转载他人
使用mysql主从复制的好处有:
1、采用主从服务器这种架构,稳定性得以提升。如果主服务器发生故障,我们可以使用从服务器来提供服务。
2、在主从服务器上分开处理用户的请求,可以提升数据处理效率。
3、将主服务器上的数据复制到从服务器上,保护数据免受意外的损失。
环境描述:
新企业要搭建架构为主从复制的mysql数据库。
主服务器(mysql-master):IP地址:192.168.48.128,mysql已安装,没有用户数据。
从服务器(mysql-slave):IP地址:192.168.48.130,mysql已安装,没有用户数据。
主从服务器均可正常提供服务。
配置主服务器(master)
1、编辑数据库配置文件my.cnf或my.ini(windows),一般在/etc/目录下。
在[mysqld]的下面加入下面代码:
log-bin=mysql-bin
server-id=1
innodb_flush_log_at_trx_commit=1
sync_binlog=1
binlog-do-db=wordpress
binlog_ignore_db=mysql
server-id=1中的1可以任定义,只要是唯一的就行。
binlog-do-db=wordpress是表示只备份wordpress。
binlog_ignore_db=mysql表示忽略备份mysql。
不加binlog-do-db和binlog_ignore_db,那就表示备份全部数据库。
2、然后重启MySQL:#servicemysqldrestart
3、登录mysql,在mysql中添加一个backup的账号,并授权给从服务器。
[root@localhost~]#mysql-uroot–p123456登录mysqlmysql>grantreplicationslaveon*.*to'backup'@'192.168.48.130'identifiedby'backup';
创建backup用户,并授权给192.168.48.130使用。
4、查询主数据库状态,并记下FILE及Position的值,这个在后面配置从服务器的时候要用到。
mysql>showmasterstatus;请记下显示的信息,配置从服务器会用到。+——————+———-+————–+——————+|File|Position|Binlog_Do_DB|Binlog_Ignore_DB|+——————+———-+————–+——————+|mysql-bin.000001|253|dbispconfig|mysql|+——————+———-+————–+——————+
1rowinset(0.00sec)
在从服务器上操作:
1)、确保/etc/my.cnf中有log-bin=mysql-bin和server-id=1参数,并把server-id=1修改为server-id=10。修改之后如下所示:
[mysqld]
log-bin=mysql-bin启动二进制文件
server-id=10服务器ID
2)、重启mysql服务。
[root@localhost~]#mysqladmin-p123456shutdown
[root@localhost~]#mysqld_safe--user=mysql&
3)、登录mysql,执行如下语句
[root@localhost~]#mysql-uroot–p123456
mysql>changemastertomaster_host='192.168.48.128',master_user='backup',master_password='backup',master_log_file='mysql-bin.000003',master_log_pos=401;
4)、启动slave同步。
mysql>startslave;
5)、检查主从同步,如果您看到Slave_IO_Running和Slave_SQL_Running均为Yes,则主从复制连接正常。mysql>showslavestatus\G
验证配置是否正常,mysql主从能否正常复制。
在主数据库上新建一个库,并且在库中写一个表和一些数据。
[root@localhost~]#mysql-uroot–p123456
mysql>createdatabasemysqltest;
mysql>usemysqltest;
mysql>createtableuser(idint(5),namechar(10));
mysql>insertintouservalues(00001,'zhangsan');
在从数据库中验证一下,是否正常复制到数据。
[root@localhost~]#mysql-uroot–p123456
mysql>showdatabases;
mysql>select*frommysqltest.user;
MySQL 数据同步 一主多从
Master 主服务器的ip:192.168.1.99
Slave1 从服务器的ip:192.168.1.113
Slave2 从服务器的ip:192.168.1.111
一、master主服务器上设置:
1.权限设置
允许用户user从ip为192.168.1.111、192.168.1.113的主机连接到mysql服务器(master),并使用password作为密码
下面涉及到,从服务器的ip、登陆用户名、登陆密码。
下面用户名是repl,密码是repl
mysql>GRANT ALL PRIVILEGES ON *.* TO 'repl'@'192.168.1.111'IDENTIFIED BY 'repl';
mysql>GRANT ALL PRIVILEGES ON *.* TO 'repl'@'192.168.1.113'IDENTIFIED BY 'repl';
2.文件配置
修改my.ini配置文件
[mysqld]
# The TCP/IP Port the MySQL Server will listen on
port=3306
加入下面两行,设置log文件、服务id
log-bin = mysql-bin.log
server-id = 1
重启mysql服务。
3.得到主服务器上当前的二进制日志名和偏移量
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000005 | 106 | | |
+------------------+----------+--------------+------------------+
1 row in set
二、slave1从服务器上设置:
1.文件配置
修改my.ini配置文件
[mysqld]
# The TCP/IP Port the MySQL Server will listen on
port=3306
加入下面两行,设置服务id、log文件
server-id = 2
log-bin = mysql-bin.log
重启mysql服务。
2.在从服务器上,关闭slave线程
Mysql>stop slave;
3.在从服务器做相应设置
