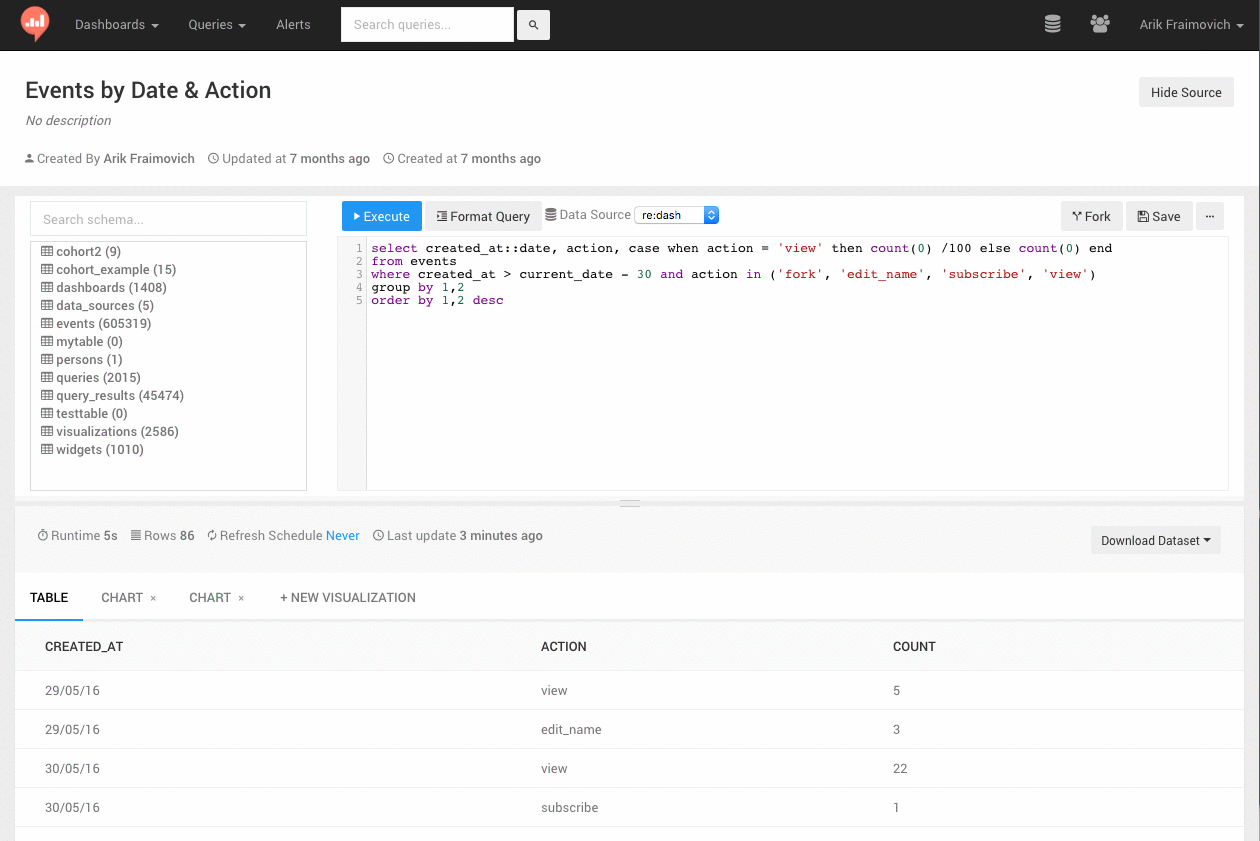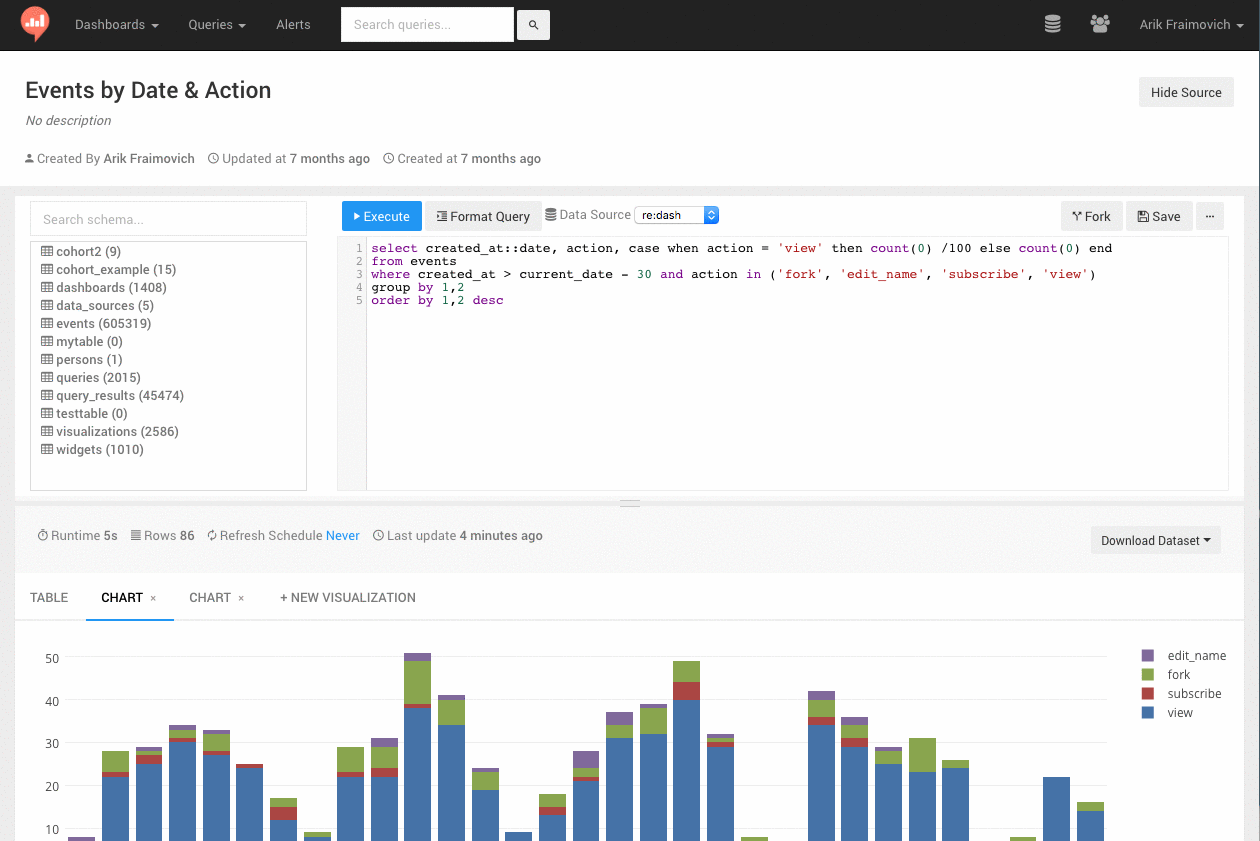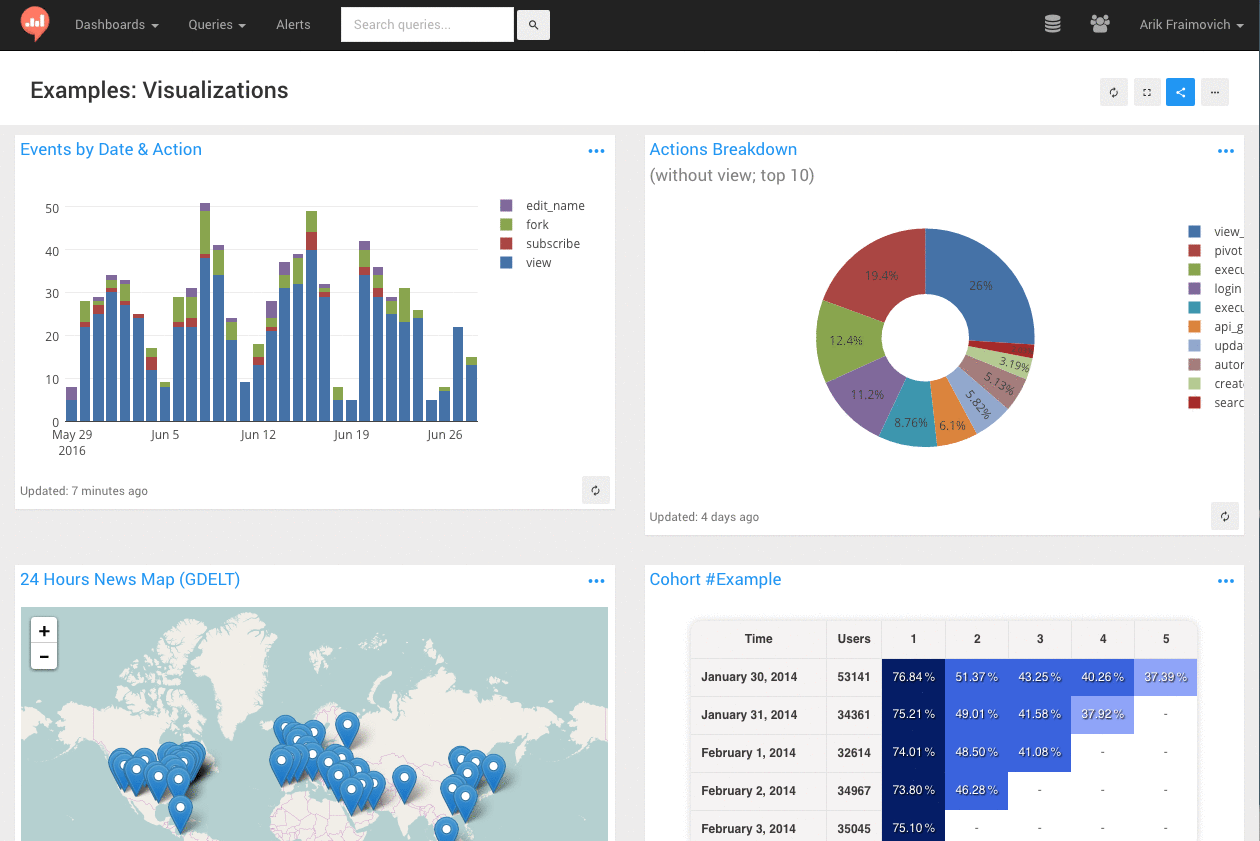
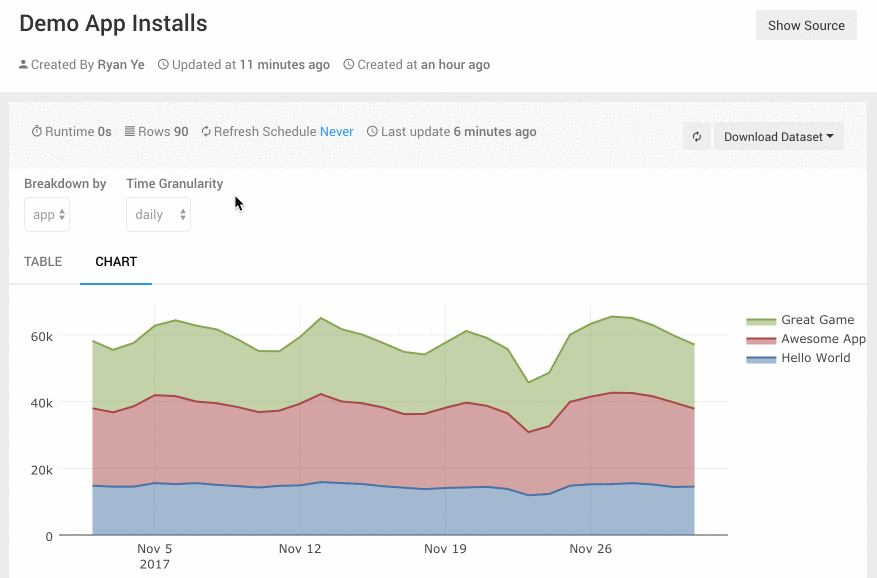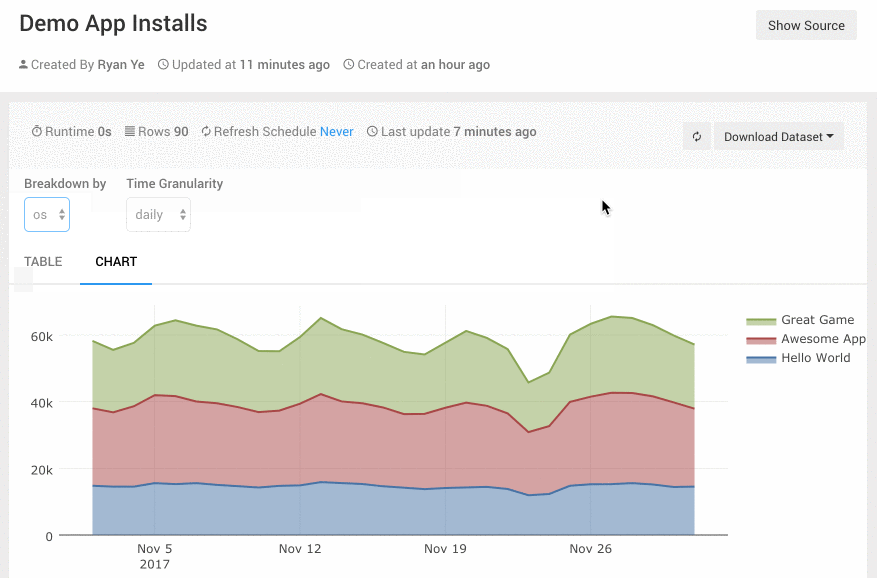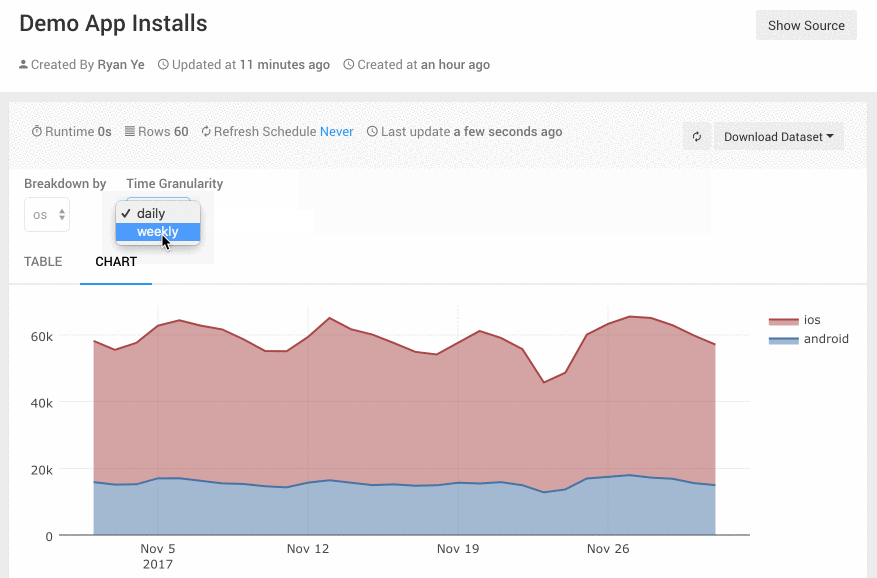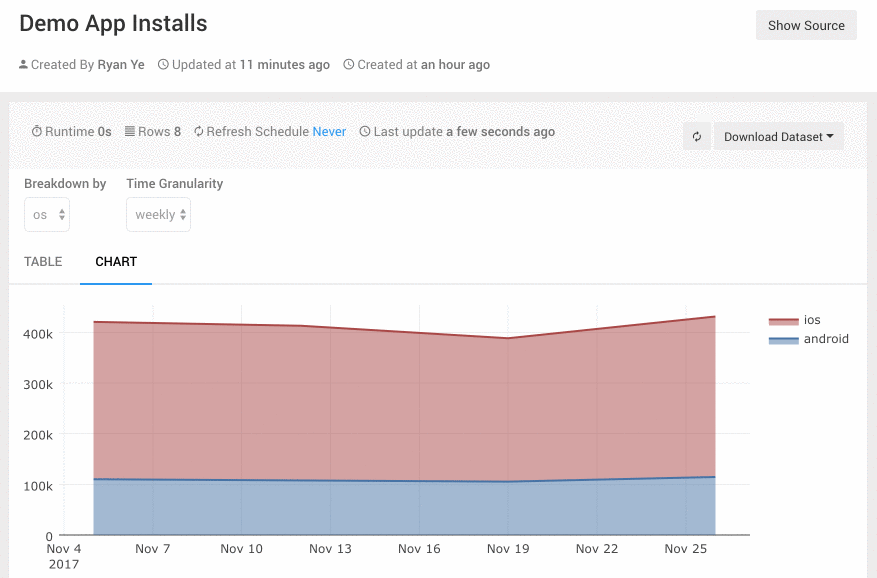
一、配置定义数据库连接属性
二、定义bean
<!-- 主数据库连接池 -->
<bean id="masterDataSource" parent="abstractDataSource">
<property name="url" value="${master.jdbc.url}"/>
<property name="username" value="${master.jdbc.username}"/>
<property name="password" value="${master.jdbc.password}"/>
</bean>
<!-- 从数据库连接池1 -->
<bean id="slave1DataSource" parent="abstractDataSource">
<property name="url" value="${slave1.jdbc.url}"/>
<property name="username" value="${slave1.jdbc.username}"/>
<property name="password" value="${slave1.jdbc.password}"/>
</bean>
<!-- 从数据库连接池2 -->
<bean id="slave2DataSource" parent="abstractDataSource">
<property name="url" value="${slave2.jdbc.url}"/>
<property name="username" value="${slave2.jdbc.username}"/>
<property name="password" value="${slave2.jdbc.password}"/>
</bean>
<!-- 从数据库连接池3 -->
<bean id="slave3DataSource" parent="abstractDataSource">
<property name="url" value="${slave3.jdbc.url}"/>
<property name="username" value="${slave3.jdbc.username}"/>
<property name="password" value="${slave3.jdbc.password}"/>
</bean>
<!-- 动态切换数据源 -->
<bean id="dynamicDataSource" class="com.common.datasource.DynamicDataSource">
