090 seconds
⑨增加一个列簇
hbase(main):016:0> alter 'student' , {NAME=>'test' ,VERSIONS=>5}
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.1850 seconds
①向表中插入几条数据
hbase(main):026:0> put 'student' , 'zhangsan','info:age','23'
0 row(s) in 0.0870 seconds
hbase(main):027:0> put 'student' , 'zhangsan','info:birthday','90'
0 row(s) in 0.0890 seconds
hbase(main):028:0> put 'student' , 'zhangsan','info:sex','man'
0 row(s) in 0.0830 seconds
hbase(main):029:0> put 'student' , 'zhangsan','address:city','bj'
0 row(s) in 0.0510 seconds
hbase(main):030:0> put 'student' , 'zhangsan','address:contry','cn'
0 row(s) in 0.0880 seconds
hbase(main):031:0> put 'student' , 'zhangsan','address:provinc','bj'
0 row(s) in 0.0100 seconds
②获取一条数据
获取一个ID的所有数据:
hbase(main):049:0> get 'student','zhangsan'
COLUMN CELL
address:city timestamp=1401937717401, value=bj
address:contry timestamp=1401937730454, value=cn
address:provinc timestamp=1401937746616, value=bj
info:age timestamp=1401937660360, value=23
info:birthday timestamp=1401937675146, value=90
info:sex timestamp=1401937698368, value=man
6 row(s) in 0.1020 seconds
③获取一个ID,一个列簇的所有数据
hbase(main):060:0> get 'student' , 'zhangsan' , 'info'
COLUMN CELL
info:age timestamp=1401937660360, value=23
info:birthday timestamp=1401937675146, value=90
info:sex timestamp=1401937698368, value=man
3 row(s) in 0.0680 seconds
④获取一个ID,一个列簇中的一个列的所有数据
hbase(main):067:0> get 'student' , 'zhangsan' , 'info:age'
COLUMN CELL
info:age timestamp=1401937660360, value=23
1 row(s) in 0.0500 seconds
⑤更新一条记录
将张三的性别改成women
hbase(main):072:0> put 'student', 'zhangsan' , 'info:sex' , 'women'
0 row(s) in 0.0810 seconds
hbase(main):073:0> get 'student','zhangsan','info:sex'
COLUMN CELL
info:sex timestamp=1401938013194, value=women
1 row(s) in 0.0120 seconds
⑥全表扫描
hbase(main):085:0> scan 'student'
ROW COLUMN+CELL
zhangsan column=address:city, timestamp=1401937717401, value=bj
zhangsan column=address:contry, timestamp=1401937730454, value=cn
zhangsan column=address:provinc, timestamp=1401937746616, value=bj
zhangsan column=info:age, timestamp=1401937660360, value=23
zhangsan column=info:birthday, timestamp=1401937675146, value=90
zhangsan column=info:sex, timestamp=1401938013194, value=women
1 row(s) in 0.0820 seconds
⑦删除ID为张三的,’info:age’字段的值
hbase(main):095:0> delete 'student' , 'zhangsan' , 'info:age'
0 row(s) in 0.0180 seconds
hbase(main):096:0> get 'student' , 'zhangsan'
COLUMN CELL
address:city timestamp=1401937717401, value=bj
address:contry timestamp=1401937730454, value=cn
address:provinc timestamp=1401937746616, value=bj
info:birthday timestamp=1401937675146, value=90
info:sex timestamp=1401938013194, value=women
5 row(s) in 0.0180 seconds
⑧查询表中有多少行
hbase(main):114:0> count 'student'
1 row(s) in 0.0260 seconds
⑨清空整张表
hbase(main):129:0> truncate 'student'
Truncating 'student' table (it may take a while):
- Disabling table...
- Dropping table...
- Creating table...
0 row(s) in 4.4990 seconds
您也可以将你的hbase命令写到一个文件里边,然后执行hbase shell test.sh
即可。
①架构图
图中可以看出,HBase的核心有HMaster ,HregionServer,Hlog,HRegion等。而Hbase外部依赖zookeeper和HMaster。
1)HMaster(类似于Hadoop中的Namenode,Mapreduce中的jobtracker)是用来管理HRegionServer的。它负责监控集群中HRegionServer的状态信息变化。它主要功能点如下:
1.管理HRegionServer的负载均衡,调整Region的分布。这个通过HMaster的后台进程LoadBalancer来完成。LoadBalancer会定期将Region进行移动,以使各个HRegionServer达到Load均衡。
2.在Region Split后,负责新Region的分配。
3.HRegionServer的FailOver处理,当一个HRegionServer宕机之后,Hmaster负责将它的HRegion进行转移。
4.CataLogJanitor。它会定期清理和检查.Meta.表
一个HBase集群中可以有多个HMaster。不过Zookeeper的选举制保证只有一个Hmaster运行。当一个HMaster出问题后,其他的HMaster将启动代替。
2)从结构图中可以看出,HBase客户端只与zookeeper和HRegion Server打交道。并不和HMaster打交道。如果HMaster出问题,短时间内HBase是可以对外提供服务的,但是,因为HMaster掌握HRegionServer的的一些功能,例如:HRegionServer的FailOver操作,所以长时间未回复正常,将影响Hbase对外提供服务的准确度。
3)Hbase有2个CateLog表:-Root- 和.Meta.。-Root-表中存储了.Meta.表的位置。即.Meta.表的Region Server。.Meta.表存储所有的Region位置和每个Region所包含的Rowkey范围。-Root-表存储位置记录在Zookeeper中,表.Meta.的存储位置记录在-Root-表中。
4)当客户端发起一个请求之后流程是什么样的呢?
首先客户端会连接上Zookeeper集群,获取-Root-表存放的在哪一个HRegionServer上,找到HRegionServer后就能根据-Root-表中存放的.Meta.表的位置。客户端根据.Meta.表存储的HRegion位置到相应的HRegionServer中取对应的HRegion的数据信息。经过一次查询以后,访问CataLog表的过程将被缓存起来,下次客户端就可以直接访问HRegion获取数据信息了。
5)Hbase集成了HDFS,最终数据都会通过HDFS的API将数据持久化到HDFS中。
6)一个HBase集群拥有多个HRegionServer,(参考HDFS中的DataNode ,MapReduce中的TaskTracker),由一个HMaster来管理。每个HRegionServer拥有一个WAL(write Ahead Log,日志文件,用作数据恢复)和多个HRegion(可以简单理解为存储为一个表中的某些行)。一个HRegion拥有多个Store(存储一个ColumnFamily列簇)。一个Store又由一个MemStore(持有对该store的所有更改,在内存中)和0到多个StoreFiles(Hfile,数据存储的地方)组成。示意图如下:
行标记,类似于传统数据库表中的行号。RowKeys具有不变性。除非该行被删除或者被重新插入了新的数据。Hbase中支持基于RowKey的单行查询和范围扫描。在Hbase的Auto-Sharding中,也是基于RowKey进行自动切分的。
HBase中基本单元就是列。而列簇是由一个或多个列组成。使用时,一般讲性质差不多的放在一个列簇。因为Hbase是面向列存储的,也就是说一个列簇的所有列是存储在一起的。即上图中一个Store存储一个列簇。
注意一个表中被限定不能超过10个列簇。
HBase支持时间戳的概念。即允许一个Cell存储多个版本值。版本之间通过时间戳来划分。就是说某一列的某一行存在多个值。一般默认是3,最近的版本存在最上面。HBase中有一个TTL(Time to Live)的配置,这是基于列簇维度的,一旦过期,列簇就会自动删除所有行。
HRegionServer是负责服务和管理Region的。类似于我们所说的主从服务器,HMaster就是主服务器,HRegionServer就是从服务器。用户执行CRUD的时候,需要HRegionServer来定位到HRegin来操作。
WAL的全名是Write Ahead Log,类似于Mysql的Binary Log,WAL记录了HRegionServer上的所有的数据变更。一旦这个HRegionServer宕机,导致数据丢失后,WAL就起作用了。平时WAL是不起作用的,只是为了不可预知的错误预备的。
WAL的实现类是HLog。因为在一个HRegionServer中只有一个WAL所以对于一个HRegionServer的所有的HRegion来说WAL是全局的,共享的。当HRegion的实例创建的时候,在HRegionServer实例中的HLog就会作为HRegion的构造函数的参数传递给Hregion。当HRegion接收到一个变更的时候,HRegion就可以直接通过HLog将变更日志追加到共享的WAL中。当然基于性能考虑,HBase还提供了一个setWriteToWAL(false)方法。一旦用户调用该方法,变更日志将不在记录到WAl中。
HLog还有一个重要的特性就是:跟踪变更。在HLog中有一个原子类型的变量,HLog会读取StoreFiles中最大的sequence number(HLog中每一条变更日志都有一个number号,因为对于一个HRegionServer中所有的HRegion都是共享HLog的,所以变更日志会顺序写入WAL,StoreFile中也持有该number),并存放到变量中。这样HLog就知道已经存储到哪个位置了。
WAL还有2个比较重要的类,一个是LogSyncer,另外一个是LogRoller。
在创建表时,有一个参数设置:Deferred Log Flush,默认是false,表示log一旦更新就立即同步到filesystem。如果设置为true,则HRegionServer会缓存那些变更,并由后台任务LogSyncer定时将变更信息同步到filesystem。
2、WAL是有容量限制的,LogRoller是一个后台线程,会定时滚动logfile,用户可以设定这个间隔时间(hbase.regionserver.logroll.period,默认是一小时)。当检查到某个logfile文件中的所有sequence number均小于那个最大的sequence number时,就会将此logfile移到.oldLog目录。
如下是WAL的文件结构,目前WAL采用的是Hadoop的SequenceFile,其存储记录格式是key/value键值对的形式。其中Key保存了HLogkey的实例,HLogKey包含数据所属的表名及RegionName,timeStamp,sequenceNumber等信息。Value保存了WALEdit实例,WALEdit包含客户端每一次发来的变更信息。
在HBase中实现可扩展性和负载均衡的基本单元式Region。Region存储着连续的RowKey数据。刚开始一个表只有一个Region,随着数据的增多,达到某个阀值时就会根据RowKey自动一分为二,每个Region存储着【StartKey,endKey】。随着表的继续增大,那么当前的Region还会继续分裂,每个Region只会由一个HRegionServer服务。这就是所谓的Hbase的AutoSharding特性。当然,Region除了会spilt外,也可能进行合并以减少Region数目(这就是Hbase的compaction特性)
Store是核心存储单元。在一个HRegion中可能存在多个ColumnFamily,那么Store中被指定只能存储一个ColumnFamily。不同的ColumnFamily存储在不同的Store中(所以在创建ColumnFamily时,尽量将经常需要一起访问的列放到一个ColumnFamily中,这样可以减少访问Store的数目)。一个Store由一个MemStore和0至多个StoreFile组成
Hbase在将数据写入StoreFile之前,会先将数据写入MemStore中。MemStore是一个有序的内存缓冲器。当MemStore中数据达到阀值(Flush Size)的时候,HRegionServer就将执行Flush操作,将MemStore中的数据flush到StoreFile中。
当MemStore正在向StoreFile中flush数据的时候,MemStore还是可以向外提供读写数据服务的。这个事通过MesStore的滚动机制实现的,通过滚动MemStore,新的空的块就可以接受变更,而老的满的块就会执行flush操作。
StoreFile是HFile的实现,对HFile做了一层包装。HFile是数据真正存储的地方。HFile是基于BigTable的SSTable File和Hadoop的TFile。HFile是以keyvalue的格式存储数据的。(Hbase之前使用过Hadoop得MapFile,因为其性能上相当糟糕而放弃。)下图是HFile中版本1的格式,版本2稍有改变(详见Hbase wiki):
从上图中看出,HFile是由多个数据块组成。大部分数据块是不定长的,唯一固定长度的只有两个数据块:File Info和Trailer。DataIndex和MetaIndex分别记录了Data块和Meta块的起始位置。每个data块由一些kevalue键值对和Magic header组成。Data块的大小可以再创建表时通过HColumnDescriptor设定。Magic记录了一串随机的数字,防治数据丢失和损坏。
如果用户想绕过Hbase直接访问HFile时,比如检查HFile的健康状态,dump HFile的内容,可以通过HFile.main()方法完成。
如下图是KeyValue的格式:
KeyValue是一个数组,对byte数组做了一层包装。Key Length和Value Length都是固定长度的数值。Key包含的内容有行RowKey的长度及值,列族的长度及值,列,时间戳,key类型(Put, Delete, DeleteColumn, DeleteFamily)。
从上图可以看出,每一个keyValue只包含一列,即使对于同一行的不同列数据,会创建多个KeyValue实例。此外KeyValue不能被Split,即使此KeyValue值超过Block的大小,比如:
Block大小为16Kb,而KeyValue值有8Mb,那么KeyValue会通过相连的多个Block进行存储。
以上对Hbase的基本元素做了一个大体的介绍。下图是Hbase的存储结构图。记录了客户端发起变更或者新增操作时,Hbase内部的存储流程。
下面分析下整个存储流程
1)当客户端提交变更操作的时候,首先客户端连接Zookeeper找到-Root-表,通过-Root-提供的.Meta.表的位置找到.Meta.表,根据.Meta.中信息找到对应的Region所在的HRegionServer。数据变更信息会首先通过HRegionServer写入一个Commit log,也就是WAL。写入WAL成功之后,数据变更信息会储存到MEMStore中,当MemStore达到阀值(默认64MB)的时候,MemStore会执行flush操作,将数据持久化到HFile中。Flush过程中通过MemStore的滚动机制继续对用户提供读写服务。随着Flush操作不断进行,HFile会越来越多。当HFile超过设定数量的时候,Hbase的HouseKeeping机制通过Compaction特性将小的HFile合并成一个更大的HFile文件。在Compaction的过程中,会进行版本的合并以及数据的删除。由于storeFiles是不变的,用户执行删除操作时,并不能简单地通过删除其键值对来删除数据内容。Hbase提供了一个delete marker机制(也称为tombstone marker),会告诉HRegionServer那个指定的key已经被删除了。这样其它用户检索这个key的内容时,因为已经被标记为删除,所以也不会检索出来。在进行Compaction操作中就会丢弃这些已经打标的记录。经过多次Compaction后,HFile文件会越来越大,当达到设定的值时,会触发Split操作。将当前的Region根据RowKey对等切分成两个子Region,当期的那个Region被废弃,两个子Region会被分配到其他HRegionServer上。所以刚开始时一个表只有一个Region,随着不断的split,会产生越来越多的Region,通过HMaster的LoadBalancer调整,Region会均匀遍布到所有的HRegionServer中。
