写在前头
静态化是解决减轻网站压力,提高网站访问速度的常用方案,但在强调交互的We2.0 时代,对静态化提出了更高的要求,静态不仅要能静,还要能动,下面我通过一个项目,谈谈网站静态化后的架构设计方案,同时和大家探讨一下,在开源产品大行其道,言架构必称MemberCache, Nginx,的时代,微软技术在网站架构设计中的运用.
静态化的设计原则和步骤
静态化是解决减轻网站压力,但是静态化也会带来一系列的问题,包括开发上复杂度的增加,维护难度的增加,运用不的当,更可能适得其反,而许多替代方案,比如页面缓存,如果运用得当,也能起到很好的效果,所以在开始之前,必须进行详细的考察,确定是否适合静态化,并制定适合的静态化方式,下面先介绍一下
l 考查读写比:
读写比,准确的说是读写负荷比,是否值得静态化的最终考虑,由于一般写入的压力明显大于读出的压力,如果写入太频繁,或者每次写入消耗的资源太多,都不能达到效果,我觉得读写比例10:1应该是个上限.具体情况需要根据自己的业务逻辑判断
l 确定页面呈现的内容是否适合静态化:
在设计方案时,必须详细考虑每个原型页面,找到页面上展示的信息,和他的更新方式,更新时机,更新频率,一定要注意那些不起眼的信息,他们可能左右你的设计,
比如:我们以CSDN的论坛的任意一篇帖子为例,进行分析
![]()
上面的帖子中呈现的内容主要是这样几块,帖子内容,回复内容,发帖人回复人的用户信息
n 帖子内容和回复内容在发帖时更新,发帖后用户可以修改其内容,更新频率高
n 用户信息,用户修改个人信息时可能会发生更改,用户等级增加时也可能发生更改,比如加星,更新频率低
n 回复数将每次回复后都要更改,更新频率高
n 设计时要注意细节,如上图中圈出来的部分,这些部分是怎么修改的,频率有多大,一个都不能放过.
l 确定生成方式:
在上面帖子一例中.每次更改都重新生成页面是不可取的,一篇比回复数多的帖子,需要的数据量是巨大的(每层楼的用户信息,回复内容),任何修改,都需要重新取出数据进行生成是不能允许的.一般除非你的页面基本不用更新,或者更新开销极小,(比如一段嵌入的广告代码)才能采用整体更新的方式,不然就需要我们找到合适的更新页面局部区域的方法:
一般有下面两个方法:
1) 正则修改法:
比如,如果帖子中的回复数,html代码是这样
<label>回复数<var id="replyCount">34</var></label>
我们可以通过用下面正则来查找并替换计数
(?<=id="replyCount">)\d{1,}2) 页面区域分块:
把页面分成很多小块,在显示时组装起来,比如DotText就采用这个方法
![]()
这是一篇典型的Dottext blog页面,其中红色标定部分是一个独立的文件,而黄色框内的是脚本动态加载,这些部分在最终显示的时候组合起来,最终构成了一篇Blog,具体的组合方法也有多种,可以使用Include,也可以自己来实现.DotText就自己实现了一套加载机制
上面的两种方法并不孤立,并可以根据需要,配合使用
l 确定需要动态加载的信息:
页面上总有一些内容看起来不太适合静态化,最典型的是一些统计结果,比如如果你在做一个图书介绍页面,可能就会需要展示图书的当天综合评分,或者书籍排名,这些内容需要用脚本进行动态加载
既然做了静态化,就是希望减少服务器负载,动态加载的数据总是不得已而为之,有的时候在需求允许的情况下,我们在数据在实时性和性能方面做一些妥协,比如上面帖子中的用户星级和昵称,从数据实时性上说,当用户的星级增长,他发言的所有帖子都应该发生变化,所以应该用动态加载.然而其实上这些信息如果不发生变化,也无伤大雅,用户反而能够看到自己在多年前发帖时的级别和昵称.