<property name="writeDataSource" ref="masterDataSource"></property>
<property name="readDataSources">
<list>
<ref bean="slave1DataSource" />
<ref bean="slave2DataSource" />
<ref bean="slave3DataSource" />
</list>
</property>
<!--轮询方式-->
<property name="readDataSourcePollPattern" value="1" />
<property name="onlyWrite" value="true" />
</bean>
三、事务定义
<!-- 事务管理器 -->
<bean id="dynamicTransactionManager" class="com.common.datasource.DynamicDataSourceTransactionManager">
<property name="dataSource" ref="dynamicDataSource"/>
</bean>
<tx:annotation-driven transaction-manager="dynamicTransactionManager"/>
四、配置插件
<!-- 配置分页插件 -->
<plugins>
<plugin interceptor="com.common.datasource.DynamicPlugin" />
<plugin interceptor="com.github.pagehelper.PageHelper">
<!-- 设置数据库类型 Oracle,Mysql,MariaDB,SQLite,Hsqldb,PostgreSQL六种数据库 -->
<property name="dialect" value="mysql"/>
</plugin>
</plugins>
五、编写动态数据源类
public class DynamicDataSource extends AbstractRoutingDataSource {
private static final Long MAX_POOL = Long.MAX_VALUE;
private final Lock lock = new ReentrantLock();
private Object writeDataSource; //写数据源
private List<Object> readDataSources; //多个读数据源
private int readDataSourceSize; //读数据源个数
private int readDataSourcePollPattern = 0; //获取读数据源方式,0:随机,1:轮询
private AtomicLong counter = new AtomicLong(0);
private boolean onlyWrite=false;
@Override
