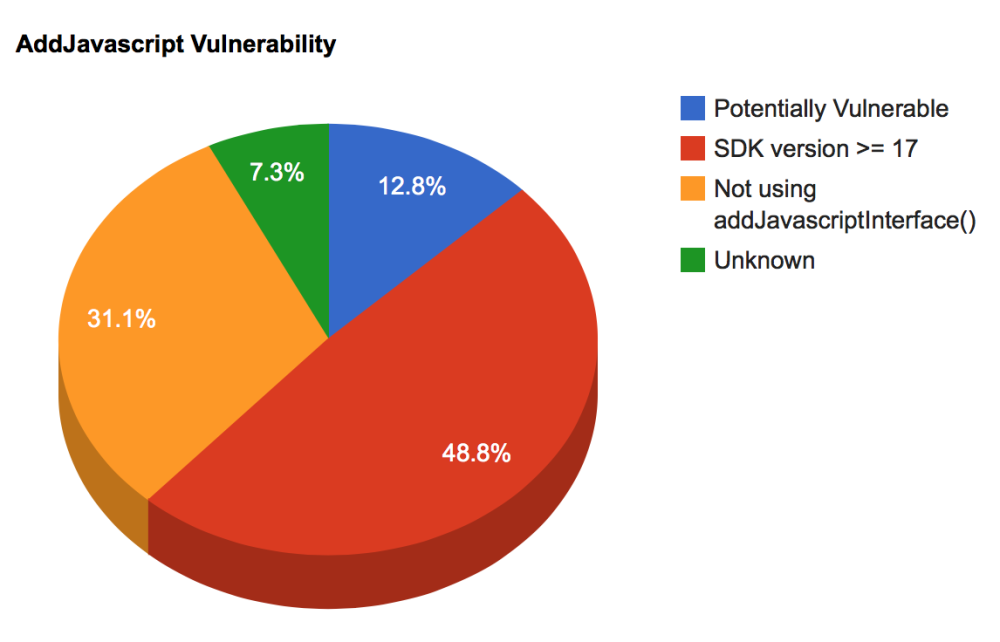
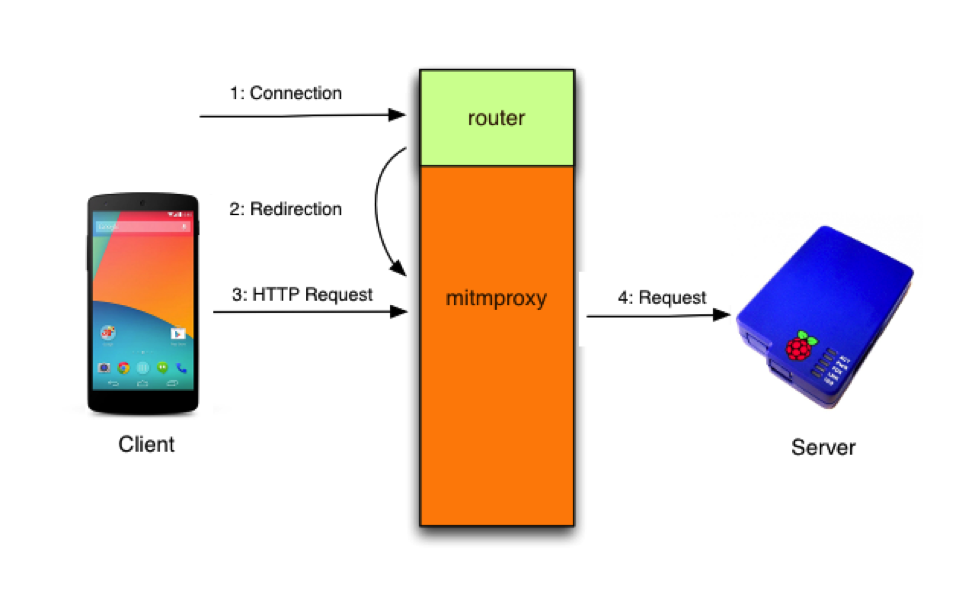
Web网站测试流程和方法(转载)
1测试流程与方法
1.1测试流程
进行正式测试之前,应先确定如何开展测试,不可盲目的测试。一般网站的测试,应按以下流程来进行:
1)使用HTML Link Validator将网站中的错误链接找出来;
2)测试的顺序为:自顶向下、从左到右;
3)查看页面title是否正确。(不只首页,所有页面都要查看);
4)LOGO图片是否正确显示;
5)LOGO下的一级栏目、二级栏目的链接是否正确;
6)首页登录、注册的功能是否实现;
7)首页左侧栏目下的文章标题、图片等链接是否正确;
8)首页中间栏目下的文章标题、图片等链接是否正确;
9)首页右侧栏目下的文章标题、图片等链接是否正确;
10)首页最下方的【友情链接】、【关于我们】等链接是否正确;
11)进入一级栏目或二级栏目的列表页。查看左侧栏目名称,右侧文章列表是否正确;
12)列表页的分页功能是否实现、样式是否统一;
13)查看文章详细页面的内容是否存在乱码、页面样式是否统一;
14)站内搜索(各个页面都要查看)功能是否实现;
15)前后台交互的部分,数据传递是否正确;
16) 默认按钮要支持Enter及选操作,即按Enter后自动执行默认按钮对应操作。
1.2 UI测试
UI测试包括的内容有如下几方面:
1)各个页面的样式风格是否统一;
2)各个页面的大小是否一致;同样的LOGO图片在各个页面中显示是否大小一致;页面及图片是否居中显示;
3)各个页面的title是否正确;
4)栏目名称、文章内容等处的文字是否正确,有无错别字或乱码;同一级别的字体、大小、颜色是否统一;
5)提示、警告或错误说明应清楚易懂,用词准确,摒弃模棱两可的字眼;
6)切换窗口大小,将窗口缩小后,页面是否按比例缩小或出现滚动条;各个页面缩小的风格是否一致,文字是否窜行;
7)父窗体或主窗体的中心位置应该在对角线焦点附近;子窗体位置应该在主窗体的左上角或正中;多个子窗体弹出时应该依次向右下方偏移,以显示出窗体标题为宜;
8)按钮大小基本相近,忌用太长的名称,免得占用过多的界面位置;避免空旷的界面上放置很大的按钮;按钮的样式风格要统一;按钮之间的间距要一致;
9)页面颜色是否统一;前景与背景色搭配合理协调,反差不宜太大,最好少用深色或刺目的颜色;
10)若有滚动信息或图片,将鼠标放置其上,查看滚动信息或图片是否停止;
11)导航处是否按相应的栏目级别显示;导航文字是否在同一行显示;
12)所有的图片是否都被正确装载,在不同的浏览器、分辨率下图片是否能正确显示(包括位置、大小);
13)文章列表页,左侧的栏目是否与一级、二级栏目的名称、顺序一致;
14) 调整分辨率验证页面格式是否错位现象;
15)鼠标移动到Flash焦点上特效是否实现,移出焦点特效是否消失;
16) 文字颜色与页面配色协调,不使用与背景色相近的颜色。
17) 每个非首页静态页面含图片字节不超过300K,全尺寸banner第一个场景控制在200k以内二个场景在300K,三个场景在400K以此类推
18) 同一界面上的控件数最好不要超过10个,多于10个时可以考虑使用分页界面显示。
19) 超过一屏的内容,在底部应有go top按钮
20) 超过三屏的内容,应在头部设提纲,直接链接到文内锚点
21) 首页,各栏目一级页面之间互链,各栏目一级和本栏目二级页面之间互链
22) 导航的文字要简明扼要,字数限制在一行以内
23) 报表显示时应考虑数据显示宽度的自适应或自动换行。
24) 所有有数据展现的界面(如统计、查询、编辑录入、打印预览、打印等),必须使测试数据的记录数超过一屏/一页,以验证满屏/页时其窗体是否有横向、纵向滚动条或换页打(L)印,界面显示是否正常;
25) 如有多个系统展现同一数据源时,应保证其一致性;
26) 对于报表中的所有字段值都应该有明确的定义,对于无意义的字段值,不应该显示空,应显示“--”或“/”,表示该字段值无意义。
27) 对统计的数据应按用户习惯进行分类、排序。
28) 界面内容更新后系统应提供刷新功能。
29) 用户在退出系统后重新登陆时应考虑是否需要自动返回到上次退出系统时的界面;
30)在多个业务功能组成的一个业务流程中,如果各个功能之间的执行顺序有一定的制约条件,应通过界面提示用户。
31)用户提示信息应具有一定的指导性,在应用程序正在进行关键业务的处理时,应考虑在前台界面提示用户应用程序正在进行的处理,以及相应的处理过程,在处理结束后再提示用户处理完毕。
32)在某些数据输入界面,如果要求输入的数据符合某项规则,应在输入界面提供相应的规则描述;当输入数据不符合规则时应提示用户是否继续。
33)在对任何配置信息修改后,都应该在用户退出该界面时提示用户保存(如果用户没有主动保存的情况下);
34)在对某些查询功能进行测试时,应考虑查询条件的设置的合理性以及查询结果的互补性。如某些后台处理时间不应该作为查询条件。
35)界面测试时,应考虑某一界面上按钮先后使用的顺序问题,以免用户对此产生迷惑。例如只能在查询成功后显示执行按钮。
36)界面测试时,应验证窗口与窗口之间、字段与字段之间的浏览顺序是否正确;
37)在某些对数据进行处理的操作界面,应考虑用户可能对数据进行处理的频繁程度和工作量,考虑是否可以进行批量操作。
38)界面测试时应验证所有窗体中的对象状态是否正常,是否符合相关的业务规则需要。
49)应验证各种对象访问方法(Tab 健、鼠标移动和快捷键)是否可正常使用,并且在一个激活界面中快捷键无重复;
40)界面测试不光要考虑合理的键盘输入,还应考虑是否可以通过鼠标拷贝粘贴输入。
41)对于统计查询功能的查询结果应验证其是否只能通过界面上的查询或刷新按键人工触发,应避免其他形式的触发。
42)对界面上的任何对象进行拖拉,然后进行查询、打印,应保证查询打印结果不变;
43)确保数据精度显示的统一:如单价0元,应显示为0.00元;
44)确保时间及日期显示格式的统一;
45)确保相同含义属性/字段名的统一;
46)对所有可能产生的提示信息界面内容和位置进行验证,确保所有的提示信息界面应居中。
1.3链接测试
链接测试主要分为以下几个方面:
1)页面是否有无法连接的内容;图片是否能正确显示,有无冗余图片,代码是否规范,页面是否存死链接(可以用HTML Link Validator工具查找);
2)图片上是否有无用的链接;点击图片上的链接是否跳转到正确的页面;
3)首页点击LOGO下的一级栏目或二级栏目名称,是否可进入相应的栏目;
4)点击首页或列表页的文章标题的链接,是否可进入相应的文章的详细页面;
5)点击首页栏目名称后的【更多】链接,是否正确跳转到相应页面;
6)文章列表页,左侧的栏目的链接,是否可正确跳转到相应的栏目页面;
7)导航链接的页面是否正确;是否可按栏目级别跳转到相应的页面;
(例:【首页->服务与支持->客服中心】,分别点击“首页”、“服务与支持”、“客服中心”,查看是否可跳转到相应页面;)
8) 新闻、信息类内容通常用新开窗口方式打开。
9) 顶部导航、底部导航通常采取在本页打开。
1.4搜索测试
搜索测试主要分为以下几个方面:
1)搜索按钮功能是否实现;
2)输入网站中存在的信息,能否正确搜索出结果;
3)输入键盘中所有特殊字符,是否报错;特别关注:_ ? ’ . • \ / -- ;特殊字符
4)系统是否支持键盘回车键、Tab键;
5)搜索出的结果页面是否与其他页面风格一致;
6)在输入域输入空格,点击搜索系统是否报错;
7)本站内搜索输入域中不输入任何内容,是否搜索出的是全部信息或者给予提示信息;
8)精确查询还是模糊查询,如果是模糊查询输入:中%国。查询结果是不是都包含中国两个字的信息;
9)焦点放置搜索框中,搜索框内容是否被清空;
10)搜索输入域是否实现回车键监听事件;