2)当HLog满时,HRegionServer就会启动LogRoller,通过执行rollWriter方法将那些所有sequence number均小于最大的那个sequence number的logfile移动到.oldLog目录中等待被删除。如果用户设置了Deferred Log Flush为true,HRegionServer会缓存有关此表的所有变更,并通过LogSyncer调用sync()方法定时将变更信息同步到filesystem。默认为false的话,一旦有变更就会立刻同步到filesystem
3)在一个HRegionServer中只有一个WAL,所有Region共享此WAL。HLog会根据Region提交变更信息的先后顺序依次顺序写入WAL中。如果用户设置了setWriteToWAL(false)方法,则有关此表的所有Region变更日志都不会写入WAL中。这也是上图中Region将变更日志写入WAL的那个垂直向下的箭头为什么是虚线的原因。
就像骑士要有一匹好马,厨师要有一套好刀,写作的人也需要花点心思研究自己的工具——以前是纸笔,现在则是软件。
写稿这件事,工具肯定不是最重要的。伟大的作家在卫生纸上也能写出好作品,而再先进的工具也没法让一个草包突然变成文豪。但必须承认的是,好的写稿工具确实能帮助你提高效率、避免意外、舒畅心情,说不定还会给你带来意想不到的灵感。
这篇文章主要面向文字记者,平时给媒体撰稿或是喜欢写写博客的朋友也可一读,对更个人化的写作,比如日记、情书可能也会带去一点点启发。
前两天,新闻实验室做了个简单的调查:你用什么软件写稿?并不意外的,在一百来个回复中,回答Word和WPS的人最多,也有一些用Mac的朋友使用Pages。
用Word当然有充足的理由,比如:
——普及率高(虽然很多都是盗版),基本上人人都打得开。之前doc格式升级成docx格式的时候,曾经造成很多麻烦,不过现在大家的Word应该都是2007之后的版本了,这个问题基本不再存在。
——习惯,从小到大用的都是这个。
——有字数统计、拼写检查(虽然效果不佳)等常用功能。
——有修订模式,虽然很不好用。一位要求匿名的记者说:“最大问题是编辑不会或是不习惯用修订模式。经常导致他删了啥改了啥我都不知道。”
但是,Word也有很多麻烦的地方:
——不够稳定,非实时存盘。几乎每个用Word的人都遇到过死机或断电导致前功尽弃的悲惨经历。好在现在有了自动保存功能,理论上至少可以找回一个比较近的版本。
——功能冗余。Word是一款很笨重的软件,而它的许多功能又是普通写作者极少用到的。
——难以同时处理多个文档。不管是写新闻还是写论文,都有千头万绪的资料来源,同时开着十个文档来写作是很常见的。但就像新闻实验室网友查非所说:用Word整理稿子好复杂,调取不方便。另一位网友Alexander陈天恩说:一旦窗口开的超过10个以上,就会容易出现软件崩溃,工作回到原点。
——没有移动版。在这个移动互联网时代,一款不能在手机上用的软件堪称废柴。你在微信上看到了一段精彩文字,想保存下来在自己的文章中引用,用Word做得到吗?
——难以协作。
——Word本身不是一款好的软件,详情可参见《 为什么 Word 必须死》。
——引用字节社创始人李如一的话:”Office已经是你电脑上唯一的盗版软件,导致心情不佳。“
还有一个重要问题是:Word的排版功能看起来挺实用,但我们真的需要排版吗?每一个拖延症患者都有这样的经历:在Word里敲了一小段字之后,就开始不断调整字体、字号、行距、段首缩进,直到一切都趋于完美,时间已经过去了两个小时。更崩溃的是,你排好的完美版面,到别人的电脑上一打开,可能就面目全非了。
本文的一项核心理念是:写作软件和排版软件是两类不同的软件。而Word是两头都占,但两头都不专业。写作软件需要舒服的视觉效果,但不需要复杂的排版方式;需要令人专注的界面,不需要太多让人分心的按钮;需要便于整理和调取材料、组织文章结构,不需要和写作无关的功能。
让写作的归写作,排版的归排版吧!以下我将根据不同的需求,推荐不同的写作软件。
如果是写千字小文,我强烈建议你用纯文本(txt)的方式写作。事实上,即便是更长、更复杂的文章,纯文本也可以驾驭——我在《南方周末》工作三年,稿件平均长度在3000字以上,绝大部分都是用纯文本写的。
纯文本的最大优势是简洁、轻便、稳定,让你完全专注于写作。你每敲一个汉字,文件就保存两个字节,不附加任何繁文缛节,想靠排版拖延时间也没办法。由于格式简单、尺寸娇小,软件基本不会突然崩溃。
对于记者来说,文本文档还有一个好处——如新闻实验室网友曾维尼所言:“可以把字拷贝直接粘贴到方正飞腾,同事有次用word文档编辑就抓狂了,‘难道我一个一个标点符号帮你改过来?!’”这个道理同样适用于写博客的人——把经过排版的Word文档粘贴进博客后台,基本上会变得乌七八糟。
当然,Windows自带的记事本过于简陋,它在自动换行等问题上的笨拙表现也令人崩溃。所以我推荐使用一些更高级的文本编辑软件。
我在Windows下写作时,使用的一直是 EmEditor。这款软件很小但功能不一般,包括写作者很需要的字数统计和非常强大的查找替换功能(实际上,它还可以用来写代码。)另外,它可以像浏览器一样实现多标签页浏览,在同一个程序窗口中同时打开许多文档,极大地方便了文档之间的文字腾挪。
如果确实需要在写作之后排版再发给其他人,可以在用纯文本写作完毕后,再粘贴进其他软件进行必要的格式调整。
如果你是深度记者,做一个题至少得十天半个月,经常要将十几万字的材料编织成几千上万字的稿件,那么你一定要尝试 Scrivener。
Scrivener是一款专门为写作长文章设计的软件。我的朋友鹤公子曾经专文介绍过,以下引用他的部分文字:
它的核心思想是把篇幅很长的文字打成片段。设想一下你在用Word写一本小说,已经写得很长很长,恐怕已经能感觉到反应迟滞了。但是在Scrivener中就不会。在Scrivener里一篇文章或者一本书,可以按部分、章节、场景分成好多层的文件夹,文件夹中则盛放实际的文本(可以是一章、一节,甚至短到一两个段落)。屏幕左边的Binder显示这些文件夹,中间的Editor是主编辑窗口,右边的Inspector可以填写这一段文字的相关信息(包括情节梗概、版本状态、注释、参考资料等)。
Scrivener还可以将你的文章完美地导出成RTF、Word、PDF以及mobi、epub等常见格式。
将长文拆解成不同的片段,或者说用一系列片段来组成一篇长文,这样的设计思路极其适合长篇稿件的写作。
此外,Scrivener还为每一个写作项目(即一篇文章或一本书)准备了专门的“资料”文件夹,方便你保存和整理采访得到的各种资料。
有传言说村上春树也用这个软件,不知真假。但可以确定的是:你可以一试,因为它提供了30天的试用,而且这里的30天不是从你安装当天开始计算的连续30天,而是你真正使用的时间。也就是说,如果你每个月使用3天,那么你可以免费用10个月。另外,虽然我不推荐,但是网上可以搜到破解程序。
如果你习惯随时为自己的写作收集素材和灵感,或者需要与他人协作,那么你应该尝试使用云端服务。最著名的此类服务包括 Evernote(印象笔记)和 有道云笔记。其实Google Docs也是很好的云端程序,当然,墙内就算了。
使用云端服务的好处包括:其一,实时在云端保存,妈妈再也不用担心停电死机或者硬盘坏掉,记者再也不用担心被人抢录音笔、夺数据卡;其二,多客户端,不管是在电脑,在手机,还是在iPad上,随时随地可以在同一个程序里收集素材和写作,搜索网页时的发现、采访时拍的照片、公交车上转瞬即逝的灵感,都可以马上收进资料库中;其三,可以多人协作,不用来来往往地发送不同版本的Word文档了。
目前这些软件的开发还不够成熟,同步时偶尔会出错。不过,移动和云端一定是越来越主流的趋势。
上文提到纯文本写作的优势时,一定有人在嘀咕:虽说写作和排版是两码事,但是一些基本的功能总是需要的吧?比如小标题突出显示一下,重要文字加个粗体什么的,这本身也是帮助写作者理清思路。这个,纯文本能做到吗?
这时,Markdown写作的优势就体现出来了。这种语言本质上还是纯文本,简单轻便,让人专注写作,但是它又通过非常简单的标记方式(比如二级标题就是在文字前面加两个#)使得作者在写作和读者在阅读时能够清晰分辨出基本的格式。而且,通过使用Markdown写作软件,可以方便地将文本输出成带格式的Word、PDF、epub、mobi等各种格式的文档。这样一来,也就不用在写完之后又再新建一个Word文档来排版了。
Markdown语言的好处还不止这些,有兴趣的朋友可以阅读这几篇文章:《 为什么文科生也该用markdown写作?》、《 为什么作家应该用 Markdown 保存自己的文稿》、《 Markdown写作浅谈》。目前口碑最好的中文Markdown写作软件是 Mou(免费)。
如果你对提高生产力不感兴趣,或者觉得不想花时间接受新事物,那么继续用Word/WPS/Pages也是还可以的选择。但如果你希望通过使用更好的工具提高自己的生产力,那么是时候抛弃Word了。写不复杂的短文,纯文本足矣,Windows自带的记事本简陋了点,EmEditor很强大;写深度报道、论文、中长篇小说,Scrivener是不可不试的神器;强调随时随地搜集资料以及与他人协作,应该用Evernote等云端服务;若是有那么一点Geek精神,则一定要领略一下Markdown语言的魅力。当然,每个人都应该根据自己的实际需求,灵活选择和组合使用以上工具。
在前几天的调查中,还有一些朋友提供了比较小众但很有价值的选择。比如,我的前同事、南方周末著名调查记者陈中小路使用的是 bean,她的推荐理由是“简洁”。网友刘修远说他喜欢Pages的淡黄色底板,而网友象罔的爱好则更特别:“chromebook,writer,因为可以设置打字机的背景音,很好听,很有写作的感觉。”
最后,有人估计想问:有没有一款写作软件能把上面的几类需求全部搞定?既有纯文本写作的简洁专注,又能像Scrivener那样可以把文章拆成片段、并方便整理大量资料,又能云端同步,支持在手机上写作,又支持Markdown语言?
好像还真有。我的朋友、“政见”团队设计师钱争予推荐了一款叫“尤利西斯”(Ulysses III)的软件,是专门为写作者精心设计的,基本能满足以上所有需求。这款软件唯一的缺点是:太贵,售价44.99美元,或283元人民币。它同样提供了试用版,不过不像Scrivener那样慷慨,只提供了10个小时的试用权限。你读到的这篇文章就是用它的试用版写的,初步试用感想是:极其好用,非常长草。我想在这里发起一项小小的“众筹”:如果你觉得这篇文章对你有些价值,或者如果你还想读到对Ulysses III的详细测评,欢迎给我的支付宝账户(wkjy1987@aliyun.com)打个五块、十块钱。如果大家的众筹金额达到了人民币100元,我会购买这款软件,并为大家撰写详尽的测评。提前谢谢各位的支持!
| 您可能也喜欢: | |||
 “我32了,还跟人合租,是不是太屌丝了?” |  访丹麦驻华大使裴德盛 |  香格里拉对话中的四位国防部长 |  我在南方周末的最后一组报道:南科大6年 |
| 无觅 | |||
知乎上有人就扁平化问题进行下面的提问:
觉得不存在误趋的说法,扁平应该也是现实场景中或从用户潜意识里存在过的东西中抽象出来的,一直觉得早期的拟物给我们用户搭建了现实与虚拟环境里很好的平 台,一个过渡和引导的过程,这样现在当扁平风来袭的时候我们的适应会很自然,现在也不存在扁平的天下,可能拟物大家见久了,会有点视觉疲倦,当看到扁平风 格出现时顿时觉得很清爽,交互点及表意都很明确,但并不代表拟物会被淘汰,根据使用场景的不同、设备的规格不同、用户的受众群体不同,拟物和扁平担当着不 同的不同的角色,并且我一直觉得现在的风格不能说只有这两种~一定还有新的设计趋势等着大家去发现,但勿忘根本,设计的根本,而不是一味地去跟风。每个图 标或设计稿后面都蕴藏着设计师自己的想法和意图,也是产品人员们辛勤付出的劳动成果。
我整理了下来自 沈振宇@知乎就此问题的回答:
我非常支持扁平化的趋势,准确地说,我认为目前的趋势是 抽象化,扁平化只是抽象化的一种典型形式。
1. 拟物化的局限
所谓拟物,必须是现实世界中已经有的物体,而且是人们日常的生活中经常使用的物品。但遗憾的是,人们生活中使 用过的东西是非常有限的,相机、指南针、时钟、收音机、录音机……我们每个人都熟识并且会使用的“设备”不超过100件,而且这仅仅是对于70后80后而 言。对于00后出生人来说,他们从出生就没见过磁带录音机,拨盘电话,收音机,红白游戏机,BP机,大哥大等这些已经被淘汰的设备,我们有理由相信,未来 我们的孩子,可能连鼠标、指南针、随身听都不会认识,因为这些设备都被一部手机所代替,甚至手机有一天也会被代替。
那么,当我们熟识的设备越来越少,而手机应用所要实现的功能越来越创新的时候,这个矛盾就出现了。应用的功能太创新,根本找不到一个现实生活中的物来拟。
所以, 拟物的风格会限制住创新应用的发展。
2. 拟物的极限
iOS6之前的版本,其实已经把拟物推到了一个非常高的高度,视觉上每一处的纹理、阴影、质感,每一个细节都经过精雕细琢,堪称完美。这个时候想要有所超越,尤其是 想要在拟物这条路上有所超越,已经非常困难。
同时,我们发现,市场上非常多相机应用都找一个相机来做拟物,音乐应用都找一个老式唱片机来拟物,所有的指南针应用打开都是一个指南针。拟物化带来高度的同质化。
更遗憾的是,由于指南针、唱片机、收音机这样的产品其实都是已经被淘汰的设备,而这些设备早已停止了创新停止了改进,是死的。但是应用是活的,要继续改进发展。假如沿着拟物化这条路走下去,10年20年50年之后,这些应用打开来还是老样子。你不觉得悲哀么?
3. 从拟物到抽象
其实我非常反对从拟物到扁平这种提法,我认为现在的趋势并不是 扁平化,而是 抽象化, 扁平只是抽象的一种视觉形式,抽象化其实有更多的可能性。
回顾历史,我们会发现从拟物到抽象是历史的必然,举文字的演变和绘画的发展作为例子:
几乎所有的文字一开始都是象形文字,用拟物的方式来描绘现实世界中的东西,但是随着人类社会的日趋复杂,越来越多抽象的概念涌现出来,人们发现无法用拟物的方式来表达,于是开始放弃拟物,采用表音的方式来记录语言。即使是汉字中,比重最大是形声字,纯粹的象形字也屈指可数。
类似的,绘画一直到摄影术发明之前都是在追求写实,极致的写实。但是摄影术发明之后,人们发现写实的绘画已经走到了尽头,已经无法再超越,唯一的方法就是另辟蹊径,用抽象的方式去绘画。于是当代的艺术,越来越抽象,彻底摆脱了现实世界的束缚。
纵观艺术史,我们都可以看出,一开始人们都努力去还原现实世界,在技法日趋完善的同时,人们开始意识到了“还原现实”的局限性,而开始冲破现实的束缚,走向抽象。
即使现在,仍然有相当多的普通人无法理解抽象艺术(有兴趣推荐大家去看一下MOMA艺术馆的藏品),但是已经没有哪个艺术家愿意再回到之前的艺术时代了。
类比手机的拟物化,我们有理由相信,在未来相当长的时间里,拟物化的视觉风格将仍然受到大多数普通用户的推崇,但是作为一个设计师,应该有这个高度看到抽象化的意义。
4. 拟物和极简的冲突
拟物就需要对物体的高度模拟,需要丰富的细节,于是我们需要质感、需要层次、需要阴影,这些最终都需要 通过视觉元素来实现。但实际上用户最后需要关注的只是信息本身,这些视觉元素或许在用户使用初期,是一个赏心悦目的装饰,但是久而久之,对用户来说就是一 种干扰信息,用户需要的是更简单更直接地得到他想要的信息。
再者说,接下来更多的随身设备,比如google glass,iWatch,都需要将交互过程进一步简化,如果继续坚持拟物化,很难想象在iWatch这个狭小的屏幕上,如何呈现一个细节丰富的物体。
所以说, 拟物化其实和极简主义是背道而驰的。在形式追随功能的原则指导下,不得不放弃拟物,而实现功能最大化。
5. 扁平化 != iOS7
很多人因为不喜欢iOS7的视觉风格,而反对扁平化。这其实犯了一个明显的逻辑错误,iOS7只是在扁平化这个方向上做出了自己的尝试,只是一个早期版本。
实际上正在探索扁平化的,还有google,还有WP8,等等。不要把iOS7的不成熟看成是扁平化这个方向的错误。
现在我们所处的时期,正是拟物化的体系日趋完善,抽象化的体系刚刚建立的时期。拿一个初生的婴儿去和发育完全的成年人相比,显然是不公平的。
综上,我相信历史的车轮滚滚,抽象化的时代即将到来,纵使我们对拟物的时代有万般留恋,抽象化仍然不可避免。同时我们是幸运的,我们将会经历整个变革过程,我们是历史的亲历者。 哦不,我们正在创造历史 !
本文由人人都是产品经理@ 边缘整理自 知乎问答,转载请注明并保存本文链接。
(关注更多人人都是产品经理观点,参与微信互动(微信搜索“人人都是产品经理”或“woshipm”)
根据Google透明度报告显示,从上周(5月27日)开始,Google的部分服务开始被屏蔽,其中最主要的是HTTPS搜索服务和Google登录服务,所有相关的Google都受到影响,包括Google.hk和Google.com等。
此次屏蔽的方法主要屏蔽Google部分IP地址的443端口,包括google.com.hk,accounts.google.com的部分IP的443端口被封,导致部分中国用户无法访问Google搜索和Gmail,由于Google的IP地址非常多,而被屏蔽的只是其中部分IP,因此只有部分用户受到了影响。
解决的方法很简单,只要找一个未被屏蔽443端口的IP地址替代原有IP即可,设置的方法是,在hosts中设置 www.google.com、 www.google.com.hk、accounts.google.com这几个域名的IP为可用的美国Google官方IP即可。这个IP的寻找方法是,找一个PING工具,从世界各地PING目标域名,然后从里面的IP地址寻找可用IP地址即可。
2014年3月,Google开始对中国的默认搜索启用https加密搜索,因此,只有通过屏蔽对Google的直接访问,才能阻止这种搜索。而现在,这样的情况已经发生了。
随着Google在中国市场份额的逐步下降,“全面屏蔽Google”已经变得越来越有可能,Google无法访问的时间也将变得越来越长,直到未来永久无法访问。
教您解除屏蔽: 添加 hosts
209.116.186.251 www.google.com 209.116.186.251 www.google.com.hk 209.116.186.251 accounts.google.com
也可以直接访问以下地址
http://203.208.48.153/search?q=G%2B&hl=zh-CN
前言:cacti监控mysql服务器的大概50张graphs都弄出来了,也出图了,其中遇到一些问题,印象比较深刻的记录如下:
(一):添加io监控