public void afterPropertiesSet() {
if (this.writeDataSource == null) {
throw new IllegalArgumentException("Property 'writeDataSource' is required");
}
setDefaultTargetDataSource(writeDataSource);
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DynamicDataSourceGlobal.WRITE.name(), writeDataSource);
if (readDataSources != null) {
for (int i = 0; i < readDataSources.size(); i++) {
targetDataSources.put(DynamicDataSourceGlobal.READ.name() + i, readDataSources.get(i));
}
readDataSourceSize = readDataSources.size();
} else {
readDataSourceSize = 0;
}
setTargetDataSources(targetDataSources);
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey() {
if (onlyWrite){
return DynamicDataSourceGlobal.WRITE.name();
}
DynamicDataSourceGlobal dynamicDataSourceGlobal = DynamicDataSourceHolder.getDataSource();
if (dynamicDataSourceGlobal == null || dynamicDataSourceGlobal == DynamicDataSourceGlobal.WRITE || readDataSourceSize <= 0) {
return DynamicDataSourceGlobal.WRITE.name();
}
//index表示选择第几个从数据库
int index;
if(readDataSourcePollPattern == 1) {
//轮询方式
long currValue = counter.incrementAndGet();
if((currValue + 1) >= MAX_POOL) {
try {
lock.lock();
if((currValue + 1) >= MAX_POOL) {
counter.set(0);
}
} finally {
lock.unlock();
}
}
index = (int) (currValue % readDataSourceSize);
} else {
//随机方式
index = ThreadLocalRandom.current().nextInt(0, readDataSourceSize);
}