1.5表单测试
表单测试主要分为以下几个方面:
1)注册、登录功能是否实现;
2)提交、清空按钮功能是否实现;
3)修改表单与注册页面数据项是否相同,修改表单是否对重名做验证;
4)提交的数据是否能正确保存到后台数据库中(后台数据库中的数据应与前台录入内容完全一致,数据不会丢失或被改变);
5)表单提交,删除,修改后是否有提示信息;提示、警告、或错误说明应该清楚、明了、恰当。
6)浏览器的前进、后退、刷新按钮,是否会造成数据重现或页面报错;
7)提交表单是否支持回车键和Tab键;Tab键的顺序与控件排列顺序要一致,目前流行总体从上倒下,同时行间从左到右的方式
8)下拉列表功能是否实现和数据是否完整(例如:省份和市区下拉列表数据是否互动);
1.6输入域测试
输入域测试主要分为以下几个方面:
1)对于手机、邮箱、证件号等的输入是否有长度及类型的控制;
2)输入中文、英文、数字、特殊字符(特别注意单引号和反斜杠)及这四类的混合输入,是否会报错;
3)输入空格、空格+数据、数据+空格,是否报错;
4)输入html语言的<head>,是否能正确显示;
5)输入全角、半角的英文、数字、特殊字符等,是否报错;
6)是否有必填项的控制;不输入必填项,是否有友好提示信息;
7)输入超长字段,页面是否被撑开;
8)分别输入大于、等于、小于数据表规定字段长度的数据,是否报错;
9)输入非数据表中规定的数据类型的字符,是否有友好提示信息;
10)在文本框中输入回车键,显示时是否回车换行;
11) 非法的输入或操作应有足够的提示说明。
1.7分页测试
分页测试主要分为以下几个方面:
1)当没有数据时,首页、上一页、下一页、尾页标签全部置灰;
2)在首页时,“首页”“上一页”标签置灰;在尾页时,“下一页”“尾页”标签置灰;在中间页时,四个标签均可点击,且跳转正确;
3)翻页后,列表中的数据是否扔按照指定的顺序进行了排序;
4)各个分页标签是否在同一水平线上;
5)各个页面的分页标签样式是否一致;
6)分页的总页数及当前页数显示是否正确;
7)是否能正确跳转到指定的页数;
8)在分页处输入非数字的字符(英文、特殊字符等),输入0或超出总页数的数字,是否有友好提示信息;
9)是否支持回车键的监听;
1.8 交互性数据测试
1)前台的数据操作是否对后台产生相应正确的影响
(如:查看详细信息时,需扣除用户相应的授权点数);
2)可实现前后台数据的交互(如:在线咨询,能否实现数据的交互实时更新);数据传递是否正确;前后台大数据量信息传递数据是否丢失(如500个字符);多用户交流时用户信息控制是否严谨;
3)用户的权限,是否随着授权而变化;
4)数据未审核时,前台应不显示;审核通过后,前台应可显示该条数据;
功能测试中还需注意以下几点内容:
1)点击【收藏我们】,标题是否出现乱码;收藏的url与网站的url是否一致;能否通过收藏夹来访问网站;
2)对于修改、删除等可能造成数据无法恢复的操作必须提供确认信息,给用户放弃选择的机会;
3)在文章详细页面,验证字体大小改变、打印、返回、关闭等功能是否实现;
2安全性测试
2.1目录设置
目录测试主要分为以下几个方面:
1)在测试路径上出现: http://218.61.30.17:7001/dzgh/xwzx/khzl/2008/11/13/58127.html把/2008/11/13/58127.html去掉,看是否能出现目录下文件;
2)访问文件目录如果出现403错误,说明网页加以限制拒绝访问;
3)访问文件目录如果出现SSH其他根目录路径,说明有漏洞缺陷;
4)用X-Scan-v3.2-cn工具对网站服务器扫描。可以对网站参透出开启的端口号,SSH弱口令,网站是否存在高风险;比如:在扫描参数中输入测试网站的地址,点击扫描。如果扫描出网站端口号高风险或SSH弱口令可以与开发人员沟通进行修改;
5)测试有效和无效的用户名和密码,要注意到是否大小写敏感,可以试多少次的限制,是否可以不登陆而直接浏览某个页面等。
6)Web应用系统是否有超时的限制,也就是说,用户登陆后在一定时间内(例如15分钟)没有点击任何页面,是否需要重新登陆才能正常使用。
7)为了保证Web应用系统的安全性,日志文件是至关重要的。需要测试相关信息是否写进了日志文件、是否可追踪。
8)当使用了安全套接字时,还要测试加密是否正确,检查信息的完整性。
9)服务器端的脚本常常构成安全漏洞,这些漏洞又常常被黑客利用。所以,还要测试没有经过授权,就不能在服务器端放置和编辑脚本的问题。
10)网页加载速度测试可以采用HttpWatch软件等,可以知道那些内容影响网站整体速度。
一、界面测试公共测试用例
界面测试一般包括页面文字,控件使用,少图,CSS,颜色等。
<!--[if !supportLists]-->1. <!--[endif]-->文字
内容一致性:
1)公司要求文字的一致性,例如各种宣传文字、注册的协议条款、版权信息等;
2)各处相同含义文字的一致性,例如标题栏文字、页面主题文字、弹出窗口文字、菜单名称、功能键文字等。
样式一致性
1)(通常分类包括)各类文字字体、字号、样式、颜色、文字间距、对齐方式;
2)按钮的文字间距,按钮长度一定前提下,2个字的按钮,需要中间空一格(或者其它约定,需要统一);
3)链接文字,同一类,菜单、小标题、页角文字链接,在点击时颜色变化要相同;
4)对齐方式,页面上文字的对齐,例如表单、菜单列、下拉列表中文字的对齐方式(左、右、居中等要统一)
语言习惯:
1)中文:文字简单,含义明确,无歧异,无重复,无别字,正确运用标点符号。
2)英文。
3)日文。
<!--[if !supportLists]-->2. <!--[endif]-->按钮
1)button的样式整体要统一,例如突出、扁平、3D效果等只能选其一;
2)采用的图片表述相同功能,要采用单一图标。
<!--[if !supportLists]-->3. <!--[endif]-->文本框
1)录入长度限制,根据 数据库的设计,页面直接限定录入长度(特殊处屏蔽复制、粘贴);
2)文本框自身的长度限制,主要考虑页面样式。
<!--[if !supportLists]-->4. <!--[endif]-->单选框
1)默认情况要统一,已选择,还是未选。
<!--[if !supportLists]-->5. <!--[endif]-->日期控件
1)图标、控件颜色、样式统一;
2)点击控件、文本框均应弹出日期选择框。
<!--[if !supportLists]-->6. <!--[endif]-->下拉选择框
1)默认是第一个选项,还是提示请选择一个。
<!--[if !supportLists]-->7. <!--[endif]-->提示信息
1)静态文字与它的提示信息一致性,例如静态文字为‘ID’,出错信息显示‘用户ID’;
2)空值时,出错信息需要统一,例如可以采用“静态文字”+不能为空;
3)出现录入错误时,例如可以统一采用“静态文字”+格式不符合要求;
4)提示信息标点符号是否标识;点击上一步,返回的页面上不应残留出错信息;
5)静态提示信息,在录入框右侧,应有录入信息的相应要求的提示文字,达到方便操作的目的;
6)必输项提示信息,必输项提示信息采用统一的标志。
<!--[if !supportLists]-->8. <!--[endif]-->导航测试
死导航、乱导航、操作复杂等。
<!--[if !supportLists]-->9. <!--[endif]-->链接测试
1)发现404错误。
2)避免死链接情况,执行完相应操作应有返回按钮,返回到相应页面;例如:操作成功后,进入成功提示信息页面,但页面没有返回按钮,无法及时进入操作之前的页面。
<!--[if !supportLists]-->10. <!--[endif]-->IE的后退
退出系统,无论直接关闭浏览器或点击后退键,退出都不应再返回系统。