点击Create Graphs for this Host 进去创建IO的图,结果报错 
This data query returned 0 rows, perhaps there was a problem executing this data query. You can run this data query in debug mode to get more information.
进入 *Turn On Graph Debug Mode模式,报错如下:
RRDTool Command:
/usr/bin/rrdtool graph - \
--imgformat=PNG \
--start=-86400 \
--end=-300 \
--title='db-m2-slave-1 - Traffic' \
--rigid \
--base=1000 \
--height=120 \
--width=500 \
--alt-autoscale-max \
--lower-limit='0' \
--vertical-label='bits per second' \
--slope-mode \
--font TITLE:10: \
--font AXIS:7: \
--font LEGEND:8: \
--font UNIT:7: \
CDEF:cdefa='a,8,*' \
AREA:cdefa#00CF00FF:'Inbound' \
GPRINT:cdefa:LAST:' Current\:%8.2lf %s' \
GPRINT:cdefa:AVERAGE:'Average\:%8.2lf %s' \
GPRINT:cdefa:MAX:'Maximum\:%8.2lf %s\n' \
LINE1:cdefa#002A97FF:'Outbound' \
GPRINT:cdefa:LAST:'Current\:%8.2lf %s' \
GPRINT:cdefa:AVERAGE:'Average\:%8.2lf %s' \
GPRINT:cdefa:MAX:'Maximum\:%8.2lf %s\n'
RRDTool Says:
ERROR: invalid rpn expression in: a,8,*,如下图所示