return dynamicDataSourceGlobal.name() + index;
}
public void setWriteDataSource(Object writeDataSource) {
this.writeDataSource = writeDataSource;
}
public List<Object> getReadDataSources() {
return readDataSources;
}
public void setReadDataSources(List<Object> readDataSources) {
this.readDataSources = readDataSources;
}
public Object getWriteDataSource() {
return writeDataSource;
}
public int getReadDataSourceSize() {
return readDataSourceSize;
}
public void setReadDataSourceSize(int readDataSourceSize) {
this.readDataSourceSize = readDataSourceSize;
}
public int getReadDataSourcePollPattern() {
return readDataSourcePollPattern;
}
public void setReadDataSourcePollPattern(int readDataSourcePollPattern) {
this.readDataSourcePollPattern = readDataSourcePollPattern;
}
public boolean isOnlyWrite() {
return onlyWrite;
}
public void setOnlyWrite(boolean onlyWrite) {
this.onlyWrite = onlyWrite;
}
}
public class DynamicDataSourceHolder {
private static final ThreadLocal<DynamicDataSourceGlobal> holder = new ThreadLocal<DynamicDataSourceGlobal>();
private DynamicDataSourceHolder() {
//
}
public static void putDataSource(DynamicDataSourceGlobal dataSource) {
holder.set(dataSource);
}
public static DynamicDataSourceGlobal getDataSource() {
return holder.get();
}
public static void clearDataSource() {
holder.remove();
}
}
public class DynamicDataSourceTransactionManager extends DataSourceTransactionManager {