<!--[if !supportLists]-->11. <!--[endif]-->分辨率
页面文字显示、样式等要支持常见分辨率,例如CRT显示器的1024*768,LCD的1280*1024。
<!--[if !supportLists]-->12. <!--[endif]-->重复提交问题
1)功能操作完成后,鼠标右键点击所在页面,选择弹出菜单的刷新功能,容易出现重复提交问题。
2)功能操作完成后,通过IE的后退键进行重复操作,容易出现重复提交问题。
3)某功能键反应时间延迟时(限制客户端网络带宽等方式来模拟实现),在短时间内重复点击该功能键,容易出现重复提交问题;
<!--[if !supportLists]-->13. <!--[endif]-->防止 SQL注入式攻击
1)不允许任何直接在jsp页面调用SQL语句,这种情况常发生在系统的后期修改中。
<!--[if !supportLists]-->14. <!--[endif]-->用户非授权页面访问
1)每个页面都需要安全验证,防止用户通过直接拷贝具体页面地址等方式,访问系统;
2)页面过期的时间设定,用户在设定时间内未进行任何操作,不允许访问系统。
二、文本框公共测试用例
<!--[if !supportLists]-->1. <!--[endif]-->文本框为字符型
必填项非空校验:
1)必填项未输入--程序应提示错误;
2)必填项只输入若干个空格,未输入其它字符--程序应提示错误;
字段唯一性校验:(不是所有字段都作此项校验,视实际项目情况而定)
1)新增时输入重复的字段值--必须提示友好信息;
2)修改时输入重复的字段值--必须提示友好信息;
字段长度校验:
1)输入[最小字符数-1]--程序应提示错误;
2)输入[最小字符数]--OK;
3)输入[最小字符数+1]--OK;
4)输入[最大字符数-1]--OK;
5)输入[最大字符数]--OK;
6)输入[最大字符数+1]--程序应提示错误;
字段为特殊字符校验:
1)输入域如对某些字符禁止输入时,限制是否成功,提示信息是否友好;
2)中文、英文、空格,数字,字符,下划线、单引号等所有特殊字符的组合;
3)所有特殊字符都必须进行测试(!~@#$^&*()_+{}|:“<>?/.,;‘[]\=-`¥……()--:《》?、。,;’【】、=-• )
字段为特殊代码校验:
1)输入html代码:比如”你好”;--必须以文本的形式将代码显示出来。
2)输入JavaScript代码:比如;--必须以文本的形式将代码显示出来。
多行文本框输入:
1)是否允许回车换行;
2)保存后再显示能够保持输入时的格式;
3)仅输入回车换行,检查能否正确保存;若能,查看保存结果。若不能,查看是否有正确提示;
4)仅输入空格,检查能否正确保存;若能,查看保存结果。若不能,查看是否有正确提示。
<!--[if !supportLists]-->2. <!--[endif]-->文本框为数值型
边界值:
1)输入[最小值-1]--程序应提示错误;
2)输入[最小值]--OK;
3)输入[最大值]--OK;
4)输入[最大值+1]--程序应提示错误;
位数:
1)输入[限制位数]--OK;
2)输入[限制位数+1]--根据实际项目而定,是否自动四舍五入成限制位数,还是提示信息;
3)输入[限制位数-1]--OK;
异常值、特殊值:
1)输入非数值型数据:汉字、字母、字符--程序应提示错误;
2)输入负数--根据实际项目而定,如果不允许输入负数,必须提示友好信息;
3)字段禁止直接输入非数值型数据时,使用“粘贴”、“拷贝”功能尝试输入,并测试能否正常提交保存--只能使用“粘贴”、“拷贝”方法输入的特殊字符应无法保存,并应给出相应提示;
4)全角数字和半角数字的情况--全角数字不能保存,提示友好信息,半角数字正常保存;
5)首位为零的数值:如01=1--视实际项目情况而定;
<!--[if !supportLists]-->3. <!--[endif]-->文本框为日期型
合法性检查:
1)日输入[0日]--程序应提示错误;
2)日输入[1日]--OK;
3)日输入[32日]--程序应提示错误;
4)月输入[1、3、5、7、8、10、12月]、日输入[31日]--OK;
5)月输入[4、6、9、11月]、日输入[30日]--OK;
6)月输入[4、6、9、11月]、日输入[31日]--程序应提示错误;
7)输入非闰年,月输入[2月]、日输入[28日],比如2009.2.28--OK;
8)输入非闰年,月输入[2月]、日输入[29日],比如2009.2.29--程序应提示错误;
9)(闰年)月输入[2月]、日输入[29日],比如2008.2.29--OK;
10)(闰年)月输入[2月]、日输入[30日],比如2008.2.30--程序应提示错误;
12)月输入[1月]--OK;
13)月输入[12月]--OK;
14)月输入[13月] --程序应提示错误;
格式检查:
1)不合法格式:2009-09、 2009-09 -、200-2-2;
2)视具体项目而定是否合法:2009/09/01、2009.09.01 、20090901、2009-09-01 ;
异常值、特殊值:
1)输入汉字、字母、字符--程序应提示错误;
<!--[if !supportLists]-->4. <!--[endif]-->文本框为时间型
合法性检查:
1)时输入[24时] --程序应提示错误;
2)时输入[00时] --OK;
3)分输入[60分] --程序应提示错误;
4)分输入[59分] --OK;
5)分输入[00分] --OK;
6)秒输入[60秒] --程序应提示错误;
7)秒输入[59秒] --OK;
8)秒输入[00秒] --OK;
格式检查:
1)不合法格式:12:30:、 123000;
2)视具体项目而定是否合法:12:30、 1:3:0;
异常值、特殊值:
1)输入汉字、字母、字符--程序应提示错误;
2)系统中所涉及时间是否取服务器时间;
三、上传和导出公共测试用例
<!--[if !supportLists]-->1. <!--[endif]-->上传图片
对于上传的文件,假设系统要求上传的文件为jpg或gif格式图片,大小为<=5M的文件,我们在设计测试用例时,应该从以下几个方面进行考虑:
1)文件类型正确,文件大小合适的校验
例如:上传一种jpg或gif的格式图片,文件大小为4.9M,结果为上传成功
2)文件类型正确,文件大小合适的校验
例如:上传一种jpg或gif的格式图片,文件大小为5M,结果为上传成功
3)文件类型正确,文件大小不合适的校验
例如:上传一种jpg或gif的格式图片,文件大小为5.1M,提示为:“上传的附件中大小不能超过5M”
4)文件类型错误,文件大小合适的校验
例如:上传.doc、.xls、ppt、bmp、jpeg、psd、tiff、tga、png、swf、svg、pcx、dxf、wmf、emf、lic、eps、.txt等格式文件,文件大小合适,提示“只能上传jpg或gif格式图片”
5)文件类型和文件大小合法,上传一个0kb的图片,提示信息:“请重新上传文件,或者是不能上传0kb的图片”
6)文件类型和文件大小合法,上传一个正在使用中的图片(即打开该图片,再上传该图片),上传成功
7)文件类型和文件大小合法,手动输入一个存在的图片地址,点击上传,上传成功
8)文件类型和文件大小合法,手动输入一个不存在的图片地址,点击上传,提示:“请正确选择要上传的文件”
9)文件类型和大小都合法,手动输入一个存在的图片名称,点击上传,一般情况下系统会提示:“请正确选择要上传的文件的路径”
<!--[if !supportLists]-->2. <!--[endif]-->文件导出
1)验证导出文件名长度,根据具体情况而定
2)验证导出文件为空的情况
3)验证导出文件名为特殊字符的情况