编辑linux主机下的/etc/snmp/snmpd.conf文件
找到:com2sec notConfigUser default public
修改成:com2sec notConfigUser all public
找到:access notConfigGroup "" any noauth exact systemview none none
修改成:access notConfigGroup "" any noauth exact all none none
找到:#view all included .1 80把该行的#去掉,
找到:#view mib2 included .iso.org.dod.internet.mgmt.mib-2 fc 把改行的#去掉,
重起snmpd:/etc/init.d/snmpd restart
(二): MySQL添加主机出不来图
[root@squid-2 test]# service httpd restart
停止 httpd: [确定]
正在启动 httpd:httpd: Could not reliably determine the server's fully qualified domain name, using 127.0.0.1 for ServerName
[确定]
1) 进入配置文件目录
cd /etc/httpd/conf/
2)编辑httpd.conf文件,搜索"#ServerName",添加ServerName localhost:80
[root@server conf]# ls
extra httpd.conf magic mime.types original
[root@server conf]# vi httpd.conf
#ServerName www.example.com:80
ServerName localhost:80
3)再重新启动apache 即可。
(三):启动报错
[root@squid-2 error]# tail -f /var/log/httpd/error_log
[Sat May 31 22:49:02 2014] [notice] caught SIGTERM, shutting down
[Sat May 31 22:49:02 2014] [notice] SELinux policy enabled; httpd running as context unconfined_u:system_r:httpd_t:s0
[Sat May 31 22:49:02 2014] [notice] suEXEC mechanism enabled (wrapper: /usr/sbin/suexec)
[Sat May 31 22:49:02 2014] [notice] Digest: generating secret for digest authentication ...
[Sat May 31 22:49:02 2014] [notice] Digest: done
[Sat May 31 22:49:02 2014] [notice] Apache/2.2.15 (Unix) DAV/2 PHP/5.3.3 configured -- resuming normal operations
解决方法:直接关闭SELinux以及防火墙
(四):MySQL监控项出图报错
[Sat May 31 23:20:10 2014] [error] [client 192.168.171.71] PHP Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 523800 bytes) in /var/www/html/cacti/lib/adodb/adodb.inc.php on line 833
需要导入cacti.sql文件
mysql -u root -p cacti < /var/www/html/cacti/cacti.sql
(五):SNMP – Interface Statistics报错
创建SNMP – Interface Statistics报错,如下:
Created graph: db-m2-slave-2 - Traffic - |query_ifName|
ERROR: no Data Source associated. Check Template
[root@squid-2 html]# snmpwalk -c public -v 2c 10.254.3.73 ifHCInOctets
IF-MIB::ifHCInOctets = No more variables left in this MIB View (It is past the end of the MIB tree)
[root@squid-2 html]#
[root@squid-2 html]# snmpwalk -c public -v 2c 10.254.3.73 if
IF-MIB::ifTable = No Such Object available on this agent at this OID
于是再次修改snmpd.conf,并重启snmpd
access notConfigGroup "" any noauth exact systemview none none-->
access notConfigGroup "" any noauth exact all none none
[root@db-m2-slave-2 ~]# service snmpd restart
停止 snmpd: [确定]
正在启动 snmpd: [确定]
[root@db-m2-slave-2 ~]#
[root@squid-2 html]# snmpwalk -c public -v 2c 10.254.3.73 if
IF-MIB::ifTable = No more variables left in this MIB View (It is past the end of the MIB tree)
【】解决
在snmpd.conf配置文件里面,查找以下字段:[/color]
## incl/excl subtree mask
#view all included .1 80
将该行前面的"#"去掉.
之后重启snmpd服务解决。
报错(六):
移除出错的图


进去Consoleà Graph Management àHost(选择出错的主机地址)—>Search(搜索报错的关键字Used Space),就会找到报错不出错的Graph Title栏目,勾选右侧的全选框,点击 Go按钮删除掉这些无效的图即可,如下图所示:

然后在新出来的提示界面,点击 Continue按钮,删除。

(七):Memory Free值为nan

分析:memery free 无数据,原因: rrdtool 的内存上限为10G。
[root@squid-2 local]# find / -name *mem*.rrd
/var/www/html/cacti/rra/db-m2-slave-1_mem_buffers_189.rrd
/var/www/html/cacti/rra/db-master-2_mem_free_156.rrd
/var/www/html/cacti/rra/db-m2-slave-1_lock_system_memory_20.rrd
/var/www/html/cacti/rra/db-m2-slave-2_total_mem_alloc_74.rrd
/var/www/html/cacti/rra/db-m2-slave-1_total_mem_alloc_23.rrd
/var/www/html/cacti/rra/db-m2-slave-2_lock_system_memory_71.rrd
/var/www/html/cacti/rra/localhost_mem_swap_4.rrd
/var/www/html/cacti/rra/db-master-2_total_mem_alloc_117.rrd
/var/www/html/cacti/rra/db-master-2_mem_cache_155.rrd
/var/www/html/cacti/rra/db-master-2_mem_buffers_154.rrd
/var/www/html/cacti/rra/db-m2-slave-1_mem_free_191.rrd
/var/www/html/cacti/rra/localhost_mem_buffers_3.rrd
/var/www/html/cacti/rra/db-m2-slave-2_mem_free_164.rrd
/var/www/html/cacti/rra/db-m2-slave-2_mem_buffers_162.rrd
/var/www/html/cacti/rra/db-m2-slave-1_mem_buffers_54.rrd
/var/www/html/cacti/rra/db-m2-slave-1_mem_swap_55.rrd
/var/www/html/cacti/rra/db-master-2_lock_system_memory_114.rrd
/var/www/html/cacti/rra/db-m2-slave-2_mem_cache_163.rrd
/var/www/html/cacti/rra/db-m2-slave-1_mem_cache_190.rrd
/var/www/html/cacti/rra/db-master-2_mem_free_146.rrd
[root@squid-2 local]#
[root@squid-2 local]# rrdtool info /var/www/html/cacti/rra/db-m2-slave-1_mem_free_191.rrd |grep mem_free
filename = "/var/www/html/cacti/rra/db-m2-slave-1_mem_free_191.rrd"
ds[mem_free].type = "GAUGE"
ds[mem_free].minimal_heartbeat = 120
ds[mem_free].min = 0.0000000000e+00
ds[mem_free].max = 1.0000000000e+07
ds[mem_free].last_ds = "34166500"
ds[mem_free].value = NaN
ds[mem_free].unknown_sec = 2
[root@squid-2 local]#
注:ds[mem_free].max = 1.0000000000e+07 数据的最大值设置为10G
查看rrdtool如何进行修改,执行—help查看:
[root@squid-2 local]# rrdtool --help
RRDtool 1.3.8 Copyright 1997-2009 by Tobias Oetiker <tobi@oetiker.ch>
Compiled Aug 21 2010 10:57:18
Usage: rrdtool [options] command command_options
Valid commands: create, update, updatev, graph, graphv, dump, restore,
last, lastupdate, first, info, fetch, tune,
resize, xport
RRDtool is distributed under the Terms of the GNU General
Public License Version 2. (www.gnu.org/copyleft/gpl.html)
For more information read the RRD manpages
[root@squid-2 local]#
采用tune命令参数进行修改:
[root@squid-2 rra]# rrdtool tune *_mem_free_*.rrd mem_free:100000000
DS[mem_free] typ: GAUGE hbt: 120 min: 0.0000 max: 10000000.0000
[root@squid-2 rra]#
有提示信息,表名tune失败,原来少了个-a参数,重新修改如下:
[root@squid-2 rra]# rrdtool tune *_mem_cache_*.rrd -a mem_cache:3000000000
[root@squid-2 rra]# rrdtool tune *_mem_free_*.rrd -a mem_free:3000000000
[root@squid-2 rra]# rrdtool tune *_mem_buffers_*.rrd -a mem_buffers:3000000000
[root@squid-2 rra]#
这里发现rrdtool执行之后,只有一个host主机的的nan变成数字,其他主机的都没有变, 之所以如此是因为rrdtool tune * -a …命令只有一个.rrd文件起作用,其余的需要自己手动再一次次执行rrdtool tune命令。
为了简化操作,特意写了一个ssh脚本如下:
vim /root/rrdtool_increate_mem.sh cd /var/www/html/cacti/rra ls *_mem_free_*.rrd -1 >a_mem_free.txt for i in `cat a_mem_free.txt` do rrdtool tune $i -a mem_free:300000000; done; ls *_mem_cache_*.rrd -1 >a_mem_cache.txt for i in `cat a_mem_cache.txt` do rrdtool tune $i -a mem_cache:300000000; done; ls *_mem_buffers_*.rrd -1 >a_mem_buffers.txt for i in `cat a_mem_buffers.txt` do rrdtool tune $i -a mem_buffers:300000000; done;
直接sh /root/rrdtool_increate_mem.sh即可。
【补充】
调试cacti的graph,步骤如下:
(1) Console ,再进入Graph Manager ,再进入,选择对于的Host,搜索Memory,选中你要的图,点击链接,比如我这里是Memory Usage,如下图所示:

(2) 再 点击Memory Usage链接进去,点击右上角的Debug模式:

(3) 就会看到如下的debug界面,可以慢慢来观察RRDTool Command命令,为何是-nan值。

(八):双网卡 Traffic 网卡流量问题
如下图,em1和em2全部指向一个ip地址,只是em1不生效,em2生效了,但是ip地址在em1上,没有显示在em2一栏。

所以,在graph图上,就没有数据,全为-nan-值,如下所示:

在cacti服务器上面执行check:
[root@squid-2 rra]# snmpwalk -v 2c -c public 10.254.3.72 IF-MIB::ifDescr
IF-MIB::ifDescr.1 = STRING: lo
IF-MIB::ifDescr.2 = STRING: em1
IF-MIB::ifDescr.3 = STRING: em2
IF-MIB::ifDescr.4 = STRING: em3
IF-MIB::ifDescr.5 = STRING: em4
[root@squid-2 rra]#
确实有4个网卡信息记录,这些都没事,正常,经过仔细排查发现主要原因在下拉选框里面要选择Interface – Traffic (bits/sec),不要选择Interface – Traffic (bytes/sec),如下图所示:

当选择了Interface – Traffic (bits/sec)之后graph就会出数据,有效果图了。

(九):InnoDB Active/Locked Transactions
RRDTool Says:
ERROR: opening '/var/www/html/cacti/rra/db-m1-slave-1_locked_transactions_215.rrd': No such file or directory
原因是mysql服务器上的让cacti访问的mysql数据库账号没有创建,创建mysql账号好,问题解决。
(十):Tomcat - Connection Rate
RRDTool Says:
ERROR: invalid y-grid format
依次进入Console -->Graph templates->Tomcat - Connection Rate->Unit Grid Value (--unit/--y-grid)
默认的值为1 改成为0即可。
Radware发布的2014年春季电商页面速度与Web性能”调查报告强调了电商页面加载速度的重要性,同时指出很多网站都没有利用最佳的页面优化技术,页面加速速度都存在很大缺陷。那么该如何补救,提高网站页面的加载速度呢?
报告给出了12个页面加载速度优化的补救措施,用以改善加载时间,改善站长浏览者的用户体验。网站运营人员可以通过这些建议来解决页面加载速度难题。编译如下:

1、合并Js文件和CSS
将JS代码和CSS样式分别合并到一个共享的文件,这样不仅能简化代码,而且在执行JS文件的时候,如果JS文件比较多,就需要进行多次“Get”请求,延长加载速度,将JS文件合并在一起后,自然就减少了Get请求次数,提高了加载速度。
2、Sprites图片技术
Spriting是一种网页图片应用处理方式,它是将一个页面涉及到的所有零星图片都包含到一张大图中去,然后利用CSS技术展现出来。这样一来, 当访问该页面时,载入的图片就不会像以前那样一幅一幅地慢慢显示出来了,可以减少了整个网页的图片大小,并且利用CSSSprites能很好地减少网页的 http请求,从而大大的提高页面的性能。CSSSprites在国内很多人叫css精灵,很早就有了,在很多大型网站都有用到,特别是一些所有页面都存 在的图标用得比较多,很好的提升加载速度。
3、压缩文本和图片
压缩技术如gzip可以有效减少页面加载的时间。包括HTML,XML,JSON(JavaScript对象符号),JavaScript和CSS 等,压缩率都可以在大小70%左右。文本压缩用得比较多,一般直接在空间开启就行,而图片的压缩就比较随意,很多都是直接上传,其实还有很大的压缩空间。
4、延迟显示可见区域外的内容
为了确保用户可以更快地看见可见区域的网页可以延迟加载或展现可见区域外的内容,为了避免页面变形,可以使用占位符标签制定正确的高度和宽度。比如 WP的jQueryImage LazyLoad插件就可以在用户停留在第一屏的时候,不加载任何第一屏以下的图片信息,只有当用户把鼠标往下滚动的时候,这些图片才开始加载。这样很明 显提升可见区域的加载速度,提高用户体验。
5、确保功能图片优先加载
网站主要考虑可用性的重要性,一个功能按钮要提前加载出来,用户进入下载页,一个只需要8s时间的下载花了5s在等待、寻找下载按钮图片,谁能忍受?
6、重新布置Call-to-Action按钮
其实这个和上面一条是差不多的,都是从用户体验速度着手,跳过了网页的整体加载速度。速度没变,只是让一些行为按钮提前,Call-to- Action按钮一般习惯设计在页面底部,这样的习惯对于用户来说并不总是好的,购买用户需要等到最下面加载出来才能点击下一步操作。可以调整CTA按钮 的位置或使用滑动的图片按钮。很多大型购物网站的加入购物车就是这种类型。
7、图片格式优化
不恰当的图像格式是一种极为常见的减慢加载速度的罪魁祸首。正确的图片格式可以让图片缩小数倍,如果保存为最佳格式。可以节省大量带宽,减少处理时间时间,大大加快页面加载速度,这是一种很常见的做法。
8、使用 Progressive JPEGs
ProgressiveJPEGs图片是JPEG格式的一个特殊变种,名为“高级JPEG”。在创建高级JPEG文件时,数据是这样安排的:在装入 图像时,开始只显示一个模糊的图像,随着数据的装入,图像逐步变得清晰。它相当于交织的GIF格式的图片。高级JPEG主要是考虑到使用调制解调器的慢速 网络而设计的,快速网络的使用者通常不会体会到它和正常JPEG格式图片的区别。对于网速比较慢的用户,这无疑有很好的体验。
9、精简代码
这个可以说是最直接的一个方法,也是用得比较多的,对网页代码进行瘦身,删除不必要的沉冗代码,比如不必要的空格、换行符、注释等,包括JS代码中的无用代码也需要清除。其中对于注释代码的清除可能有些人存在误区,甚至有的在里面堆砌关键词。
10、延迟加载和执行非必要脚本
网页中有很多脚本是在页面完全加载完前都不需要执行的,可以延迟加载和执行非必要脚本。这些脚本可以在onload事件之后执行,避免对网页上重要 内容的呈现造成影响。这些脚本可能是你自己网页的甲苯,往往更多的是一些第三方脚本,这样的有很多,比如评论、广告、智能推荐、百度云图、分享等等,这些 完全可以等主体内容加载完后再执行。
11、使用AJAX
AJAX即“Asynchronous Javascript +XML“,是指一种创建交互式网页应用的网页开发技术。通过在后台与服务器进行少量数据交换,AJAX可以使网页实现异步更新。这意味着可以在不重新加 载整个网页的情况下,对网页的某部分进行更新。传统的网页(不使用AJAX)如果需要更新内容,必须重载整个网页面。
12、自动化的页面性能优化
自动化的页面性能优化也就是借助工具了,网站提速工具有很多,这里Radware推荐了自家的RadwareFastView,也算Radware给自家做了一个广告,这里不多说了。
以上就是Radware给出的12个页面加载速度优化建议,加入了个人的一些建议。
Google的盈利模式非常简单,搜索广告业务是其主要的收入来源,这方面的利润占了其全部利润的95%。Google的广告业务产品包括Google自己的Adwords, Adsense和收购的Admob、DoubleClick等。其中Adwords是Google最主要的广告投放工具,它可以投放的广告媒体包括搜索网络(包括Google自身和提供给第三方的搜索服务,以及Gmail等搜索服务)、Youtube、移动App(Admob)以及Adsense广告联盟等,据说Adwords可以覆盖75%以上的互联网使用者。
然而,随着这些天中国对于Google的屏蔽,Google在华广告业务遭受到前所未有的冲击,Adwords广告收益大幅降低。
据纽约时报中文网 报道,从5月27日开始,谷歌(Google)在华的几乎所有的服务都处于无法使用的状态,除了搜索引擎遭到屏蔽之外,谷歌的邮箱(Gmail)、日历(Calendar)、翻译(Translate)、地图(Maps)、分析(Analytics)、Google Adwords和Google AdSense等产品也受到了影响。
虽然Google并没有对外公开其Adwords产品这些天的损失,但我可以对其大概的情况做一些估算,我自己在国内有投放Google Adwords广告,只针对Google搜索投放,从这些天的报表数据,就可以明显看出Google这些天来的流量变化。