指定复制使用的用户,主数据库服务器的ip、端口、以及开始执行复制的日志文件和位置等。
Mysql >Change master to
master_host='192.168.1.99',
master_port=3306,
master_user='repl',
master_password='repl',
master_log_file='mysql-bin.000005',
master_log_pos=106;
4.在从服务器上,启动slave线程
Mysql >start slave;
5.显示slave的状态信息
Mysql >show slave status;
6.显示从服务器上的进程
Mysql >show processlist;
三、slave2从服务器上设置:
1.文件配置
修改my.ini配置文件
[mysqld]
# The TCP/IP Port the MySQL Server will listen on
port=3306
加入下面两行,设置服务id、log文件
server-id = 3
log-bin = mysql-bin.log
重启mysql服务。
2.3.4.5.6步的设置,同slave1一样
三、测试查看效果
1、保持master主服务器和slave1、slave2开启;
在master服务器上操作,数据库和表,能看到,slave服务器上的数据库和表,跟随着,做相应变动。
备注:这里我们默认,要同步的数据库,他们已经具有相同的初始信息,包括schema和具体的表。如果,初始信息不相同,则需将master主服务器中的信息,先备份,然后再导入到从服务器中。
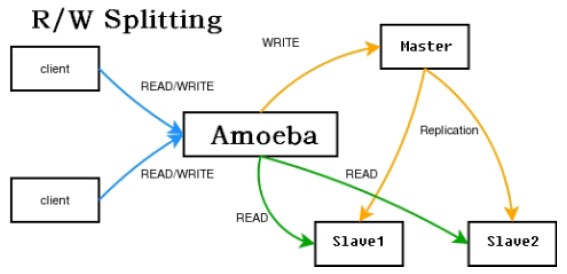
一个完整的mysql读写分离环境包括以下几个部分:
- 应用程序client
- database proxy
- database集群
在本次实战中,应用程序client基于c3p0连接后端的database proxy。database proxy负责管理client实际访问database的路由策略,采用开源框架amoeba。database集群采用mysql的master-slave的replication方案。整个环境的结构图如下所示:
实战步骤与详解
一.搭建mysql的master-slave环境
1)分别在host1(10.20.147.110)和host2(10.20.147.111)上安装mysql(5.0.45),具体安装方法可见官方文档
2)配置master
首先编辑/etc/my.cnf,添加以下配置:
log-bin=mysql-bin #slave会基于此log-bin来做replication
server-id=1 #master的标示
binlog-do-db = amoeba_study #用于master-slave的具体数据库
然后添加专门用于replication的用户:
mysql> GRANT REPLICATION SLAVE ON *.* TO repl@10.20.147.111 IDENTIFIED BY '111111';
重启mysql,使得配置生效:
/etc/init.d/mysqld restart
最后查看master状态:

3)配置slave
首先编辑/etc/my.cnf,添加以下配置:
server-id=2 #slave的标示
配置生效后,配置与master的连接:
mysql> CHANGE MASTER TO
-> MASTER_HOST='10.20.147.110',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='111111',
-> MASTER_LOG_FILE='mysql-bin.000003',
-> MASTER_LOG_POS=161261;
其中MASTER_HOST是master机的ip,MASTER_USER和MASTER_PASSWORD就是我们刚才在master上添加的用户,MASTER_LOG_FILE和MASTER_LOG_POS对应与master status里的信息
最后启动slave:
mysql> start slave;
4)验证master-slave搭建生效
通过查看slave机的log(/var/log/mysqld.log):
100703 10:51:42 [Note] Slave I/O thread: connected to master 'repl@10.20.147.110:3306', replication started in log 'mysql-bin.000003' at position 161261
如看到以上信息则证明搭建成功,如果有问题也可通过此log找原因
二.搭建database proxy
此次实战中database proxy采用 amoeba ,它的相关信息可以查阅官方文档,不在此详述
1)安装amoeba
下载amoeba(1.2.0-GA)后解压到本地(D:\openSource\amoeba-mysql-1.2.0-GA),即完成安装
2)配置amoeba
先配置proxy连接和与各后端mysql服务器连接信息(D:\openSource\amoeba-mysql-1.2.0-GA\conf\amoeba.xml):
- <server>
- <!-- proxy server绑定的端口 -->
- <property name="port">8066 </property>
- <!-- proxy server绑定的IP -->
- <!--
- <property name="ipAddress">127.0.0.1</property>
- -->
- <!-- proxy server net IO Read thread size -->
- <property name="readThreadPoolSize">20 </property>
- <!-- proxy server client process thread size -->
- <property name="clientSideThreadPoolSize">30 </property>
- <!-- mysql server data packet process thread size -->
- <property name="serverSideThreadPoolSize">30 </property>
- <!-- socket Send and receive BufferSize(unit:K) -->
- <property name="netBufferSize">128 </property>
- <!-- Enable/disable TCP_NODELAY (disable/enable Nagle's algorithm). -->
- <property name="tcpNoDelay">true </property>
- <!-- 对外验证的用户名 -->
- <property name="user">root </property>