现实中的项目
X网站是大型的电影资讯,电影社区,向外提供电影相关信息服务,以及用户社区,其中信息服务部分, 其中大部分页面属于信息呈现页,读取量比较大,百万级别pv,信息主要由编辑在后台发布,更新较少,但其页面上有大量的交互性的内容,比如评论,收藏列表,同时许多内容允许用户创造,比如上传图片,添加注释.交互内容的数量和交互的频繁程度,都超过了普通的咨询页面,这次调整,准备将其中访问量最大的几块:电影资料页,影人资料页,进行静态化,如果成功,还将运用到更多的频道,基本实现全站静态化
通过对页面设计和前一版本的分析,下面是具有挑战性的地方.这些特点基本使用于大多数web2.0的站点,很具有典型意义
l 页面生成的触发条件复杂
一般论坛中的帖子或者blog,更新方式比较单一:主要是由回复进行触发还有少数的修改动作,然而该网站一个页面上需要根据不同触发条件就有20多个, 比如光二级菜单:用户发布图片,删除图片,发布或者删除影片信息,发布或者修改视频,后台修改电影信息,都有可能触发
l 一个动作触发生成的页面可能很多而且相互交叠
每一个动作都会触发一系列的生成,并且不同动作可能都会涉及同一个页面或者区域的生成.
比如:用户给一步电影评分,需要生成评分更多页,评分统计更多页,首页右侧谁还关注此影片小区域,等等.用户收藏一个影片,也需要更新首页右侧谁还关注此影片小区域
l 触发频繁:
虽然不及某些更大规模的网站,但是由于涉及众多用户参与的内容,评论,收藏等等,触发点多,发生频度相当频繁
l 页面多,结构复杂,空间占用大:
通常,需要生成的页面规模是这样粗略估算的,Rn*P,Rn为资源数,P为每个资源的页面数,所谓资源,可以看做一个生成单位,其页面数可以简单看做发布一个资源,就需要生成其所有相关页面数量,比如:发布一个blog,就需要生成一个Blog页,同时还需要生成或者更新个人主页的blog列表,算上个人主页右侧的分类文章数的小块,也就是最多10来个页面或者区域,但是发布一个电影,其相关的页面至少有50个以上,而且有的页面还带有分页,一个信息比较丰富的电影,其页面竟可以达到千个以上,空间10~20M,而且资源总数也不少,电影80000左右,电影人虽然P值较少,但是总量确有几十万之巨,估计静态页面磁盘占用量几百个G
l 向下兼容
这是一个已有系统,旧系统的框框需要突破,但又没有时间,或者不能完全突破,比如Url,已经被收录到搜索引擎,就不能随便调整,还有一些地方,原本没有为静态生成考虑,另一些地方又需要兼容旧的设计.
l 多台前端Web
这种结构要求生成的文件可能需要分布到多个服务器(另一个方案是放在几台专用的机器上,等前端来取)
l 任务紧迫
架构讨论结束仪式六月初,离奥运开幕上线只有两月,也就是说所有底层框架实现,页面模板开发,调试测试,动作的整理,必须在7月底全部完成,按我原来估计,光实现这几块的上百个页面模板和填充方法,也需要那么长的时间
综合考虑上述因素,架构必须要有以下几个方面的特点
l 动作可以灵活扩展配置,某个动作对应哪些生成,应该可以配置,并且可以分组
l 文件必须有分发机制
l 分发和生成必须独立出来,并且支持分布式
l 各种的动作,必须转化为消息,发送到生成和分发服务器进行处理
l 针对同意资源频繁动作,在变量相同的情况下能够具有合并的能力
l 动作必须有记录
l 尽量考虑使用已有成熟技术,节省开发时间
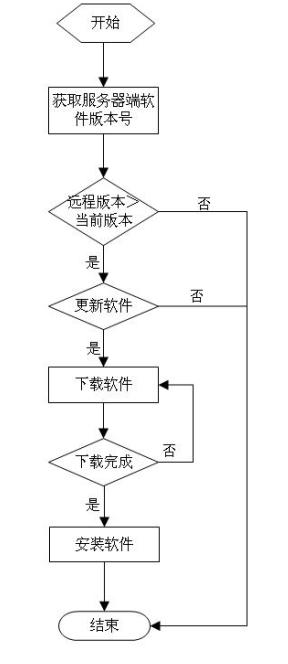
下面是设计的第一个架构
![]()