4)验证导出全部资料的情况,导出的信息是否正确
5)验证导出部分资料的情况,导出的信息是否正确
6)验证导出大量数据时的时间是否在合理的时间范围内
7)验证导出目的磁盘空间已满的情况下,导出是否有友好的处理方式
8)验证导出目的的文件夹为只读的情况下,导出时是否有友好的的提示信息
<!--[if !supportLists]-->3. <!--[endif]-->文件上传
页面
1)页面美观性、易用性(键盘和鼠标的操作、tab跳转的顺序是否正确)
2)按钮文字正确性
3)说明文字是否正确
4)正确/错误的提示文字是否正确
5)提示当前位置是否正确,并且和其他页面保持一致格式
6)必添项的标示是否正确
功能
1)路径是否可以手工输入(手工输入的时候有没有限长)
2)上传文件超过最大值是在提交前校验还是提交后校验
3)上传文件格式是否全部支持(图片:gif/jpg/bmp...文档:doc/sxw/xls...压缩包:zip/rar...安装文件:exe/msi)
4)上传文件是否支持中文名称
5)文件名称的最大值、最小值、特殊字符(包含空格)、使用程序语句是否会对其造成影响、中文名称是否能正常显示
<!--[if !supportLists]-->4. <!--[endif]-->文件下载
功能
1)右键另存为是否可以正确下载文件,并且记录下载次数
•工具下载是否正确,并且记录下载次数
2)单击下载是提示下载还是在页面打开
•直接打开是否显示正确
•对于本机没有安装工具的文件是否能够打开,是否能给出正确的提示
•对于直接在页面内打开的内容是否能够显示正常,页面美观性
•保存到本地是否能正确显示• 取消下载是否会纪录下载次数
3)下载次数是否被正确记录
四、列表公共测试用例
<!--[if !supportLists]-->1. <!--[endif]-->列表页面显示
1)确认页面的默认排序方式,字段+升降续;
2)含link的列,验证其有效性,即,点击后的跳转是否正确;
3)第一列的选择框,“全选”和“部分选择”需有效;部分选中时,全选按钮应自动取消。
<!--[if !supportLists]-->2. <!--[endif]-->顶部搜索功能
1)逐个测试每个搜索条件的有效性;
2)做2-3个组合条件的查询,验证结果;合计共有N+3个搜索条件的测试。
3)有时间区间的,验证列表项的开始到结束时间和选择区间有交叉,则为有效,且包含所选日期的记录;
4)条件中,开始时间不能大于结束时间;
5)搜索条件,在分页显示时,需始终保持有效;
6)点击名为“显示全部”的按钮,需清除所有条件,并显示所有记录。
7)每一次新的搜索执行,都应该去除分页,显示第一页、并回到进入页面时的默认排序方式。
<!--[if !supportLists]-->3. <!--[endif]-->右侧或底部的按钮
按功能分成多个用例:
1)单选,多选、全选的情况下,点击按钮执行某个功能,如暂停服务、恢复服务的按钮;
2)跨页选择,在一些选择成员的列表中是应有效的,需进行确认。
<!--[if !supportLists]-->4. <!--[endif]-->列表数据的验证
验证从数据库中得到的列表项中每列数据的正确性,要求覆盖不同情况下的值,比如“开通”、“暂停”的服务状态;已使用空间大小和总空间大小等数字的正确性。可考虑结合其他用例来描述,但必须覆盖到。
<!--[if !supportLists]-->5. <!--[endif]-->列表按标题的排序
1)检查每个列标题,要求点击后能按其进行排序:第一次点击为正序,以后每次点击为升、降续的切换。
2)进入下一页、上一页,以及任意分页显示时,条件需始终保持有效。
<!--[if !supportLists]-->6. <!--[endif]-->分页
1)“第2页/共8页每页 10条/共 79条”中的分页数据必须正确;
2)第一页、上一页、下一页、最后一页的link在当前上下文有意义时显示,否则隐藏或显示为文本标签;
3)填入某个数字,点击“跳转到”按钮,到正确的页数;
另外请考虑每个文本框输入的有效性,比如日期、域名、跳转到某页的文本框的能接受的值,具体可参考需求文档。
Web测试需要注意点
2012-01-19 15:09:37| 分类: 测试人生 | 标签: |字号大中小 订阅
一、功能测试
测试用例是测试的核心,测试用例的设计是一种思维方式的体现,在用例的设计中,用的比较多的方法是边界值分析法和等价类划分法,下面主要从输入框,搜索功能,添加、修改功能,删除功能,注册、登录功能以及上传图片功能等11个方面进行总结说明。
1、输入框
输入框是测试中最容易出现bug的地方,所以在测试时,一定要多加注意。
输入框 | 字符型输入框 | 字符种类 | 英文全角字符 |
英文半角字符 |
数字 |
汉字 |
空或空格 |
特殊字符“~!@#$%^&*()_+-={}[]|\:;”’<>,./?;”等可能导致系统错误的字符,特别要注意单引号和&符号。 |
禁止直接输入特殊字符时,使用“粘贴”、“拷贝”功能尝试输入,并测试能否正常提交保存。 |
长度检查 | 最小长度-1 |
最小长度 |
最大长度 |
最大长度+1 |
输入超长字符:比如把整篇word文档copy过去 |
空格检查 | 输入的字符间有空格 |
字符前有空格 |
字符后有空格 |
字符前后都有空格 |
多行文本框输入 | 允许回车换行 |
保存后再显示能够保持输入时的格式 |
仅输入回车换行,检查能否正确保存;若能,查看保存结果。若不能,查看是否有正确提示 |
安全性检查 | 输入特殊字符串:null、NULL、 、javascript、<script>、</script>、<title>、<html>、<td>等 |
输入脚本函数:<script>alter("abc")</script>、document.write("abc")、<b>hello</b> |
数值型输入框 | 边界值 | 最小值-1 |
最小值 |
最大值 |
最大值+1 |
位数 | 最小位数+1 |
最小位数 |
最大位数 |
最大位数+1 |
输入超长值 |
异常值、特殊值 | 输入[空白(NULL)]、空格或‘“~!@#$%^&*()_+-={}[]|\:;”’<>,./?;”等可能导致系统错误的字符 |
禁止直接输入特殊字符时,使用“粘贴”、“拷贝”功能尝试输入,并测试能否正常提交保存。 |
word中的特殊功能,通过剪贴板拷贝到输入框:分页符,分节符,类似公式的上下标等 |
输入负整数、负小数、分数 |
输入字母或汉字 |
带符号的数值:带正号的正数,带负号的负数 |
小数:小数点前零舍去的情况,如.12;多个小数点的情况;0值:0.0,0.,.0 |
首位为零的数值:如01、02 |
科学技术法是否支持:如 1.0E2 |
全角数字和半角数字的情况 |
数字与字母的混合:16进制数值,8进制数值 |
货币型输入项:允许小数点后几位 |
安全性检查同上 | 不能直接输入,就copy |
日期型 | 合法性检查 | 日输入[0日] |
日输入[1日] |
日输入[32日] |
月输入[1、3、5、7、8、10、12月]、日输入[31日] |
月输入[4、6、9、11月]、日输入[30日] |
月输入[4、6、9、11月]、日输入[31日] |
输入非闰年,月输入[2月]、日输入[28日] |
输入非闰年,月输入[2月]、日输入[29日] |
(闰年)月输入[2月]、日输入[29日] |
(闰年)月输入[2月]、日输入[30日] |
月输入[0月] |
月输入[1月] |
月输入[12月] |
月输入[13月] |
异常值、特殊值 | 输入[空白(NULL)]或“~!@#$%^&*()_+-={}[]|\:;”’<>,./?;”等可能导致系统错误的字符 |
安全性检查同上 | |
2、搜索功能
(1)比较长的名称是否能查到?