- <!-- 对外验证的密码 -->
- <property name="password">root </property>
- </server>
- <server>
- <!-- proxy server绑定的端口 -->
- <property name="port">8066</property>
- <!-- proxy server绑定的IP -->
- <!--
- <property name="ipAddress">127.0.0.1</property>
- -->
- <!-- proxy server net IO Read thread size -->
- <property name="readThreadPoolSize">20</property>
- <!-- proxy server client process thread size -->
- <property name="clientSideThreadPoolSize">30</property>
- <!-- mysql server data packet process thread size -->
- <property name="serverSideThreadPoolSize">30</property>
- <!-- socket Send and receive BufferSize(unit:K) -->
- <property name="netBufferSize">128</property>
- <!-- Enable/disable TCP_NODELAY (disable/enable Nagle's algorithm). -->
- <property name="tcpNoDelay">true</property>
- <!-- 对外验证的用户名 -->
- <property name="user">root</property>
- <!-- 对外验证的密码 -->
- <property name="password">root</property>
- </server>
以上是proxy提供给client的连接配置
- <dbServerList>
- <dbServer name="server1">
- <!-- PoolableObjectFactory实现类 -->
- <factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
- <property name="manager">defaultManager </property>
- <!-- 真实mysql数据库端口 -->
- <property name="port">3306 </property>
- <!-- 真实mysql数据库IP -->
- <property name="ipAddress">10.20.147.110 </property>
- <property name="schema">amoeba_study </property>
- <!-- 用于登陆mysql的用户名 -->
- <property name="user">root </property>
- <!-- 用于登陆mysql的密码 -->
- <property name="password" ></property>
- </factoryConfig>
- <!-- ObjectPool实现类 -->
- <poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
- <property name="maxActive">200 </property>
- <property name="maxIdle">200 </property>
- <property name="minIdle">10 </property>
- <property name="minEvictableIdleTimeMillis">600000 </property>
- <property name="timeBetweenEvictionRunsMillis">600000 </property>
- <property name="testOnBorrow">true </property>
- <property name="testWhileIdle">true </property>
- </poolConfig>
- </dbServer>
- <dbServer name="server2">
- <!-- PoolableObjectFactory实现类 -->
- <factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
- <property name="manager">defaultManager </property>
- <!-- 真实mysql数据库端口 -->
- <property name="port">3306 </property>
- <!-- 真实mysql数据库IP -->
- <property name="ipAddress">10.20.147.111 </property>
- <property name="schema">amoeba_study </property>
- <!-- 用于登陆mysql的用户名 -->
- <property name="user">root </property>
- <!-- 用于登陆mysql的密码 -->
- <property name="password" ></property>
- </factoryConfig>
- <!-- ObjectPool实现类 -->
- <poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
- <property name="maxActive">200 </property>
- <property name="maxIdle">200 </property>
- <property name="minIdle">10 </property>
- <property name="minEvictableIdleTimeMillis">600000 </property>
- <property name="timeBetweenEvictionRunsMillis">600000 </property>
- <property name="testOnBorrow">true </property>
- <property name="testWhileIdle">true </property>
- </poolConfig>
- </dbServer>
- </dbServerList>
- <dbServerList>
- <dbServer name="server1">
- <!-- PoolableObjectFactory实现类 -->