/**
* 只读事务到读库,读写事务到写库
*
* @param transaction
* @param definition
*/
@Override
protected void doBegin(Object transaction, TransactionDefinition definition) {
//设置数据源
boolean readOnly = definition.isReadOnly();
if (readOnly) {
DynamicDataSourceHolder.putDataSource(DynamicDataSourceGlobal.READ);
} else {
DynamicDataSourceHolder.putDataSource(DynamicDataSourceGlobal.WRITE);
}
super.doBegin(transaction, definition);
}
/**
* 清理本地线程的数据源
*
* @param transaction
*/
@Override
protected void doCleanupAfterCompletion(Object transaction) {
super.doCleanupAfterCompletion(transaction);
DynamicDataSourceHolder.clearDataSource();
}
}
/**
* Desc: Mybatis动态数据库切换插件
*/
@Intercepts({
@Signature(type = Executor.class, method = "update", args = {
MappedStatement.class, Object.class}),
@Signature(type = Executor.class, method = "query", args = {
MappedStatement.class, Object.class, RowBounds.class,
ResultHandler.class})})
public class DynamicPlugin implements Interceptor {
protected static final Logger logger = LoggerFactory.getLogger(DynamicPlugin.class);
private static final String REGEX = ".*insert\\u0020.*|.*delete\\u0020.*|.*update\\u0020.*";
private static final Map<String, DynamicDataSourceGlobal> cacheMap = new ConcurrentHashMap<>();
@Override
public Object intercept(Invocation invocation) throws Throwable {
boolean synchronizationActive = TransactionSynchronizationManager.isSynchronizationActive();