用户的动作经过MSMQ [1]传入到生成分发中心(途中绿色箭头)进行处理,,处理中心接受到消息后,负责生成对应的页面或者页面区域,并将页面分发到各个服务器,负载均衡沿用以前的架构,采用微软的NLB [2]
之所以用MSMQ,就是看上了他提供的完整的消息存储恢复机制,这样我们能确保即使服务器down掉重启后,消息依然能正常处理,碰巧我们cms组的同事MSMQ非常熟悉,并且真准备在另外一个项目中使用类似的架构—于是一拍即合
页面采用分块存储,这样能保证生成时目标小,开销小,也能重用性,然后再藉由SSI [3](shtml include)进行整合,之所以采取这样的方案,而不采用Dottext的整合方式,是因为如果采用Dottext的方式,就必须走IIS和.Net的管道 [4],而据测试,经过管道和直接返回html性能有非常大的差异,而使用ssi,在性能上是一个折中,并且可以Light HTTPd等高性能web服务器
模板生成方式,采用了XSLT和另外一种自定义的模板(我的同事开发的机制,很有趣, 理论上能把传统模板替换的性能开销全部消除),生成的最终产物是shtml,之所以生成shtml是为了使用其ssi(Server Side Include)的特性,保证一定的灵活性,并实现热点数据的分离:某些页面上的部分可能会频繁更新和生成,而其它地方不变,或者某个部分是所有页面通用的(比如页头和页脚),较之php下常常使用smarty,生成php文件,虽然灵活性不如php,但是性能上不相上下,还略高.
但是这个设计的问题是动态内容和静态内容没有分开,生成的html页面,和动态页面都放在前端服务器上,通过负载均衡访问,也造成了分发服务器需要分发到多台服务器,网络IO效率较低,而且静态内容需要的磁盘空间很大,且小文件非常多,和动态页面混在一起不便于优化,所以第二个方案对生成的静态内容与动态内容使用不同的服务器
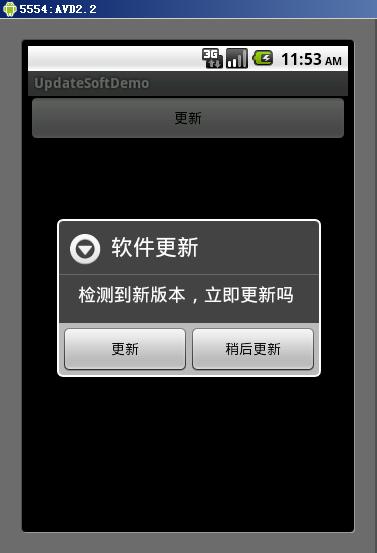
方案二:
![]()
我们把生成的静态文件单独放置,可以看到,前端增加Nginx,作为跳转,把电影,影人资料库的页面转向静态服务器,其他的调用转向动态服务器,这样我们就可以单独为静态服务器进行优化,比如采用更高效的服务器等等.
同时减少了文件分发的次数(甚至可以只分发到本机),提高生成分发的处理能力
更进一步,可以把图片服务分到另外一组机器上,使用独立的域名,比如img.xxx.com,这样可以有效的减少带宽
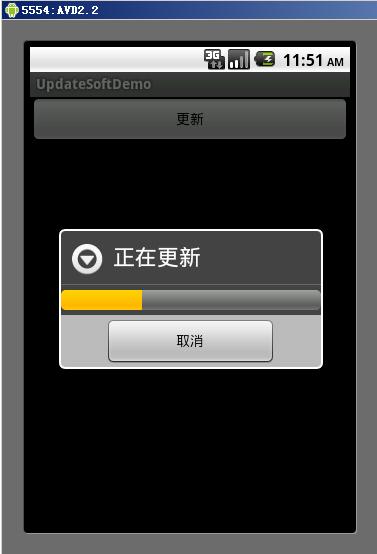
最终完整架构:
![]()
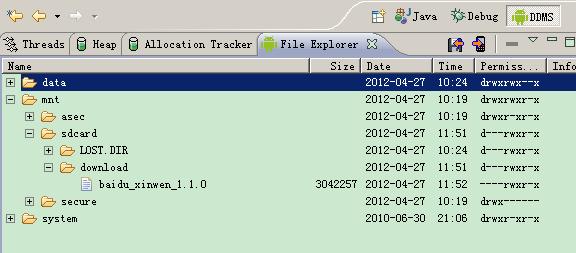
文件生成分发中心
下图是文件生成分发中心的工作流程图
![]()
生成服务对外只有一个输入,就是消息,一个输出:静态文件,内部根据消息,从配置文件中找到对应的生成方法,取出相应的模板,进行数据填充
分发服务主要吧生成服务产生的文件进行分发,分发到前端的N台服务器上,开始考虑得比较复杂,希望分发服务可以跨越协议(本地文件系统,局域网,http协议),跨越多种存储介质(文件系统,数据库),实际最后定下来基本是本地文件系统或者局域网传输
注:上图中文件分发的部分也可以通过定制MogileFS,来实现分布式文件系统
马后炮:
总结起来,静态化除了对架构方面的影响,对开发和测试流程也有影响
对测试提出更高的要求:
因为一旦上线后,某个页面发现问题,即使是文字的修改,也需要重新生成许多页面,所以测试人员必须非常仔细,测试周期也需要延长
开发人员需要掌握模板语言
需要掌握一种模板预言,无论是Xslt还是自己开发的模板语言,都需要花一定的时间掌握