- <factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
- <property name="manager">defaultManager</property>
- <!-- 真实mysql数据库端口 -->
- <property name="port">3306</property>
- <!-- 真实mysql数据库IP -->
- <property name="ipAddress">10.20.147.110</property>
- <property name="schema">amoeba_study</property>
- <!-- 用于登陆mysql的用户名 -->
- <property name="user">root</property>
- <!-- 用于登陆mysql的密码 -->
- <property name="password"></property>
- </factoryConfig>
- <!-- ObjectPool实现类 -->
- <poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
- <property name="maxActive">200</property>
- <property name="maxIdle">200</property>
- <property name="minIdle">10</property>
- <property name="minEvictableIdleTimeMillis">600000</property>
- <property name="timeBetweenEvictionRunsMillis">600000</property>
- <property name="testOnBorrow">true</property>
- <property name="testWhileIdle">true</property>
- </poolConfig>
- </dbServer>
- <dbServer name="server2">
- <!-- PoolableObjectFactory实现类 -->
- <factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
- <property name="manager">defaultManager</property>
- <!-- 真实mysql数据库端口 -->
- <property name="port">3306</property>
- <!-- 真实mysql数据库IP -->
- <property name="ipAddress">10.20.147.111</property>
- <property name="schema">amoeba_study</property>
- <!-- 用于登陆mysql的用户名 -->
- <property name="user">root</property>
- <!-- 用于登陆mysql的密码 -->
- <property name="password"></property>
- </factoryConfig>
- <!-- ObjectPool实现类 -->
- <poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
- <property name="maxActive">200</property>
- <property name="maxIdle">200</property>
- <property name="minIdle">10</property>
- <property name="minEvictableIdleTimeMillis">600000</property>
- <property name="timeBetweenEvictionRunsMillis">600000</property>
- <property name="testOnBorrow">true</property>
- <property name="testWhileIdle">true</property>
- </poolConfig>
- </dbServer>
- </dbServerList>
以上是proxy与后端各mysql数据库服务器配置信息,具体配置见注释很明白了
最后配置读写分离策略:
- <queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter" >
- <property name="LRUMapSize">1500 </property>
- <property name="defaultPool">server1 </property>
- <property name="writePool">server1 </property>
- <property name="readPool">server2 </property>
- <property name="needParse">true </property>
- </queryRouter>
- <queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
- <property name="LRUMapSize">1500</property>
- <property name="defaultPool">server1</property>
- <property name="writePool">server1</property>
- <property name="readPool">server2</property>
- <property name="needParse">true</property>
- </queryRouter>
从以上配置不然发现,写操作路由到server1(master),读操作路由到server2(slave)
3)启动amoeba
在命令行里运行D:\openSource\amoeba-mysql-1.2.0-GA\amoeba.bat即可:
log4j:WARN log4j config load completed from file:D:\openSource\amoeba-mysql-1.2.0-GA\conf\log4j.xml
log4j:WARN ip access config load completed from file:D:\openSource\amoeba-mysql-1.2.0-GA/conf/access_list.conf
2010-07-03 09:55:33,821 INFO net.ServerableConnectionManager - Server listening on 0.0.0.0/0.0.0.0:8066.