从数据上看,5月27日之后Google的展示和点击就有所下降,而5月31日后Google的展示和点击次数更是猛降,降幅之大令人惊讶,直到昨天的点击次数仅为正常时段的15%,可见目前能够正常使用Google的中国用户仅为十天前的10-20%,这种流量的巨大跌幅可谓惨烈。
可以说,如果这样的情况一直持续下去的话,Google在华广告业务将遭遇全军覆没的危险,没有流量,也就没有广告商投入,这部分业务也将消失。
谷歌,这个世界流量最大的网站终于从中国消失。
在实际项目应用中经常会用到定时任务,可以通过quartz和spring的简单配置即可完成,但如果要改变任务的执行时间、频率,废弃任务等就需要改变配置甚至代码需要重启服务器,这里介绍一下如何通过quartz与spring的组合实现动态的改变定时任务的状态的一个实现。
参考文章: http://www.meiriyouke.net/?p=82
本文章适合对quartz和spring有一定了解的读者。
spring版本为3.2 quartz版本为2.2.1 如果使用了quartz2.2.1 则spring版本需3.1以上
1.
spring中引入注册bean
<bean id="schedulerFactoryBean" class="org.springframework.scheduling.quartz.SchedulerFactoryBean" />
为什么要与spring结合?
与spring结合可以使用spring统一管理quartz中任务的生命周期,使得web容器关闭时所有的任务一同关闭。如果不用spring管理可能会出现web容器关闭而任务仍在继续运行的情况,不与spring结合的话要自己控制任务在容器关闭时一起关闭。
2.创建保存计划任务信息的实体类
/**
*
* @Description: 计划任务信息
* @author snailxr
* @date 2014年4月24日 下午10:49:43
*/
public class ScheduleJob {
public static final String STATUS_RUNNING = "1";
public static final String STATUS_NOT_RUNNING = "0";
public static final String CONCURRENT_IS = "1";
public static final String CONCURRENT_NOT = "0";
private Long jobId;
private Date createTime;
private Date updateTime;
/**
* 任务名称
*/
private String jobName;
/**
* 任务分组
*/
private String jobGroup;
/**
* 任务状态 是否启动任务
*/
private String jobStatus;
/**
* cron表达式
*/
private String cronExpression;
/**
* 描述
*/
private String description;
/**
* 任务执行时调用哪个类的方法 包名+类名
*/
private String beanClass;
/**
* 任务是否有状态
*/
private String isConcurrent;
/**
* spring bean
*/
private String springId;
/**
* 任务调用的方法名
*/
private String methodName;
//get set.......
}该实体类与数据库中的表对应,在数据库中存储多个计划任务。
注意:jobName 跟 groupName的组合应该是唯一的,beanClass springId至少有一个
在项目启动时运行以下代码:
public void init() throws Exception {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
// 这里从数据库中获取任务信息数据
List<ScheduleJob> jobList = scheduleJobMapper.getAll();
for (ScheduleJob job : jobList) {
addJob(job);
}
}
/**
* 添加任务
*
* @param scheduleJob
* @throws SchedulerException
*/
public void addJob(ScheduleJob job) throws SchedulerException {
if (job == null || !ScheduleJob.STATUS_RUNNING.equals(job.getJobStatus())) {
return;
}
Scheduler scheduler = schedulerFactoryBean.getScheduler();
log.debug(scheduler + ".......................................................................................add");
TriggerKey triggerKey = TriggerKey.triggerKey(job.getJobName(), job.getJobGroup());
CronTrigger trigger = (CronTrigger) scheduler.getTrigger(triggerKey);
// 不存在,创建一个
if (null == trigger) {
Class clazz = ScheduleJob.CONCURRENT_IS.equals(job.getIsConcurrent()) ? QuartzJobFactory.class : QuartzJobFactoryDisallowConcurrentExecution.class;
JobDetail jobDetail = JobBuilder.newJob(clazz).withIdentity(job.getJobName(), job.getJobGroup()).build();
jobDetail.getJobDataMap().put("scheduleJob", job);
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(job.getCronExpression());
trigger = TriggerBuilder.newTrigger().withIdentity(job.getJobName(), job.getJobGroup()).withSchedule(scheduleBuilder).build();
scheduler.scheduleJob(jobDetail, trigger);
} else {
// Trigger已存在,那么更新相应的定时设置
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(job.getCronExpression());
// 按新的cronExpression表达式重新构建trigger
trigger = trigger.getTriggerBuilder().withIdentity(triggerKey).withSchedule(scheduleBuilder).build();
// 按新的trigger重新设置job执行
scheduler.rescheduleJob(triggerKey, trigger);
}
}
看到代码第20行根据scheduleJob类中CONCURRENT_IS来判断任务是否有状态。来给出不同的Job实现类
/**
*
* @Description: 若一个方法一次执行不完下次轮转时则等待改方法执行完后才执行下一次操作
* @author snailxr
* @date 2014年4月24日 下午5:05:47
*/
@DisallowConcurrentExecution
public class QuartzJobFactoryDisallowConcurrentExecution implements Job {
public final Logger log = Logger.getLogger(this.getClass());
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
ScheduleJob scheduleJob = (ScheduleJob) context.getMergedJobDataMap().get("scheduleJob");
TaskUtils.invokMethod(scheduleJob);
}
}
/**
*
* @Description: 计划任务执行处 无状态
* @author snailxr
* @date 2014年4月24日 下午5:05:47
*/
public class QuartzJobFactory implements Job {
public final Logger log = Logger.getLogger(this.getClass());
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
ScheduleJob scheduleJob = (ScheduleJob) context.getMergedJobDataMap().get("scheduleJob");
TaskUtils.invokMethod(scheduleJob);
}
}
真正执行计划任务的代码就在TaskUtils.invokMethod(scheduleJob)里面
通过scheduleJob的beanClass或springId通过反射或spring来获得需要执行的类,通过methodName来确定执行哪个方法
public class TaskUtils {
public final static Logger log = Logger.getLogger(TaskUtils.class);
/**
* 通过反射调用scheduleJob中定义的方法
*
* @param scheduleJob
*/
public static void invokMethod(ScheduleJob scheduleJob) {
Object object = null;
Class clazz = null;
//springId不为空先按springId查找bean
if (StringUtils.isNotBlank(scheduleJob.getSpringId())) {
object = SpringUtils.getBean(scheduleJob.getSpringId());
} else if (StringUtils.isNotBlank(scheduleJob.getBeanClass())) {
try {
clazz = Class.forName(scheduleJob.getBeanClass());
object = clazz.newInstance();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (object == null) {
log.error("任务名称 = [" + scheduleJob.getJobName() + "]---------------未启动成功,请检查是否配置正确!!!");
return;
}
clazz = object.getClass();
Method method = null;
try {
method = clazz.getDeclaredMethod(scheduleJob.getMethodName());
} catch (NoSuchMethodException e) {
log.error("任务名称 = [" + scheduleJob.getJobName() + "]---------------未启动成功,方法名设置错误!!!");
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if (method != null) {
try {
method.invoke(object);
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}对任务的暂停,删除,修改等操作
**
* 获取所有计划中的任务列表
*
* @return
* @throws SchedulerException
*/
public List<ScheduleJob> getAllJob() throws SchedulerException {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
GroupMatcher<JobKey> matcher = GroupMatcher.anyJobGroup();
Set<JobKey> jobKeys = scheduler.getJobKeys(matcher);
List<ScheduleJob> jobList = new ArrayList<ScheduleJob>();
for (JobKey jobKey : jobKeys) {
List<? extends Trigger> triggers = scheduler.getTriggersOfJob(jobKey);
for (Trigger trigger : triggers) {
ScheduleJob job = new ScheduleJob();
job.setJobName(jobKey.getName());
job.setJobGroup(jobKey.getGroup());
job.setDescription("触发器:" + trigger.getKey());
Trigger.TriggerState triggerState = scheduler.getTriggerState(trigger.getKey());
job.setJobStatus(triggerState.name());
if (trigger instanceof CronTrigger) {
CronTrigger cronTrigger = (CronTrigger) trigger;
String cronExpression = cronTrigger.getCronExpression();
job.setCronExpression(cronExpression);
}
jobList.add(job);
}
}
return jobList;
}
/**
* 所有正在运行的job
*
* @return
* @throws SchedulerException
*/
public List<ScheduleJob> getRunningJob() throws SchedulerException {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
List<JobExecutionContext> executingJobs = scheduler.getCurrentlyExecutingJobs();
List<ScheduleJob> jobList = new ArrayList<ScheduleJob>(executingJobs.size());
for (JobExecutionContext executingJob : executingJobs) {
ScheduleJob job = new ScheduleJob();
JobDetail jobDetail = executingJob.getJobDetail();
JobKey jobKey = jobDetail.getKey();
Trigger trigger = executingJob.getTrigger();
job.setJobName(jobKey.getName());
job.setJobGroup(jobKey.getGroup());
job.setDescription("触发器:" + trigger.getKey());
Trigger.TriggerState triggerState = scheduler.getTriggerState(trigger.getKey());
job.setJobStatus(triggerState.name());
if (trigger instanceof CronTrigger) {
CronTrigger cronTrigger = (CronTrigger) trigger;
String cronExpression = cronTrigger.getCronExpression();
job.setCronExpression(cronExpression);
}
jobList.add(job);
}
return jobList;
}
/**
* 暂停一个job
*
* @param scheduleJob
* @throws SchedulerException
*/
public void pauseJob(ScheduleJob scheduleJob) throws SchedulerException {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
JobKey jobKey = JobKey.jobKey(scheduleJob.getJobName(), scheduleJob.getJobGroup());
scheduler.pauseJob(jobKey);
}
/**
* 恢复一个job
*
* @param scheduleJob
* @throws SchedulerException
*/
public void resumeJob(ScheduleJob scheduleJob) throws SchedulerException {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
JobKey jobKey = JobKey.jobKey(scheduleJob.getJobName(), scheduleJob.getJobGroup());
scheduler.resumeJob(jobKey);
}
/**
* 删除一个job
*
* @param scheduleJob
* @throws SchedulerException
*/
public void deleteJob(ScheduleJob scheduleJob) throws SchedulerException {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
JobKey jobKey = JobKey.jobKey(scheduleJob.getJobName(), scheduleJob.getJobGroup());
scheduler.deleteJob(jobKey);
}
/**
* 立即执行job
*
* @param scheduleJob
* @throws SchedulerException
*/
public void runAJobNow(ScheduleJob scheduleJob) throws SchedulerException {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
JobKey jobKey = JobKey.jobKey(scheduleJob.getJobName(), scheduleJob.getJobGroup());
scheduler.triggerJob(jobKey);
}
/**
* 更新job时间表达式
*
* @param scheduleJob
* @throws SchedulerException
*/
public void updateJobCron(ScheduleJob scheduleJob) throws SchedulerException {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
TriggerKey triggerKey = TriggerKey.triggerKey(scheduleJob.getJobName(), scheduleJob.getJobGroup());
CronTrigger trigger = (CronTrigger) scheduler.getTrigger(triggerKey);
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(scheduleJob.getCronExpression());
trigger = trigger.getTriggerBuilder().withIdentity(triggerKey).withSchedule(scheduleBuilder).build();
scheduler.rescheduleJob(triggerKey, trigger);
}
小提示
更新表达式,判断表达式是否正确可用一下代码
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule("xxxxx");
抛出异常则表达式不正确
[核心提示]淘宝拥有百万家商户和超过10亿的商品数,它如何让用户精准地找到想要的商品呢?其背后有着强大的技术支撑。
淘宝目前在线商品数超过 10 亿,如何精准的帮助用户找到他想要的商品呢?经过多年的探索,淘宝通过建立一套完整的类目属性体系,终于较好的解决了这一问题,今天就跟大家一起来谈谈淘宝的类目属性体系。
2003 年淘宝刚上线时,商品量很少,没有分类。 后来,商品量上百,开始有了对商品进行单级分类,有点类似于现在的一级行业类目。
等到商品上万的时候,商品的单级分类已经不能满足需求,开始有了多级分类,就是一颗类目树了。从 06 年开始引入了属性,商家按照属性模板填写属性,用户可以按照属性筛选商品。
到了 08 年,开始将前后台类目分开,用户根据前台类目筛选商品,商家将商品挂到后台类目上,前后台类目树之间建立好映射。
今天的淘宝类目属性体系主要由后台类目树、前台类目树、挂载在后来叶子类目上的商品属性模板以及管理前后台类目之间映射关系的类目管理平台组成,整体架构如下:
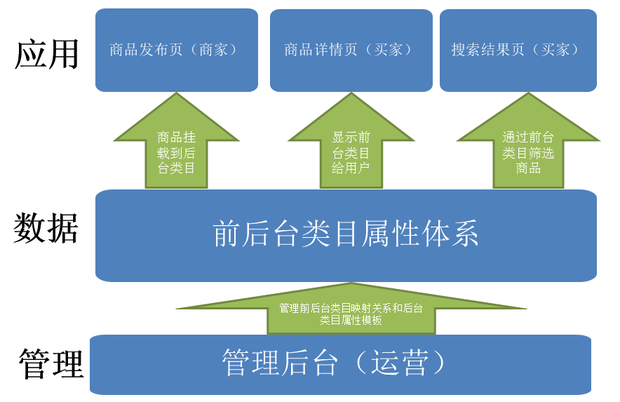
从图中可以看出,淘宝类目属性体系是一个非常基础的数据服务,在商品发布页上商家选择后台类目上传商品信息,详情页上以面包屑的方式给用户显示商品所属的前台类目,在搜索结果页上让用户根据前台类目筛选商品。运营同学可以通过一个管理后台来管理前后台类目之间的映射关系以及后台类目的属性模板。
后台类目面向商家,主要用于商品的分类和属性管理。商家上传商品时见到的就是后台类目,如下图:
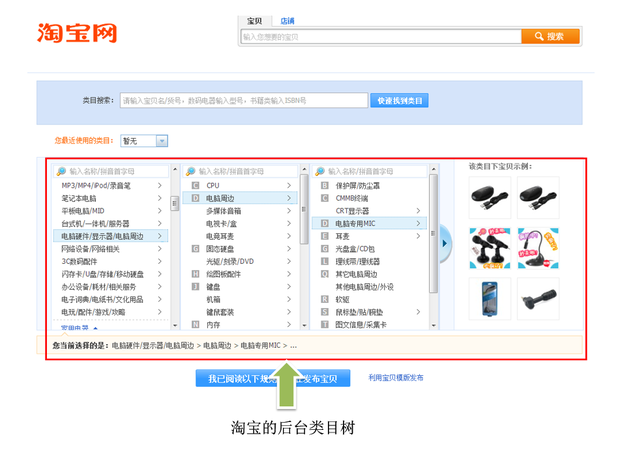
后台类目有如下特点:
前台分类面向用户,方便用户筛选查找商品,大部分时候用户见到的类目都是前台类目。下图就是淘宝搜索结果页上的淘宝前台类目树:
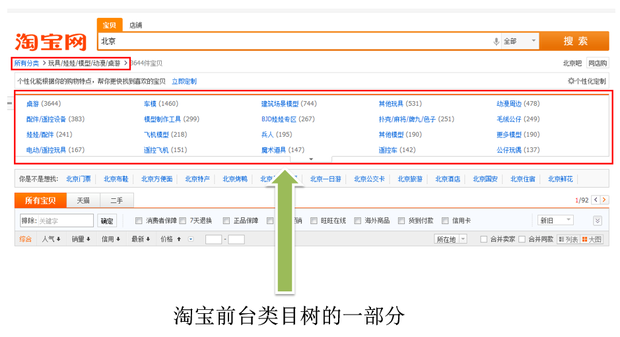
前台类目有如下特点:
介绍完淘宝的类目属性体系,或许你会问为啥要将前台类目和后台类目分开呢?直接用一套类目体系不就行了吗?这里我就给大家解释一下原因,到了 08 年,淘宝商品日益增多,类目层级也越来越深,买家越来越难找到想要的商品。淘宝的小二们就开始不断调整类目属性,把类目树变浅,让商品更容易被买家找到。只有一套类目体系的情况下,小二每次调整,卖家也必须跟着调整。如果只是改一次,卖家也能勉强接受,但这是周期性的。比如,在夏天服装这个类目下可能是连衣裙、衬衫等夏装,到了冬天就会变成打底裤、羽绒服等冬装了,而且卖家也都知道这些调整时合理的,但是一年到头这么调整,意味着他一年到头都在编辑类目,可能还得专门养个把人在那里,一天到晚改类目,无形中卖家的运营成本也就提高了。
08 年的时候,有个淘宝的产品经理从线下零售巨头沃尔玛得到启发,他发现沃尔玛仓库里面的类目分区和货架区的类目分区是分离的,仓库里面的类目分区比较稳定,很少变化,而货架区的类目分区会根据活动和季节经常调整。类似的,淘宝也可以把原来的一套类目体系分为后台分类和前台分类,后台分类面向商家,用来挂载商品和属性模板,比较稳定很少变化;前台分类面向用户,主要方便用户查找商品,很灵活,可以经常调整。后台类目和前台类目之间通过映射联系起来,一个后台类目可以映射到多个前台类目,一个前台类目也可以包含多个后台类目。
从技术的角度来看的话,前台类目就是在后台类目的基础上建立了一个虚拟类目。
先来看看类目属性体系是怎么帮助提升搜索的精准度的,下图是说明了用户 query 到商品搜索结果的全过程:
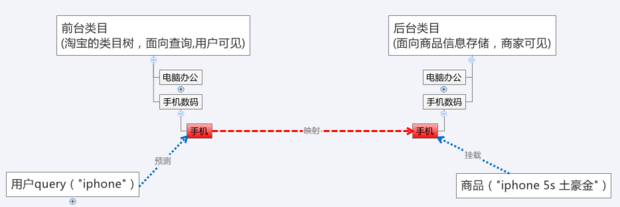
用户输入 query:iPhone,淘宝类目属性体系预测到跟这个 query 最相关的前台类目是手机,然后前台类目通过映射找到后台类目手机,最终在这个类目下找到了“iPhone 5s 土豪金”这个商品。
有了类目属性体系,用户搜索 iPhone,淘宝就不会给出手机套这样的配件了,因为它只会到手机类目下去找商品。
有了类目属性体系,用户可以直接在搜索结果页按照类目和属性筛选商品,更加高效的找到想要的商品。而淘宝搜索可以通过记录用户搜索 query 之后的类目属性筛选行为,精准预测每一个 query 的类目和属性意图,当用户再次搜索的时候,可以根据 query 的类目属性意图,在 query 文本相关性的基础上计算出商品的类目和属性相关性,把包含 query,且跟用户的类目和属性意图最相关的商品优先展示给用户。这也是百度这样的通用搜索引擎所做不到的,因为它没有类目属性体系。
有了类目属性体系,还可以做好搜索算法的垂直化优化。也就是在每一个细分类目下,可以采用不同的商家权重和品牌权重,甚至可以有不同的排序公式。比如用户选择手机时,更多考虑各项参数和评测文章,这个时候相应的排序权重因子可以加强,而选择服装的时候,一张漂亮的主图就无比重要了,排序因子里面主图质量的权重就需要提升了。 有了类目属性体系,还可以做基于类目和属性的个性化搜索。搜索引擎通过用户的类目属性筛选日志,可以挖掘出用户的一些特征,比如性别,意向价格区间,偏好品牌,偏好品类等,从而可以对这个用户做个性化的展示。
除了电商,其实在各个需要帮助快速查找信息领域都可以见到类目属性体系的身影。比如:教育行业里面的课程分类,医疗行业的疾病和医院分类。当我们把用户查找的信息看做一个个实体的时候,对实体分类以帮助快速定位查找就是一个非常通用的方法。从这个角度来讲,Google 的 Knowledge Graph 可以看做是将电商网站里面的商品类目属性体系推广到了整个世界中的万事万物,它试图使用一套统一的类目属性网来囊括所有的实体,或许这就是通用搜索引擎的类目属性体系吧。
本文为作者葛灿辉( @葛灿辉-搜索数据挖掘)投稿发布,转载请注明出处并附带本文链接
(关注更多人人都是产品经理观点,参与微信互动(微信搜索“人人都是产品经理”或“woshipm”)
天下武功无坚不破,唯快不破。在瞬息万变的移动互联网领域,创业公司要想在巨头的夹缝中求生存,仅靠一款出色的产品是不够的,高效敏捷的研发能力才是公司生存与发展的关键。高效的研发模式包括如何确定开发项目,如何把控项目进度,如何驱动产品一代代完善以及如何调动员工的积极性等。通过对豌豆荚的访谈,让我们来看看这家被称为中国最具硅谷范的移动互联网公司在做产品研发的过程中是如何进行高效管理的。
一、高效研发的5个关键步骤
第一步:立项——定方向
在豌豆荚的整个研发过程中,立项称为Product Brief或者Project Brief。团队的产品经理会撰写一个1-2页的文档,然后和执行团队进行评审,如果评审通过,立项就成功了。文档一般包含会包含以下内容:
1. 愿景:一句话表达清楚要做什么;
2. 分析市场机会和趋势,决定当前策略;
3. 确定目标用户的特征和核心需求;
4. 现存的解决方案和各自的优劣势;
5. 该项目对豌豆荚的利益点;如果不做该项目,哪些竞争对手会做,对竞争对手的利益点;
6. 需要哪些技术的支持和驱动,哪些技术是豌豆荚的弱项;
7. 人力需求;
8. 项目的紧急程度,是否需要快速推进;
9. 发布策略;
10. 核心衡量指标,用来衡量成功的指标。
第二步,OKR 体系——定目标
对一个项目来说,设定目标是非常重要的,因为这决定了如何去做,以及能做到何种程度。豌豆荚采纳的目标管理是从 Google 引进的 OKR 体系(Objectives & Key Results,目标与关键成果),这跟传统的 KPI(Key Performance Indicator,关键绩效考核)稍微有些区别:
1. OKR 首先是沟通工具:豌豆荚共有 300 多人,每个人都要写 OKR。为了便于沟通,所有这些OKR都会放在一个文档里。任何员工都可以看到 CEO 的这个季度最重要的目标是什么,HR 团队这个季度的目标是什么。
2. OKR是努力的方向和目标:OKR代表你到底要去哪里,而不是你要去的地方具体在哪里。
3. OKR必须可量化。比如健身时设定锻炼目标,如果只是定义成「我们要努力提高身体素质」,肯定不是一个好的 OKR,因为无法衡量,好的OKR是「今年的跑步时间较去年增加一倍」。
4. 目标必须一致:制定者和执行者目标一致、团队和个人的目标一致。首先,制定公司的OKR;其次,每个团队定自己的 OKR;第三,每个工程师或设计师写各自的OKR。这三步各自独立完成,然后对照协调这三者的OKR。在豌豆荚,OKR跟个人绩效没有关系,因为OKR 系统的结果和每个人并不直接挂钩。
5. 通过月度会议Review ,时时跟进OKR: 在月度会议上需要确定如何去达到目标,是一个帮助达到目标的过程。
6. 通过季度会议 Review ,及时调整OKR:互联网的变化非常快,所以豌豆荚每季度有一个OKR 的 review,调整的原则是目标(Objectives)不变,只允许调整关键成果(Key Results)。
为了更好的理解如何制定OKR体系,豌豆荚提供了以下实例:
● 目标(Objectives):发布有影响力的新功能,将 XXX 产品做成用户可以每日使用的产品。
● 关键成果(Key Results):
○ 日活跃用户量为XX;
○ 使用XX方式,提高XXX核心指标;
第三步,项目管理——控进度:
目标设定以后,非常重要的就是执行,一般的项目管理实际上就是控制进度。
1. 任务/进度勤同步。整个公司所有人的 calender,包括会议、要做的事情、项目的时间节点都需要及时同步。在整个战略布局上,如果某个项目工期非常紧,就必须进行更多的沟通,确保每一个环节都没有问题。