需要给第一次生成腾出足够时间:
如果不是新系统,那么数据迁移和生成的过程就比较痛苦,由于页面众多,第一次生成的过程可能需要以天来计算,在制定上线方案是就需要考虑到这个方面
Nginx作为前端的跳转,根据其他网站的经验,应该可以达到2-3万并发连接,但是使用之后,常常有卡壳的情况发生,具体症状为在浏览器中访问页面时,连接超时,或者一直不响应,此时Nginx连接数并不高,好在还有第一套方案可以备用,让我们有时间去解决这个问题,如果大家对这个问题有什么心得,欢迎交流
我的联系方式
MSN:yizhu2000@hotmail.com
Gtalk:yizhu2005@gmail.com
篇后:
在大型web开发上,我感到微软产品结构(包括微软开源社区的成果)在某些方面还存在一些不足:
高性能服务器选择太少
Linux下可以采用Light HTTPd,Nginx等诸多服务器,这些服务器在很多方面的表现会让Windows下唯一的选择--IIS相形见绌
分布式文件系统
微软及其社区没有比较著名的产品出现,Linux下有MogileFS
微软架构下,文件系统选择太少:
在Linux下我们可以选择诸如Ext3,ReiserFS,而Windows环境下,NTFS是唯一的选择,不过值得称道的是.NTFS的效率和稳定性都相当不错.
开源技术对windows版本的支持态度不积极
诸多在Linux下名声卓著的开源产品,又懒于为Windows提供相应的版本,或者提供的windows版本效果差强人意.使得采用微软服务器的厂商少了很多选择
现在的Web开发已经进入了各种技术大混合,大整合的时代,任何一个厂商都不可能涵盖所有方面,在后端架构和逻辑方面.Net和Java严谨,良好的编程风格,清晰的设计思路,较高的运行效率,以及稳定的配套服务支持,是其最大的优势,对主要擅长微软技术的Web工程师和架构师而言,应该增进对Linux及开源社区的了解,才能根据需求设计出合理的架构
[1] Message Queuing: A Scalable, Highly Available Load-Balancing Solution
http://msdn.microsoft.com/en-us/library/ms811052.aspx
[2] 网络负载平衡(NLB)详解,注意文章后给出的参考链接
http://blog.chinaitlab.com/user1/563173/archives/2007/132713.html
[3] 怎样使用ssi,及其语法:
http://blog.csdn.net/dadou2007/archive/2008/06/08/2521365.aspx
Nginx下的ssimodule
http://www.nginx.cn/NginxChsHttpSsiModule
[4] asp.net的处理机制http://www.microsoft.com/china/msdn/library/webservices/asp.net/dnvs05Internals.mspx?mfr=true
html.asp.aspx运行效率比较
http://iamlibai.blogbus.com/logs/2017870.html
 本文的作者:Ed Finkler
本文的作者:Ed Finkler


 按钮,如果成功 提示Inject Success. 如图中所示。恭喜你,伪造成功。
按钮,如果成功 提示Inject Success. 如图中所示。恭喜你,伪造成功。