(2)空格 或空
(3)名称中含有特殊字符,如:' $ % & *以及空格等
(4)关键词前面或后面有空格
(5)如果支持模糊查询,搜索名称中任意一个字符是否能搜索到
(6)输入系统中不存在与之匹配的条件
(7)两个查询条件是否为2选1,来回选择是否出现页面错误
(8)输入脚本语言,如:<script>alter(“abc”)</script>等
3、添加、修改功能
(1)是否支持tab键
(2)是否支持enter键
(3)不符合要求的地方是否有错误提示
(4)保存后,是否也插入到数据库中?
(5)字段唯一的,是否可以重复添加
(6)对编辑页列表中的每个编辑项进行修改,点击保存,是否保存成功?
(7)对于必填项,修改为空、空格或其他特殊符号,是否可以编辑成功
(8)在输入框中,直接回车
(9)是否能够连续添加
(10)在编辑的时候,要注意编辑项的长度限制,有时,添加时有长度限制,但编辑时却没有(添加和修改规则是否一致)
(11)添加时,字段是唯一的,不允许重复,但有时,编辑时,却可以修改为相同字段(相同字段包括是否区分大小写以及在输入内容的前后输入空格)
(12)添加含有特殊符号或空格的内容
(13)对于有图片上传功能的编辑框,对于没有上传的图片,查看编辑页面时,是否显示默认图片,如果上传了图片,是否显示为上传图片?
4、删除功能
(1)输入正确数据前加空格,看是否能正确删除?
(2)是否支持enter键
(3)是否能连续删除多个产品?当只有一条数据时,能否成功删除?
(4)删除一条数据后,能否再添加相同的数据?
(5)当提供能一次删除多条信息的功能时,注意,删除的数据是否正确?
(6)不选择任何信息,直接点击删除按钮,看有什么错误提示?
(7)删除某条信息时,应该有错误提示信息
5、注册、登录模块
(1)注册成功,但登录失败:注册时,密码设置为一些特殊符号,但登录时,失败
(2)注册时,连续点击提交按钮
(3)注册成功后,页面应该以登录状态跳转到首页
(3)登录时,没区分大小写,注册时,是小写字母,但登录时,用大写字母也能登录进去
(4)登录时,当页面刷新或重新输入新数据时,验证码是否也随之更新
(5)对密码的修改,当把密码修改为很长,或含有特殊符号时,能够修改成功,但却不能成功登录。
6、上传图片测试
(1)文件类型正确,文件大小合适
(2)文件类型正确,文件大小不合适
(3)文件类型错误,文件大小合适
(4)文件类型和大小都合适,上传一个正在使用中的图片
(5)文件类型和大小合适,手动输入一个存在的图片地址来上传
(6)文件类型和大小合适,手动输入一个不存在的图片地址上传
(7)文件类型和大小都合适,手动输入图片名称来上传
7、返回键检查
(1)一条已经成功提交的记录,返回后再提交,看系统是否做了处理
(2)检查多次使用返回键的情况,在有返回键的地方,返回到原来页面重复多次,看是否会出错
8、回车键检查
在输入结束后,直接按回车键,看系统处理如何,是否会报错
9、刷新键检查
在web系统中,使用浏览器的刷新键,看系统处理如何,是否会报错
10、直接URL链接检查
在web系统中,直接输入各功能页面的URL地址,看系统如何处理
11、其他
(1)在测试时,有与网络有关的步骤必须考虑到断网的情况
(2)每个页面都有相应的页面title
(3)在测试的时候要尽量考虑在页面出现滚动条时(滚动条上下滚动下),页面显示是否正常
(4)URL不区分大小写
12、测试中,并发情况的考虑
总结了以下两种情况:
(1)某个字段是唯一的,当多个用户并发点击产生该字段时,检查系统是怎么处理的
(2)对于电子商务网站,当两个或多个用户并发购买量总和大于产品库存量时,能否购买成功
二、界面和易用性测试
1、界面测试,主要测试网站的界面是否和设计一致,是否有错别字,页面布局是否合理,格式是否正确,是否有相应的错误提示信息等。
2、易用性测试,主要是考察所开发出的功能是否人性化,是否易用,是否符合大多数用户的使用习惯等。
3、对Tab和Enter键的测试。
三、兼容性测试
兼容性测试不只是指界面在不同操作系统或浏览器下的兼容,有些功能方面的测试,也要考虑到兼容性,比如涉及到ajax、jquery、javascript等技术的,都要考虑到不同浏览器下的兼容性问题。
四、链接测试
主要是保证链接的可用性和正确性,它也是网站测试中比较重要的一个方面。
五、业务流程测试
业务流程,一般会涉及到多个模块的数据,所以在对业务流程测试时,首先要保证单个模块功能的正确性,其次就要对各个模块间传递的数据进行测试,这往往是容易出现问题的地方,测试时一定要设计不同的数据进行测试。
六、安全性测试
(1)SQL注入
(2)XSS跨网站脚本攻击:程序或数据库没有对一些特殊字符进行过滤或处理,导致用户
所输入的一些破坏性的脚本语句能够直接写进数据库中,浏览器会直接执行这些脚本语句,破坏网站的正常显示,或网站用户的信息被盗,构造脚本语句时,要保证脚本的完整性。
document.write("abc")
<script>alter("abc")</script>
(3)URL地址后面随便输入一些符号
(4)验证码更新问题
web测试中容易忽略的问题
很多时候,基于需求的测试和针对web特有的浏览器兼容性测试、cookie失效的验证,对于测试人员并不陌生。但实际上,与浏览器相关的测试内容远不止这些。
举一个例子来说,很多时候我们都非常明确页面上的所有入口,并对这些入口设计了大量的用例,而浏览器的地址栏却常常会被我们忽略。实际上,url的输入意义远比我们意识中的重要,忽略了url的测试,很容易造成安全上的隐患。
再进一步的说,浏览器的前进、后退、刷新按钮同样是测试人员需要关注的点。前进、后退在用户登录、注销信息的测试中应用最为频繁。而刷新,往往容易被忽视,但其同样是bug的“温床”。在最近的一次测试中,我就遇到过在我删除某条记录系统提示删除成功后,点击“刷新”按钮,页面提示出错的情况。出现该现象的原因就在于页面试图去取已删除的内容,导致出现异常。其实这个问题应该隐藏了比较久的时间,但是却一直未被发现,足可见我们都忽视了“刷新”的测试。
除了上述的内容外,我相信一定还存在很多我们在测试中忽视的内容,而这些点的补充,是我们每一个人的责任!