2. 站立会议 (Daily Sync):每天进行站立会议,一般控制在十分钟之内,每个人说明自己今天要做的工作,需要什么帮助,有谁可以帮忙,可以更有效的调节资源和攻关。
3. 多方位沟通(Google Docs / Gmail / Hangouts):对非紧急的事情,两个团队或者是两个人一起讨论所有的设计。Hangouts用于做快速响应。

4. 周会(Weekly Report):每周总结。豌豆荚的团队产品经理要做周报,汇报这周的工作、发布、取得效果以及数据。
5. 数据系统:MUCE 是豌豆荚的数据系统,上面有全公司所有的产品数据和运营数据。MUCE 的数据能够用来验证产品的假设、方向等。
第四步,人员管理——带团队:
项目是由一个个具体的人来执行的,所以带团队非常重要,在人员管理上,豌豆荚有三个基本原则:
1、Re-Organization & 换组:公司鼓励员工换组,每个人都有机会到喜爱的团队做更有趣的事情。只要在原团队的绩效合格,每季度都可申请换团队或换工作内容。员工的绩效不与 OKR 挂钩,公司鼓励员工挑战难度、超越优秀,低 Level 的事情做不到优秀会被惩罚,做事不及格也会被惩罚。
2、One on One:在带人方面, One on One 非常重要。One on One 指的是每个团队的 manager 需要定期(最佳间隔是每周一次)与自己团队中的每个成员进行一对一讨论或者对话。在豌豆荚,manager 首先是一个教练,应该帮助自己团队的成员成长。通过 One on One,manager 需要了解每个团队成员现阶段的状态和遭遇的困扰,分享职业规划,帮助他们正确地处理问题,更好地实现个人成长。
3、个人 OKR 和 Performance 体系:每个员工在每个季度初需要确定自己本季度的 OKR,在一个季度结束后需要根据自己这个季度的工作完成情况给 OKR 打分。每半年公司会进行一次 Performance Review,主要是 review 员工过去半年的绩效,并根据 Performance Review 的结果变更 Job Ladder(业务职级)和薪酬。值得一提的是,在豌豆荚,所有的个人 Performance Review 的成就内容及级别都是全公司共享公开的,如下图所示。这个对于很多公司来说是不可想象的,豌豆荚为什么要这么做?因为一方面对于豌豆荚来说可以做到更为公平和透明,另一方面也给每位豌豆提供了更好学习和成长自己的样本,激励大家在产品研发中更高质量的挑战和要求自己。
第五步,兴趣管理——排干扰:
1、激发兴趣:Hack Day,是豌豆荚一个特殊的节日,开始于2010年,类似黑客马拉松。通常在春节假期回来的那一周,产品设计师和工程师们 3-5 人组成一队,在连续48小时的时间里,充分展现工程团队的创意和想像力,完成一些比日常开发更 geek、更有趣的东西。
豌豆荚为了鼓励大家更好的完成挑战,也会设计一些特别有特色的奖品,历史上 2012 年提供的是苹果刚出 Macbook Retina,2013 年是 Google Glass,2014 年则是程序员最爱的 Herman Miller 顶级座椅。
在历史的 Hackday 中,有不少作品最终都成了重要产品对外发布,比如 MUCE、豌豆洗白白和 IAS(应用内搜索),都成为了豌豆荚极具特色的产品。