三.client端调用与测试
1)编写client调用程序
具体程序细节就不详述了,只是一个最普通的基于mysql driver的jdbc的数据库操作程序
2)配置数据库连接
本client基于c3p0,具体数据源配置如下:
- <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"
- destroy-method="close">
- <property name="driverClass" value="com.mysql.jdbc.Driver" />
- <property name="jdbcUrl" value="jdbc:mysql://localhost:8066/amoeba_study" />
- <property name="user" value="root" />
- <property name="password" value="root" />
- <property name="minPoolSize" value="1" />
- <property name="maxPoolSize" value="1" />
- <property name="maxIdleTime" value="1800" />
- <property name="acquireIncrement" value="1" />
- <property name="maxStatements" value="0" />
- <property name="initialPoolSize" value="1" />
- <property name="idleConnectionTestPeriod" value="1800" />
- <property name="acquireRetryAttempts" value="6" />
- <property name="acquireRetryDelay" value="1000" />
- <property name="breakAfterAcquireFailure" value="false" />
- <property name="testConnectionOnCheckout" value="true" />
- <property name="testConnectionOnCheckin" value="false" />
- </bean>
- <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"
- destroy-method="close">
- <property name="driverClass" value="com.mysql.jdbc.Driver" />
- <property name="jdbcUrl" value="jdbc:mysql://localhost:8066/amoeba_study" />
- <property name="user" value="root" />
- <property name="password" value="root" />
- <property name="minPoolSize" value="1" />
- <property name="maxPoolSize" value="1" />
- <property name="maxIdleTime" value="1800" />
- <property name="acquireIncrement" value="1" />
- <property name="maxStatements" value="0" />
- <property name="initialPoolSize" value="1" />
- <property name="idleConnectionTestPeriod" value="1800" />
- <property name="acquireRetryAttempts" value="6" />
- <property name="acquireRetryDelay" value="1000" />
- <property name="breakAfterAcquireFailure" value="false" />
- <property name="testConnectionOnCheckout" value="true" />
- <property name="testConnectionOnCheckin" value="false" />
- </bean>
值得注意是,client端只需连到proxy,与实际的数据库没有任何关系,因此jdbcUrl、user、password配置都对应于amoeba暴露出来的配置信息
3)调用与测试
首先插入一条数据:insert into zone_by_id(id,name) values(20003,'name_20003')
通过查看master机上的日志/var/lib/mysql/mysql_log.log:
100703 11:58:42 1 Query set names latin1
1 Query SET NAMES latin1
1 Query SET character_set_results = NULL
1 Query SHOW VARIABLES
1 Query SHOW COLLATION
1 Query SET autocommit=1
1 Query SET sql_mode='STRICT_TRANS_TABLES'
1 Query SHOW VARIABLES LIKE 'tx_isolation'
1 Query SHOW FULL TABLES FROM `amoeba_study` LIKE 'PROBABLYNOT'
1 Prepare [1] insert into zone_by_id(id,name) values(?,?)
1 Prepare [2] insert into zone_by_id(id,name) values(?,?)
1 Execute [2] insert into zone_by_id(id,name) values(20003,'name_20003')
得知写操作发生在master机上
通过查看slave机上的日志/var/lib/mysql/mysql_log.log:
100703 11:58:42 2 Query insert into zone_by_id(id,name) values(20003,'name_20003')
得知slave同步执行了这条语句
然后查一条数据:select t.name from zone_by_id t where t.id = 20003
通过查看slave机上的日志/var/lib/mysql/mysql_log.log:
100703 12:02:00 33 Query set names latin1
33 Prepare [1] select t.name from zone_by_id t where t.id = ?
33 Prepare [2] select t.name from zone_by_id t where t.id = ?
33 Execute [2] select t.name from zone_by_id t where t.id = 20003
得知读操作发生在slave机上
并且通过查看slave机上的日志/var/lib/mysql/mysql_log.log发现这条语句没在master上执行
通过以上验证得知简单的master-slave搭建和实战得以生效
已有 0人发表留言,猛击->> 这里<<-参与讨论
ITeye推荐