<!--[if !supportLists]--> 1、<!--[endif]--> 相关性检查:
增加/删除一些功能,是否对其他项有影响;
增加某个数据项后,该数据某字段内容过长,查询显示回事数据列表变形;
字符串长度、类型检查。
<!--[if !supportLists]--> 2、<!--[endif]--> 标点符号检查:
把空格键当成一个字符处理,但查询时空格被屏蔽,查询不到添加的内容;
查询时输入特殊字符“_”,程序返回所有记录。
<!--[if !supportLists]--> 3、<!--[endif]--> 检查添加与修改是否一致:
添加要求必填项,修改也应该是必填项
<!--[if !supportLists]--> 4、<!--[endif]--> 脚本错误(IFrame,JS,Ajax)易造成浏览器兼容性问题
<!--[if !supportLists]--> 5、<!--[endif]--> 查询列表,如果有重复信息(distinct)去重
<!--[if !supportLists]--> 6、<!--[endif]--> 登录信息,cookies缓存保留
<!--[if !supportLists]--> 7、<!--[endif]--> JS格式控制验证处理,注意验证条件,验证未知,触发时间及验证的必要性
软件测试中常见问题分类说明
<!--[if !supportLists]--> 一、 <!--[endif]--> 规范化问题
包括软件规范和业务规范两大类,软件规范问题主要指操作过程中显而易见的错误或缺陷,非人性化设计、友好度较差等;业务规范问题主要指使用非标准或非惯例的业务术语、以及概念错位等。
㈠ 软件规范问题
<!--[if !supportLists]-->1、<!--[endif]-->操作指示不明确
提示存在二意性、提示操作项 “忽略”、“取消”、“退出”等含义不明确。 (轻度)
<!--[if !supportLists]-->2、<!--[endif]-->简单界面规范问题
①按钮图片丢失、按钮图片不配套、按钮大小排列不美观; (轻度)
②在引用数据窗口的下拉框中,没有根据实际数据来调整下拉框显示的%的大小和垂直滚动条,导致文本只显示了一部分; (一般)
③界面中存在色块; (轻度)
④菜单排列顺序有误; (轻度)
⑤窗体最小化以后在屏幕上找不到了,无法恢复原窗体; (轻度)
<!--[if !supportLists]-->3、<!--[endif]-->操作过程缺乏人性化考虑
①选项过于烦琐且不必要、设置不合适导致使用者遗漏、常规按钮排列顺序不一致 (轻度)
②常用功能不支持键盘操作。 (一般)
③单据处理中当由于存在空行时,提示用户输完其余内容,而没有自动删除空行。 (一般)
<!--[if !supportLists]-->4、<!--[endif]-->帮助文件规范问题
①联机帮助字体、背景风格不统一; (细微)
②点击“ ?”按钮打开帮助文件,没有直接定位到内容; (细微)
③内容定位错误; (轻度)
④帮助文件内部链接没有做全; (细微)
⑤文档内容排版错误; (一般)
⑥其他帮助错误。 (轻度)
5、软件风格规范问题
①控件的切换顺序有误、DataWindow的切换顺序有误;
(视控件使用频繁程度设为 (一般)和 (轻度))
②DataWindow内容的对齐方式不正确(数值右对齐、日期中对齐、文字左对齐); (细微)
③数值的EditMask(掩膜)设置有误、日期的EditMask(掩膜)设置有误、日期的默认格式非YYYY.MM.DD、默认日期存在1900.00.00现象或其他不合理的值 (轻度)
④弹出窗口不在屏幕中间位置、退出系统缺少提示; (细微)
⑤重大操作(月结、恢复、修复等)缺少提示、重大操作没有自动弹出备份提示; (轻度)
⑥快捷按钮定义不准确、快捷字母或数字重复、工具栏快捷键定义错误 (轻度),工具栏常用快捷键缺少 (细微);
⑦违反窗口录入标准(一般可录入内容为白底蓝字、不可录入内容为白底黑字或灰底)、主窗口关闭后未关闭下属窗口; (轻度)
⑧进入界面缺少焦点、焦点位置不合理、回车键切换焦点顺序错误、记录或条件选择不方便; (一般)
⑨窗口标题、版本号、版权标识、系统图片不统一; (细微)
⑩补丁、紧急放行版未加PN号; (细微)
⑾存在无明显用途或不必要的消息窗。 (轻度)
㈡业务规范问题
<!--[if !supportLists]-->1、<!--[endif]-->业务术语规范问题
概念偷换、业务名词混用、业务术语出现错别字、生造业务术语、同一功能指向使用不同术语、多个功能指向使用同一术语。 (轻度)
<!--[if !supportLists]-->2、<!--[endif]-->操作提示用语不规范
缺少必要的提示、提示语句描述不规范、语序随意、叙述风格不统一、口语化、对操作的必然后果或可能产生的后果没有提示、提示有误。 (轻度)
3、用例错误
引用业务规范错误、引用政策法律相关数据过时、引用相关公式错误、报表格式不符合业务规范或过时、报表或查询窗口中条目或款项设计不全导致信息失真或不可用。 (严重)
4、默认设置不规范
数量或金额长度不符合日常应用、默认编码方案不可行或不科学、系统建表后自动插入的数据错误、各种默认的数据或编码体系彼此不统一。 (一般)
<!--[if !supportLists]--> 二、 <!--[endif]--> 常规录入错误
主要指数据录入、修改、保存、删除等常规操作过程中出现的各类弹出式出错信息,数据控制疏漏、数据编辑无效、设置无效等。
㈠ 数据编辑无效
1、由于建表失败导致的无法设置现象。 (严重)
2、各种设置完成后立即查询发现设置有不符现象。 (一般)
3、数据编辑保存后,在其他相关功能中查询此数据,不符。 (严重)
4、数据经过变动、保存后,在其他功能中查询,变动没有及时体现。 (严重)
5、出现如“按!定位”等变量没有替换的错误、定位或搜索不可用。 (一般)
㈡ 出现Data Window Error
1、出现主键冲突导致的错误提示。(试图存入已存在的代码,数据库弹出提示未被程序接管。) (一般)
2、由于字段类型和赋值范围控制疏漏导致的Data. Window Error。(录入界面允许n+m位,字段实际宽度为n位,或由于数值掩膜设置出错导致数据库弹出错误提示未被程序接管。) (一般)
3、由于建表错误导致数据无法保存产生Data. Window Error。 (严重)
4、在同一操作界面中反复进行修改、查询、删除等编辑操作使驻留内存的数据与数据库中的数据不对应导致的Data Window Error。 (一般)
5、极限数据录入产生的Data Window Error。 (一般)
6、其他操作出现的Data Window Error。 (一般)
㈢ 出现非法操作提示(WIN98)或应用程序错误提示(WIN2000)
1、报表或查询的条件录入中由于使用%、(、)等特殊符号产生的非法操作提示。 (轻度)
2、对某一功能、某一组功能的常规操作出现非法操作提示。 (严重)
3、对某几个功能的组合操作、或一个功能较复杂的应用出现非法操作提示。 (一般)
㈣ .NET错误
包含所有的Microsoft Visual Studio .NET 2003 Error、或表现为“第××行代码错误”的提示。此类提示在程序任何地方都可能出现。(普通操作就出现的 (严重),复杂操作出现的 (一般)
㈤ 残留的编译信息未及时清除
主要是开发员在开发过程中方便观察程序运行状态而留下的一些提示窗口,表现形式往往是弹出一个或几个标注感叹号( !)、问号( ?)的消息框。 (一般)
㈥ 出现WINDOWS 系统提示
比如:文件删除失败、内存不够、无法执行此项任务、Out of Memory等 (严重)
㈦ 系统停止响应
在没有并发操作的前提下出现程序停止响应状况、或者长时间停顿,需要点击Ctrl+Alt+Delete中止的现象 (海量数据恢复除外)。 (严重)
㈧ 非正常的失败或操作错误提示
1、操作过程中出现本不应该有的失败提示,如“数据库已被改乱,请到核算单位重新再建”、“数据保存失败”、“处理失败,请重试”等 (严重)
2、提示与出错的实际原因牛头不对马嘴,实际是A错误,显示B提示。 (一般)
<!--[if !supportLists]-->三、<!--[endif]-->流程错误
主要指程序运行过程中由于需求分析、功能设计中对产品功能缺少深入的考虑、或者在编码过程中的疏漏等原因,产生的逻辑控制错误或失败、数据控制错误等。
㈠ 逻辑控制错误
1、初始通过时没有自动检测初始化设置的核心内容、或者检测错误。 (严重)
2、该禁止的操作流程未被禁止、不该禁止的操作流程被禁止。 (严重)
3、对已使用的条款、或存在记录的类别可以作删除操作。(如删除有固定资产的部门、删除已有员工发薪的员工大类等)。 (严重)
4、编码缺少必要的分级政策,直接导致后面流程取数及统计工作的正确性。 (严重)
5、数据恢复前未强行关闭当前工作窗口。 (严重)
6、初始化前事关流程走向的选项在初始化完成后仍旧可以改动。 (严重)
7、流程环节设计不合理、不规范。 (一般)
8、流程设计缺少重要的数据出口。
9、对应可能出现的流程中意外情况,缺少可行的解决办法。(如不支持作废、重开、冲红等)。 (一般)
10、设计中对特定的流程及相应的单据缺乏检查、追踪及统计的功能。 (一般)
11、单据的处理流程前后因果关联错误。(如修改、审核、删除、作废之间的关系) (严重)
12、公式设置出现闭环、或几个公式间出现互为因果的现象,而能够设置成功。 (严重)
13、公式保存没有必要的合法性检查。 (一般)
14、短期使用版未控制 (严重)或控制时间过长 (一般)、正版有时间限制 (严重)。
15、软件无法安装或安装失败。 (严重)
㈡ 数据控制错误
1、取上一环节数据出错。 (严重)
2、下一环节取数后反填错误。未将所取的值记录下、未加上已取数的状态标志,出现统计出错、取数无限制、无法继续取剩余值等错误。 (严重)
3、下一环单据变动后反填错误。如对于单据删除、作废、修改等变动,上一环节未同步变动。 (严重)
4、公式设置出现闭环。 (一般)
5、公式计算出错。 (严重)
6、单据录入四舍五入错误。 (严重)
7、上下流单据处理中四舍五入错误。(如订单开提货单、提货单开发票等一对一、一对多处理过程。) (严重)
<!--[if !supportLists]-->四、<!--[endif]-->报表和查询出错
1、报表取数错误。 (严重)
2、对报表进行过滤、筛选等操作,出现数据错误。 (一般)
3、报表分级汇总错误。 (严重)
4、报表分类统计错误。 (严重)
5、报表非数据元素显示错误。(如表头、制表日期、相关部门等) (一般)
6、项目属性修改导致统计错误。(比如业务员的部门转移、部门的调整、固定资产摊销部门的变化等统计条件变更导致计算错误。) (严重)
7、部分报表可以通过单击字段名排序,在此过程中出现的界面刷新错误、合计汇总错误等。 (一般)
8、表与表之间同种指标数据不统一。(由于统计口径不同导致。) (一般)
9、初始数据未计算到相关报表。 (一般)
10、报表数据四舍五入错误。
①由单据(或其他数据录入界面)汇总计算而来。 (一般)
②从其他报表取数或计算而来。 (一般)
③报表自身元素计算而来。 (严重)
11、对报表某一记录、元素深入查询出错。(比如在总表下查询明细表等,主要针对报表界面中的其他查询按钮) (严重)
<!--[if !supportLists]-->五、<!--[endif]-->打印及打印相关操作错误
在程序中,用到打印功能的相当多,由于许多打印用类库处理,因此错误有较大的相似性,打印相关操作主要涉及打印机设置、打印字体设置、宽度设置、纸张设置。打印包括打印预览、套打、分页打印、满页打印、普通打印等
㈠ 打印相关操作出错。
1、打印机及打印纸设置有误。 (一般)
2、打印页面参数设置无效。 (轻度)
3、打印页面参数保存无效。 (轻度)
4、打印格式选择无效。 (一般)
5、套打格式设置无效。 (一般)
6、打印效果转换输出无效。 (轻度)
7、打印标题及表头、表尾设置无效或错误。 (一般)
8、同样的内容在不同打印机上显示效果不同(指数据正确的前提下) (细微)
㈡ 打印预览和打印问题
通常情况下,打印预览和打印的现象是一致的,如果非特殊指明的,下面的问题包含打印及预览两个方向。(所有打印必须在两种或两种以上打印机上通过测试。)
1、表头消失或错位。 (轻度)
2、表格线不全。 (细微)
3、信息打印表格出边界、打印内容有重叠效果。 (一般)
4、打印标题与报表查看不一致。 (轻度)
5、报表打印时其他信息与查看不一致。 (轻度)
6、存在焦点时,打印效果异常。(比如选中区域为黑色、焦点不能预览或打印。) (细微)
7、打印预览工具条和查看窗口操作后切换有问题。(如停止响应等) (细微)
8、查看窗口退出后,打印工具条仍然可以使用。 (细微)
9、实际打印时跳行、走纸。 (一般)
10、打印预览中能够编辑。 (细微)
11、页码打印错误。 (轻度)
12、打印实际效果与预览有差异。 (细微)
13、满页打印错误。 (一般)
14、鼠标拖拉报表列头使之调整宽度、或隐藏某列后预览及打印效果出错。 (细微)
15、同样的内容在不同打印机上显示效果不同(指数据正确的前提下) (细微)
16、先预览后打印和直接打印数据或内容不同 (严重)
<!--[if !supportLists]-->六、<!--[endif]-->接口及数据转移中的问题
1、各模块之间生成单据错误。 (严重)