2、控制兴趣:Polish Week,让公司慢下来,对已有产品的细节进行精细化的过程。在大量开发和新产品上线的过程中,我们会担心因为走得太快而对产品的细节关注不够。在连续3个工作周后,第4周通常是 Polish Week。在 Polish Week 的这一周,豌豆荚内部不会进行新产品或新功能的开发,而主要是对现有的产品和服务进行打磨,解决一些细节问题和小 bug,譬如产品内一些字体的统一等等。平均每个 Polish Week 会解决产品中各种 Bug 大约 200 个。

二、高效研发的流程和工具
过去几年豌豆荚做 Windows 版的时候,尝试过一个月、两个月、一个星期、两个星期的发布节奏,整个模式跟 Chrome 比较像,有功能发布就希望尽早的发。我们在服务端上每天都有更新,客户端会慢一点,现在大概是两周一个版本,如下图所示:

在开发节奏上,前两周的时间用于开发,然后截取分支准备发布,接下来两周进行测试,同时进行另一个开发,每一个迭代都控制在两周之内。相对而言,服务端的发布比较好操作,可以做很多的回归测试和自动化测试,不太需要手工的测试来做发布,但是 Windows 和 Android 都会有一些 Beta 的发布,在内部很难模拟用户的使用场景和用户的环境,所以在 release 之后的过程中一般会抽样 1%、5%、10% 这样一个节奏来做验证,主要是看某些指标是否达标。
这个流程刚开始执行的时候问题特别多。比如在这周开发完成以后,测试发现根本测试不了,有很多很多的 Bug,工程师只好利用第二个研发周期去修 Bug,然后又会影响第二周期的开发,这样问题越来越多,就会导致流程很难进行,然后进入恶性循环。为了解决这个问题,首先在操作层面上一开始先用一个月的迭代来让大家适应,同时要求 Master 分支必须是可用的(比如某人提交了代码跑不起来,或者没有经过测试,给其他同事带来了阻碍,就会被要求请全团队喝咖啡)。其次加强单元测试和回归测试,确保每个迭代的研发质量是可控的,后面的测试主要是回归和校验,减轻相互重叠的压力问题。一个月的迭代跑顺了之后,再跑到两周、一周的节奏,整体来看,差不多用了半年的时间,豌豆荚就完全跑顺了这个流程,想快可以快,想慢也可以慢。
译注: Mark Lutz 是《Learning Python | 学习Python》的作者之一。
在这篇文章中,我将总结新老Python程序员常犯的一些错误,以帮助你们在自己的工作避免犯同样或类似错误。
首先我要说明一下的是,这些都是来源于第一手的经验。我以讲授Python的知识为生。在过去的7年里,我已经给上千名学生讲授上百堂Python的课程,同时看着这些学生们犯同样的错。也就是说,这些是我看着Python初学者活生生犯的错,千百次的错。事实上,这些错误实在是太普遍了以至于我敢保证你刚开始学的时候是一定会犯的。
“那么是什么呢?”你会问,“你也会在Python里犯那么多错么?”是的。Python可能是最简单、最灵活的语言之一,但它终究还是一门编程语言。它仍然有语法,数据类型,以及巫师蒂姆居住的黑暗角落。
(典故出自《蒙蒂派森与圣杯》中的魔法师蒂姆,他主角们指点在洞穴的墙壁上记录的圣杯位置,作者在此处的意思是Python语言里容易犯错的地方。另,Python语言得名于作者Guido van Rossum特别喜欢的《蒙蒂派森飞行马戏团(Monty Python’s Flying Circus)》——译者注)
好事情是多亏了Python那干净的设计,一旦你学会了Python,你就能自动的避开很多陷阱。Python在其各组件之间有着最小的互动,这能有效的减少bug。它也拥有十分简单的语法,这意味着在一开始你就有更小的概率犯错。当你实在是犯了错的时候,Python的即时错误检测和报告能帮你迅速的恢复。
但用Python编程也不是个自动完成的活儿,很多事还是要早做准备。那么废话不多说了,让我们直切正题。在接下来的三节里我们将这些错误分为语用、代码,以及编程三个大类。如果你想读到更多的Python的常见错误以及如何避免它们,那么在O’Reilly系列丛书的《Learning Python》里有详细的解读。(译注:Learning Python 已经是第五版了)
让我们从基础开始,从那些刚学习编程的人钻研语法之前碰到的事情开始。如果你已经编过一些程了,那么以下这些可能看起来十分的简单;如果你曾经尝试过教新手们怎么编程,它们可能就不这么简单了。
在>>>交互提示符中你只能输入Python代码,而不是系统命令。时常有人在这个提示符下输入emacs,ls,或者edit之类的命令,这些可不是Python代码。在Python代码中确实有办法来调用系统命令(例如os.system和os.popen),但可不是像直接输入命令这么直接。如果你想要在交互提示符中启动一个Python文件,请用import file,而不是系统命令python file.py。
因为交互解释器会自动的讲表达式的结果输出,所以你不需要交互的键入完整的print语句。这是个很棒的功能,但是记住在代码文件里,通常你只有用print语句才能看得到输出。
如果你在Windows里使用记事本来编辑代码文件的话,当你保持的时候小心选择“所有文件”(All Files)这个类型,并且明确的给你的文件加一个.py的后缀。不然的话记事本会给你的文件加一个.txt的扩展名,使得在某些启动方法中没法跑这个程序。更糟糕的是,像Word或者是写字板一类的文字处理软件还会默认的加上一些格式字符,而这些字符Python语法是不认的。所以记得,在Windows下总是选“所有文件”(All Files),并保存为纯文本,或者使用更加“编程友好”的文本编辑工具,比如IDLE。在IDLE中,记得在保存时手动加上.py的扩展名。
在Windows下,你能靠点击Python文件来启动一个Python程序,但这有时会有问题。首先,程序的输出窗口在程序结束的瞬间也就消失了,要让它不消失,你可以在文件最后加一条raw_input()的调用。另外,记住如果有错的话,输出窗口也就立即消失了。要看到你的错误信息的话,用别的方法来调用你的程序:比如从系统命令行启动,通过提示符下用import语句,或者IDLE菜单里的选项,等等。
你可以在交互提示符中通过import一个文件来运行它,但是这只会在一个会话中起一次作用;接下来的import仅仅是返回这个已经加载的模块。要想强制Python重新加载一个文件的代码,请调用函数reload(module)来达到这个目的。注意对reload请使用括号,而import不要使用括号。
在模块文件中空白行和注释统统会被忽略掉,但是在交互提示符中键入代码时,空白行表示一个复合语句的结束。换句话说,空白行告诉交互提示符你完成了一个复合语句;在你真正完成之前不要键入回车。事实上当你要开始一个新的语句时,你需要键入一个空行来结束当前的语句——交互提示符一次只运行一条语句。
一旦你开始认真写Python代码了,接下来了一堆陷阱就更加危险了——这些都是一些跨语言特性的基本代码错误,并常常困扰不细心的程序员。
这是新手程序员最容易犯的一个错误:别忘了在复合语句的起始语句(if,while, for等语句的第一行)结束的地方加上一个冒号“:”。也许你刚开始会忘掉这个,但是到了很快这就会成为一个下意识的习惯。课堂里75%的学生当天就可以记住这个。
在Python里,一个表达式中的名字在它被赋值之前是没法使用的。这是有意而为的:这样能避免一些输入失误,同时也能避免默认究竟应该是什么类型的问题(0,None,””,[],?)。记住把计数器初始化为0,列表初始化为[],以此类推。
确保把顶层的,未嵌套的代码放在最左边第一列开始。这包括在模块文件中未嵌套的代码,以及在交互提示符中未嵌套的代码。Python使用缩进的办法来区分嵌套的代码段,因此在你代码左边的空格意味着嵌套的代码块。除了缩进以外,空格通常是被忽略掉的。
在同一个代码块中避免讲tab和空格混用来缩进,除非你知道运行你的代码的系统是怎么处理tab的。否则的话,在你的编辑器里看起来是tab的缩进也许Python看起来就会被视作是一些空格。保险起见,在每个代码块中全都是用tab或者全都是用空格来缩进;用多少由你决定。
无论一个函数是否需要参数,你必须要加一对括号来调用它。即,使用function(),而不是function。Python的函数简单来说是具有特殊功能(调用)的对象,而调用是用括号来触发的。像所有的对象一样,他们也可以被赋值给变量,并且间接的使用他们:x=function:x()。
在Python的培训中,这样的错误常常在文件的操作中出现。通常会看到新手用file.close来关闭一个问题,而不是用file.close()。因为在Python中引用一个函数而不调用它是合法的,因此不使用括号的操作(file.close)无声的成功了,但是并没有关闭这个文件!
在系统的命令行里使用文件夹路径或者文件的扩展名,但不要在import语句中使用。即,使用import mod,而不是import mod.py,或者import dir/mod.py。在实际情况中,这大概是初学者常犯的第二大错误了。因为模块会有除了.py以为的其他的后缀(例如,.pyc),强制写上某个后缀不仅是不合语法的,也没有什么意义。
和系统有关的目录路径的格式是从你的模块搜索路径的设置里来的,而不是import语句。你可以在文件名里使用点来指向包的子目录(例如,import dir1.dir2.mod),但是最左边的目录必须得通过模块搜索路径能够找到,并且没有在import中没有其他路径格式。不正确的语句import mod.py被Python认为是要记在一个包,它先加载一个模块mod,然后试图通过在一个叫做mod的目录里去找到叫做py的模块,最后可能什么也找不到而报出一系列费解的错误信息。
以下是给不熟悉Python的C程序员的一些备忘贴士:
while ((x=next() != NULL))。在Python中,需要表达式的地方不能出现语句,并且赋值语句不是一个表达式。
下面终于要讲到当你用到更多的Python的功能(数据类型,函数,模块,类等等)时可能碰到的问题了。由于篇幅有限,这里尽量精简,尤其是对一些高级的概念。要想了解更多的细节,敬请阅读Learning Python, 2 nd Edition的“小贴士”以及“Gotchas”章节。
当你在Python中调用open()来访问一个外部的文件时,Python不会使用模块搜索路径来定位这个目标文件。它会使用你提供的绝对路径,或者假定这个文件是在当前工作目录中。模块搜索路径仅仅为模块加载服务的。
列表的方法是不能用在字符串上的,反之亦然。通常情况下,方法的调用是和数据类型有关的,但是内部函数通常在很多类型上都可以使用。举个例子来说,列表的reverse方法仅仅对列表有用,但是len函数对任何具有长度的对象都适用
记住你没法直接的改变一个不可变的对象(例如,元组,字符串):
T = (1, 2, 3) T[2] = 4 # 错误
用切片,联接等构建一个新的对象,并根据需求将原来变量的值赋给它。因为Python会自动回收没有用的内存,因此这没有看起来那么浪费:
T = T[:2] + (4,) # 没问题了: T 变成了 (1, 2, 4)
当你要从左到右遍历一个有序的对象的所有元素时,用简单的for循环(例如, for x in seq:)相比于基于while-或者range-的计数循环而言会更容易写,通常运行起来也更快。除非你一定需要,尽量避免在一个for循环里使用range:让Python来替你解决标号的问题。在下面的例子中三个循环结构都没有问题,但是第一个通常来说更好;在Python里,简单至上。
S = "lumberjack" for c in S: print c # 最简单 for i in range(len(S)): print S[i] # 太多了 i = 0 # 太多了 while i < len(S): print S[i]; i += 1
诸如像方法list.append()和list.sort()一类的直接改变操作会改变一个对象,但不会将它们改变的对象返回出来(它们会返回None);正确的做法是直接调用它们而不要将结果赋值。经常会看见初学者会写诸如此类的代码:
mylist = mylist.append(X)
目的是要得到append的结果,但是事实上这样做会将None赋值给mylist,而不是改变后的列表。更加特别的一个例子是想通过用排序后的键值来遍历一个字典里的各个元素,请看下面的例子:
D = {...}
for k in D.keys().sort(): print D[k]差一点儿就成功了——keys方法会创建一个keys的列表,然后用sort方法来将这个列表排序——但是因为sort方法会返回None,这个循环会失败,因为它实际上是要遍历None(这可不是一个序列)。要改正这段代码,将方法的调用分离出来,放在不同的语句中,如下:
Ks = D.keys() Ks.sort() for k in Ks: print D[k]
在Python中,一个诸如123+3.145的表达式是可以工作的——它会自动将整数型转换为浮点型,然后用浮点运算。但是下面的代码就会出错了:
S = "42" I = 1 X = S + I # 类型错误
这同样也是有意而为的,因为这是不明确的:究竟是将字符串转换为数字(进行相加)呢,还是将数字转换为字符串(进行联接)呢?在Python中,我们认为“明确比含糊好”(即,EIBTI(Explicit is better than implicit)),因此你得手动转换类型:
X = int(S) + I # 做加法: 43 X = S + str(I) # 字符串联接: "421"
尽管这在实际情况中很少见,但是如果一个对象的集合包含了到它自己的引用,这被称为 循环对象(cyclic object)。如果在一个对象中发现一个循环,Python会输出一个[…],以避免在无限循环中卡住:
>>> L = ['grail'] # 在 L中又引用L自身会 >>> L.append(L) # 在对象中创造一个循环 >>> L ['grail', [...]]
除了知道这三个点在对象中表示循环以外,这个例子也是很值得借鉴的。因为你可能无意间在你的代码中出现这样的循环的结构而导致你的代码出错。如果有必要的话,维护一个列表或者字典来表示已经访问过的对象,然后通过检查它来确认你是否碰到了循环。
这是Python的一个核心理念,有时候当行为不对时会带来错误。在下面的例子中,一个列表对象被赋给了名为L的变量,然后L又在列表M中被引用。内部改变L的话,同时也会改变M所引用的对象,因为它们俩都指向同一个对象。
>>> L = [1, 2, 3] # 共用的列表对象 >>> M = ['X', L, 'Y'] # 嵌入一个到L的引用 >>> M ['X', [1, 2, 3], 'Y']>>> L[1] = 0 # 也改变了M >>> M ['X', [1, 0, 3], 'Y']
通常情况下只有在稍大一点的程序里这就显得很重要了,而且这些共用的引用通常确实是你需要的。如果不是的话,你可以明确的给他们创建一个副本来避免共用的引用;对于列表来说,你可以通过使用一个空列表的切片来创建一个顶层的副本:
>>> L = [1, 2, 3]>>> M = ['X', L[:], 'Y'] # 嵌入一个L的副本 >>> L[1] = 0 # 仅仅改变了L,但是不影响M >>> L [1, 0, 3]>>> M ['X', [1, 2, 3], 'Y']
切片的范围起始从默认的0到被切片的序列的最大长度。如果两者都省略掉了,那么切片会抽取该序列中的所有元素,并创造一个顶层的副本(一个新的,不被公用的对象)。对于字典来说,使用字典的dict.copy()方法。
Python默认将一个函数中赋值的变量名视作是本地域的,它们存在于该函数的作用域中并且仅仅在函数运行的时候才存在。从技术上讲,Python是在编译def代码时,去静态的识别本地变量,而不是在运行时碰到赋值的时候才识别到的。如果不理解这点的话,会引起人们的误解。比如,看看下面的例子,当你在一个引用之后给一个变量赋值会怎么样:
>>> X = 99>>> def func(): ... print X # 这个时候还不存在 ... X = 88 # 在整个def中将X视作本地变量 ... >>> func( ) # 出错了!
你会得到一个“未定义变量名”的错误,但是其原因是很微妙的。当编译这则代码时,Python碰到给X赋值的语句时认为在这个函数中的任何地方X会被视作一个本地变量名。但是之后当真正运行这个函数时,执行print语句的时候,赋值语句还没有发生,这样Python便会报告一个“未定义变量名”的错误。
事实上,之前的这个例子想要做的事情是很模糊的:你是想要先输出那个全局的X,然后创建一个本地的X呢,还是说这是个程序的错误?如果你真的是想要输出这个全局的X,你需要将它在一个全局语句中声明它,或者通过包络模块的名字来引用它。
在执行def语句时,默认参数的值只被解析并保存一次,而不是每次在调用函数的时候。这通常是你想要的那样,但是因为默认值需要在每次调用时都保持同样对象,你在试图改变可变的默认值(mutable defaults)的时候可要小心了。例如,下面的函数中使用一个空的列表作为默认值,然后在之后每一次函数调用的时候改变它的值:
>>> def saver(x=[]): # 保存一个列表对象 ... x.append(1) # 并每次调用的时候 ... print x # 改变它的值 ... >>> saver([2]) # 未使用默认值 [2, 1] >>> saver() # 使用默认值 [1] >>> saver() # 每次调用都会增加! [1, 1] >>> saver() [1, 1, 1]
有的人将这个视作Python的一个特点——因为可变的默认参数在每次函数调用时保持了它们的状态,它们能提供像C语言中静态本地函数变量的类似的一些功能。但是,当你第一次碰到它时会觉得这很奇怪,并且在Python中有更加简单的办法来在不同的调用之间保存状态(比如说类)。
要摆脱这样的行为,在函数开始的地方用切片或者方法来创建默认参数的副本,或者将默认值的表达式移到函数里面;只要每次函数调用时这些值在函数里,就会每次都得到一个新的对象:
>>> def saver(x=None): ... if x is None: x = [] # 没有传入参数? ... x.append(1) # 改变新的列表 ... print x ... >>> saver([2]) # 没有使用默认值 [2, 1] >>> saver() # 这次不会变了 [1] >>> saver() [1]
下面列举了其他的一些在这里没法详述的陷阱:
作者 Mark Lutz系世界领先的Python教育者,Python最早的畅销教材的作者,并且从1992年开始便长期贡献于Python社区。
Mark Lutz:Python程序员的常见错误,首发于 博客 - 伯乐在线。
adb shell进入手机,这此参数被纪录在/system/build.prop中,如果想直接查看可以使用adb shell getprop
dalvik.vm.heapgrowthlimit dalvik.vm.heapstartsize dalvik.vm.heapsize #查看单个应用程序最大内存限制
bixiaopeng@bixiaopengtekiMacBook-Pro ~$ adb shell getprop|grep heapgrowthlimit
|[dalvik.vm.heapgrowthlimit]: [96m]
#应用启动后分配的初始内存
bixiaopeng@bixiaopengtekiMacBook-Pro ~$ adb shell getprop|grep dalvik.vm.heapstartsize
|[dalvik.vm.heapstartsize]: [8m]
#单个java虚拟机最大的内存限制
bixiaopeng@bixiaopengtekiMacBook-Pro ~$ adb shell getprop|grep dalvik.vm.heapsize
|[dalvik.vm.heapsize]: [384m]
android程序内存一般限制在16M,当然也有24M的,而android程序内存被分为2部分:
native和dalvik,dalvik就是我们平常说的java堆,我们创建的对象是在这里面分配的,而bitmap是直接在native上分配的,对于内存的限制是 native+dalvik 不能超过最大限制。
用以下命令可以查看程序的内存使用情况:
adb shell dumpsys meminfo $package_name or $pid //使用程序的包名或者进程id
查看虾米音乐app的内存占用情况
bixiaopeng@bixiaopengtekiMacBook-Pro ~$ adb shell dumpsys meminfo fm.xiami.main
Applications Memory Usage (kB):
Uptime: 71696500 Realtime: 98283758
** MEMINFO in pid 17340 [fm.xiami.main] **
Shared Private Heap Heap Heap
Pss Dirty Dirty Size Alloc Free
------ ------ ------ ------ ------ ------
Native 0 0 0 1976 1577 226
Dalvik 2973 13956 2712 18691 10825 7866
Cursor 0 0 0
Ashmem 0 0 0
Other dev 4 44 0
.so mmap 894 2320 604
.jar mmap 0 0 0
.apk mmap 123 0 0
.ttf mmap 0 0 0
.dex mmap 2716 0 16
Other mmap 204 120 96
Unknown 808 540 804
TOTAL 7722 16980 4232 20667 12402 8092
Objects
Views: 0 ViewRootImpl: 0
AppContexts: 5 Activities: 0
Assets: 3 AssetManagers: 3
Local Binders: 5 Proxy Binders: 13
Death Recipients: 0
OpenSSL Sockets: 0
SQL
MEMORY_USED: 0
PAGECACHE_OVERFLOW: 0 MALLOC_SIZE: 0
其中size是需要的内存,而allocated是分配了的内存,对应的2列分别是native和dalvik,当总数也就是total这一列超过单个程序内存的最大限制时,OOM就很有可能会出现了。
Shared Private Heap Heap Heap
Pss Dirty Dirty Size Alloc Free
------ ------ ------ ------ ------ ------
Native 0 0 0 1976 1577 226
Dalvik 2973 13956 2712 18691 10825 7866
TOTAL 7722 16980 4232 20667 12402 8092adb shell
$ top -h
top -h
Usage: top [-m max_procs] [-n iterations] [-d delay] [-s sort_column] [-t] [-h]
-m num Maximum number of processes to display. // 最多显示多少个进程
-n num Updates to show before exiting. // 刷新次数
-d num Seconds to wait between updates. // 刷新间隔时间(默认5秒)
-s col Column to sort by <cpu,vss,rss,thr> // 按哪列排序
-t Show threads instead of processes. // 显示线程信息而不是进程
-h Display this help screen. // 显示帮助文档
$ top -n 1
top -n 1
查看前5个进程cup的使用情况
bixiaopeng@bixiaopengtekiMacBook-Pro ~$ adb shell top -m 5 -s cpu
User 33%, System 8%, IOW 0%, IRQ 0%
User 340 + Nice 2 + Sys 83 + Idle 596 + IOW 6 + IRQ 0 + SIRQ 2 = 1029
PID PR CPU% S #THR VSS RSS PCY UID Name
27256 1 12% S 37 852340K 220296K fg u0_a25 fm.xiami.main
517 0 6% S 100 842940K 118832K fg system system_server
174 0 4% S 13 66532K 14000K fg media /system/bin/mediaserver
27767 0 2% S 11 673928K 50516K bg u0_a58 com.moji.mjweather
171 0 1% S 13 97904K 51964K fg system /system/bin/surfaceflinger
User 35%, System 13%, IOW 0%, IRQ 0% // CPU占用率
User 109 + Nice 0 + Sys 40 + Idle 156 + IOW 0 + IRQ 0 + SIRQ 1 = 306 // CPU使用情况
PID CPU% S #THR VSS RSS PCY UID Name // 进程属性
xx xx% x xx xx xx xx xx xx
CPU占用率:
User 用户进程
System 系统进程
IOW IO等待时间
IRQ 硬中断时间
CPU使用情况(指一个最小时间片内所占时间,单位jiffies。或者指所占进程数):
User 处于用户态的运行时间,不包含优先值为负进程
Nice 优先值为负的进程所占用的CPU时间
Sys 处于核心态的运行时间
Idle 除IO等待时间以外的其它等待时间
IOW IO等待时间
IRQ 硬中断时间
SIRQ 软中断时间
进程属性:
PID 进程在系统中的ID
CPU% 当前瞬时所以使用CPU占用率
S 进程的状态,其中S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值是负数。
#THR 程序当前所用的线程数
VSS Virtual Set Size 虚拟耗用内存(包含共享库占用的内存)
RSS Resident Set Size 实际使用物理内存(包含共享库占用的内存)
PCY OOXX,不知道什么东东
UID 运行当前进程的用户id
Name 程序名称android.process.media
// ps:内存占用大小有如下规律:VSS >= RSS >= PSS >= USS
// PSS Proportional Set Size 实际使用的物理内存(比例分配共享库占用的内存)
// USS Unique Set Size 进程独自占用的物理内存(不包含共享库占用的内存)
温馨提示:
我们一般观察Uss来反映一个Process的内存使用情况,Uss 的大小代表了只属于本进程正在使用的内存大小,这些内存在此Process被杀掉之后,会被完整的回收掉,
Vss和Rss对查看某一Process自身内存状况没有什么价值,因为他们包含了共享库的内存使用,而往往共享库的资源占用比重是很大的,这样就稀释了对Process自身创建内存波动。 而Pss是按照比例将共享内存分割,某一Process对共享内存的占用情况。
so
查看USS和PSS可以使用adb shell procrank,前提是手机需要root
bixiaopeng@bixiaopengtekiMacBook-Pro ~$ adb shell procrank |grep xiami如果只是查看PSS也可以使用adb shell dumpsys meminfo
bixiaopeng@bixiaopengtekiMacBook-Pro ~$ adb shell dumpsys meminfo fm.xiami.main|grep TOTAL
TOTAL 143070 15312 130020 135179 122279 12667 温馨提示:
在取内存数据前可以前判断一下手机是否root, 如果root了取USS比较好一些,如果没有root取PSS也是可以的。

作者: 毕小朋 | 老 毕 邮箱: wirelessqa.me@gmail.com
微博: @WirelessQA 博客: http://blog.csdn.net/wirelessqa