2、各模块之间可以重复取数、或放弃取数(取数失败)后不能再取 (严重)
3、各模块交叉查询数据出错。 (严重)
4、各模块之间传入传出、导入导出、汇入汇出错误。(数据传出与导入效果不同) (严重)
5、传出到第三方的数据格式不符合要求。 (一般)
6、第三方数据导入不能完全接收、或接收错误。 (严重)
<!--[if !supportLists]-->8、<!--[endif]-->切换网络服务器过程中产生的错误。 (一般)
<!--[if !supportLists]-->9、<!--[endif]-->不同数据库之间的数据查询失败或错误。 (严重)
<!--[if !supportLists]-->10、<!--[endif]-->其他网络、数据库之间通讯失败。 (一般)
<!--[if !supportLists]-->七、<!--[endif]-->权限及安全问题
1、匿名登录成功。 (严重)
2、明码登录。 (严重)
3、重大系统操作不强制重新登录。(如恢复数据完成、切换年度、年结完成等) (严重)
4、对不可逆的操作缺少安全性提示。(如改动资产月末计提) (一般)
5、没有遵循逐级授权的原则。 (细微)
6、权限设置中存在互为因果的同级项目、存在逻辑错误。 (一般)
7、某操作员没有某权限,但依然能够进行该种操作。 (一般)
8、只有针对一部分对象的权限,但能够进行全部对象的操作。(如部门权限失效等) (轻度)
9、只有查询权的情况下,可以编辑成功。 (一般)
10、没有某权限,但通过快捷菜单能够绕开。 (轻度)
11、对权限进行多种组合,出现控制出错的现象。 (轻度)
12、默认状态下权限设置不合理。 (细微)
13、数据成批处理没有考虑到与权限设置存在冲突。 (轻度)
14、缺少必要的权限。 (严重)
15、备份出来的数据未经压缩或加密,利用计事本就可以打开文件查阅信息。 (一般)
<!--[if !supportLists]-->八、<!--[endif]-->备份与恢复问题
1、极限宽度的数据备份恢复失败。 (严重)
2、备份恢复数据比较,设置内容不正确。 (严重)
3、备份恢复数据比较,存在记录丢失现象。 (严重)
4、在各个数据库中,数据小数位长度不一。 (严重)
5、数据库中原有数据的,恢复后部分数据未覆盖。 (严重)
6、备份恢复过程中产生其他出错信息。 (严重)
7、集中备份恢复与普通备份恢复结果不同。 (严重)
8、大数据量备份恢复记录条数丢失。 (严重)
<!--[if !supportLists]-->九、<!--[endif]-->并发问题
并发错误指两人或多人同时对同一流程、同一单据(或相关流程、相关单据)操作所引起的存取错误、系统停止响应等问题。 (视相关单据和流程的重要性和并发操作的可能性划分问题严重程度)
1、多人同时录入同类单据,出现单据号重复现象或出错提示。
2、多人同时对同一张单据进行同一流程处理,出现数据控制失败现象或出错提示。
3、多人同时对同一单据作不同操作(如审核、修改、删除、作废等),出现控制失败或出错提示。
4、按上问题,继续查询此单据,出现错误提示。
5、多人同时录入、编辑同一记录,出现出错信息、或数据保存错误。<!--[if gte vml 1]><v:shapetype
id="_x0000_t202" coordsize="21600,21600" o:spt="202" path="m,l,21600r21600,l21600,xe"><v:stroke joinstyle="miter"/><v:path gradientshapeok="t" o:connecttype="rect"/></v:shapetype><v:shape id="_x0000_s1042" type="#_x0000_t202" style='position:absolute;
left:0;text-align:left;margin-left:275.1pt;margin-top:596.75pt;width:37.65pt;
height:19pt;text-indent:0;z-index:251661312;
mso-position-horizontal-relative:text;mso-position-vertical-relative:text'
stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1042'/></v:shape><![endif]--><!--[if !vml]-->
<!--[endif]--><!--[if !mso]-->| <!--[endif]--><!--[if !mso]--> |
<!--[endif]--><!--[if !mso & !vml]--> <!--[endif]--><!--[if !vml]--> |
6、由于并发产生的提示错误。
7、在不同流程(不同单据)的同步处理中,由于操作涉及同一数据(表)导致的并发问题。
8、在不同模块的操作中,由于操作涉及同一数据(表)导致的并发问题。(如销售和库存同时调取存货结存数量)
<!--[if gte vml 1]><v:group
id="_x0000_s1026" style='position:absolute;left:0;text-align:left;
margin-left:62.75pt;margin-top:11.45pt;width:220.75pt;height:170.25pt;
z-index:251660288' coordorigin="2389,11970" coordsize="4267,3230"><v:line id="_x0000_s1027" style='position:absolute;flip:y' from="3393,12160"
to="3393,14440"><v:stroke endarrow="block"/></v:line><v:group id="_x0000_s1028" style='position:absolute;left:2389;top:11970;
width:4267;height:3230' coordorigin="2389,11970" coordsize="4267,3230"><v:line id="_x0000_s1029" style='position:absolute' from="3393,14440" to="6656,14440"><v:stroke endarrow="block"/></v:line><v:group id="_x0000_s1030" style='position:absolute;left:2389;top:11970;
width:4016;height:3230' coordorigin="2389,11970" coordsize="4016,3230"><v:rect id="_x0000_s1031" style='position:absolute;left:3393;top:14440;
width:3012;height:760' filled="f" stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1031'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><span style='font-size:9.0pt;font-family:楷体_GB2312;
mso-ascii-font-family:"Times New Roman"'>低</span><span lang=EN-US
style='font-size:9.0pt'><span style='mso-spacerun:yes'>
</span></span><span style='font-size:9.0pt;font-family:楷体_GB2312;
mso-ascii-font-family:"Times New Roman"'>中</span><span lang=EN-US
style='font-size:9.0pt'><span style='mso-spacerun:yes'> </span></span><span
style='font-size:9.0pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman"'>高</span><span
lang=EN-US style='font-size:9.0pt'><o:p></o:p></span></p><p class=MsoNormal><span style='font-family:楷体_GB2312;mso-ascii-font-family:
"Times New Roman"'>重要性</span><span lang=EN-US><o:p></o:p></span></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:rect><v:rect id="_x0000_s1032" style='position:absolute;left:2389;top:11970;
width:1255;height:2470;rotation:180' filled="f" stroked="f"><v:textbox style='layout-flow:vertical;mso-layout-flow-alt:bottom-to-top;
mso-next-textbox:#_x0000_s1032'><![if RotText]><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal style='text-indent:70.0pt;mso-char-indent-count:5.0'><span
style='font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman"'>可能性</span><span
lang=EN-US><span style='mso-spacerun:yes'> </span></span><span
style='font-size:10.5pt;font-family:楷体_GB2312;mso-ascii-font-family:
"Times New Roman"'>低</span><span lang=EN-US style='font-size:10.5pt'><span
style='mso-spacerun:yes'> </span></span><span style='font-size:
10.5pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman"'>中</span><span
lang=EN-US style='font-size:10.5pt'><span style='mso-spacerun:yes'>
</span></span><span style='font-size:10.5pt;font-family:楷体_GB2312;
mso-ascii-font-family:"Times New Roman"'>高</span> <span lang=EN-US><o:p></o:p></span></p></div><![if !mso]></td></tr></table><![endif]><![endif]></v:textbox></v:rect><v:shape id="_x0000_s1033" type="#_x0000_t202" style='position:absolute;
left:3644;top:13870;width:753;height:380' stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1033'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><b style='mso-bidi-font-weight:normal'><span
style='font-size:9.0pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman";
color:red'>细微</span></b><b style='mso-bidi-font-weight:normal'><span
lang=EN-US style='font-size:9.0pt;color:red'><o:p></o:p></span></b></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:shape><v:shape id="_x0000_s1034" type="#_x0000_t202" style='position:absolute;
left:5652;top:12160;width:753;height:380' stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1034'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><b style='mso-bidi-font-weight:normal'><span
style='font-size:9.0pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman";
color:red'>严重</span></b><b style='mso-bidi-font-weight:normal'><span
lang=EN-US style='font-size:9.0pt;color:red'><o:p></o:p></span></b></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:shape><v:shape id="_x0000_s1035" type="#_x0000_t202" style='position:absolute;
left:4648;top:12160;width:753;height:380' stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1035'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><b style='mso-bidi-font-weight:normal'><span
style='font-size:9.0pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman";
color:red'>严重</span></b><b style='mso-bidi-font-weight:normal'><span
lang=EN-US style='font-size:9.0pt;color:red'><o:p></o:p></span></b></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:shape><v:shape id="_x0000_s1036" type="#_x0000_t202" style='position:absolute;
left:5652;top:13110;width:753;height:380' stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1036'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><b style='mso-bidi-font-weight:normal'><span
style='font-size:9.0pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman";
color:red'>严重</span></b><b style='mso-bidi-font-weight:normal'><span
lang=EN-US style='font-size:9.0pt;color:red'><o:p></o:p></span></b></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:shape><v:shape id="_x0000_s1037" type="#_x0000_t202" style='position:absolute;
left:5652;top:13870;width:753;height:380' stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1037'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><b style='mso-bidi-font-weight:normal'><span
style='font-size:9.0pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman";
color:red'>轻度</span></b><b style='mso-bidi-font-weight:normal'><span
lang=EN-US style='font-size:9.0pt;color:red'><o:p></o:p></span></b></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:shape><v:shape id="_x0000_s1038" type="#_x0000_t202" style='position:absolute;
left:3644;top:13096;width:753;height:380' stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1038'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><b style='mso-bidi-font-weight:normal'><span
style='font-size:9.0pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman";
color:red'>轻度</span></b><b style='mso-bidi-font-weight:normal'><span
lang=EN-US style='font-size:9.0pt;color:red'><o:p></o:p></span></b></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:shape><v:shape id="_x0000_s1039" type="#_x0000_t202" style='position:absolute;
left:3644;top:12160;width:753;height:570' stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1039'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><b style='mso-bidi-font-weight:normal'><span
style='font-size:9.0pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman";
color:red'>一般</span></b><b style='mso-bidi-font-weight:normal'><span
lang=EN-US style='font-size:9.0pt;color:red'><o:p></o:p></span></b></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:shape><v:shape id="_x0000_s1040" type="#_x0000_t202" style='position:absolute;
left:4648;top:13096;width:753;height:380' stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1040'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><b style='mso-bidi-font-weight:normal'><span
style='font-size:9.0pt;font-family:楷体_GB2312;mso-ascii-font-family:"Times New Roman";
color:red'>一般</span></b><b style='mso-bidi-font-weight:normal'><span
lang=EN-US style='font-size:9.0pt;color:red'><o:p></o:p></span></b></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:shape><v:shape id="_x0000_s1041" type="#_x0000_t202" style='position:absolute;
left:4648;top:13870;width:753;height:380' stroked="f"><v:textbox style='mso-next-textbox:#_x0000_s1041'><![if !mso]><table cellpadding=0 cellspacing=0 width="100%"><tr><td><![endif]><div><p class=MsoNormal><span style='font-size:9.0pt;font-family:楷体_GB2312;
mso-ascii-font-family:"Times New Roman";color:red'>细微</span><span
lang=EN-US style='font-size:9.0pt;color:red'><o:p></o:p></span></p></div><![if !mso]></td></tr></table><![endif]></v:textbox></v:shape></v:group></v:group></v:group><![endif]--><!--[if !vml]-->
| |
| | <!--[endif]--><!--[if !RotText]--> ![文本框: 可能性 低 中 高]() <!--[endif]--><!--[if !vml]--> <!--[endif]--><!--[if !vml]--> ![]() |
<!--[endif]--> <!--[endif]-->
<!--[if !supportLists]-->十、<!--[endif]-->升级问题
1、恢复以前版本数据没有出现“正在调整数据库”提示。 (一般)
2、由于版本之间表结构差异造成的数据无法恢复。 (严重)
3、以前版本数据恢复内容不全。 (严重)
4、在以前版本上覆盖安装之后无法进入程序、或进入程序后出错。 (严重)
5、在以前版本上覆盖安装,进入程序后没有出现“调整数据库”提示。 (一般)
6、升级完成之后核对后台表数据,出现表内容丢失现象。(空表或记录不全) (严重)
7、升级完成之后核对后台表数据,出现数据错误现象。 (严重)
【页面布局方面】
1)各页面整体布局、按钮、对话框、提示信息、下拉菜单等风格一致
2)帮助信息和错误提示、成功提示、异常提示等提示信息中出现的标点均为汉字全角并且提示信息以叹号结束
3)输入框输入内容过长的话,会导致页面文字排列错乱、页面布局混乱
4)页面显示一行内容超长时是否进行换行处理(这种情况要把所有合理输入的情况都要测试到,如数字和英文不换行而汉字换行);
【页面元素方面】
1)输入域的提示信息不明确(如:输入框没有合法输入长度、格式等的提示信息);
2)输入框是否允许粘贴入内容,对粘贴内容的合法校验
3)输入框中输入包含html字符时,可能处理出现异常
【功能方面】
1)输入内容不正确改正后要两次点击“确定”按钮才可以完成操作(
2)以最长的合法输入为条件查询时没有查询结果(后台定义的存放name的空间过短),
3)在列表内进行修改、删除操作后页面是跳转到当前页,还是首页。一般情况下,修改记录后,页面应该跳转到被修改记录显示的页面
4)合理的操作导致网页报JS错误,之后无法继续相关操作
5)任意页面退出登录的情况下,其他页面的所有需登录后才能进行的操作应不可执行,提示请先登录
6)查询时输入与已有查询条件同音的字
7)登录后打开多个页面,其中一个页面做修改或删除操作,其他页面不刷新的情况下在改动处做操作,查看处理情况
8)多个已经登录的页面中一个页面退出登录(该页面显示为尚未登录状态),刷新其他页面重新登录,之前显示为尚未登录状态的页面中的操作应该不提示尚未登录
9)相关页面相关功能做交替操作,看是否有逻辑处理矛盾的问题(如bug345)?10)?如果使用多任务,是否所有的窗口被实时更新
【其他】
1) 数据库出现问题时报错到网页显示
2) 不同的异常要有不同的异常提示,不能出现500或404错误
3) 用户登录后,在浏览器地址栏修改任何已存在的用户的email或tripid等,可以任意切换到其他用户的信息
4) 各页面字符编码不统一
1、相关性检查:
增加/删除一些功能,是否对其他项有影响;
增加某个数据项后,该数据某字段内容过长,查询显示回事数据列表变形;
字符串长度、类型检查。
2、标点符号检查:
把空格键当成一个字符处理,但查询时空格被屏蔽,查询不到添加的内容;
查询时输入特殊字符“_”,程序返回所有记录。
3、检查添加与修改是否一致:
添加要求必填项,修改也应该是必填项
4、脚本错误(IFrame,JS,Ajax)易造成浏览器兼容性问题
5、查询列表,如果有重复信息(distinct)去重
6、登录信息,cookies缓存保留
7、JS格式控制验证处理,注意验证条件,验证未知,触发时间及验证的必要性