if (!synchronizationActive) {
Object[] objects = invocation.getArgs();
MappedStatement ms = (MappedStatement) objects[0];
DynamicDataSourceGlobal dynamicDataSourceGlobal;
if ((dynamicDataSourceGlobal = cacheMap.get(ms.getId())) == null) {
//读方法
if (ms.getSqlCommandType().equals(SqlCommandType.SELECT)) {
//!selectKey 为自增id查询主键(SELECT LAST_INSERT_ID() )方法,使用主库
if (ms.getId().contains(SelectKeyGenerator.SELECT_KEY_SUFFIX)) {
dynamicDataSourceGlobal = DynamicDataSourceGlobal.WRITE;
} else {
BoundSql boundSql = ms.getSqlSource().getBoundSql(objects[1]);
String sql = boundSql.getSql().toLowerCase(Locale.CHINA).replaceAll("[\\t\\n\\r]", " ");
if (sql.matches(REGEX)) {
dynamicDataSourceGlobal = DynamicDataSourceGlobal.WRITE;
} else {
dynamicDataSourceGlobal = DynamicDataSourceGlobal.READ;
}
}
} else {
dynamicDataSourceGlobal = DynamicDataSourceGlobal.WRITE;
}
logger.warn("设置方法[{}] use [{}] Strategy, SqlCommandType [{}]..", ms.getId(), dynamicDataSourceGlobal.name(), ms.getSqlCommandType().name());
cacheMap.put(ms.getId(), dynamicDataSourceGlobal);
}
DynamicDataSourceHolder.putDataSource(dynamicDataSourceGlobal);
}
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
if (target instanceof Executor) {
return Plugin.wrap(target, this);
} else {
return target;
}
}
@Override
public void setProperties(Properties properties) {
//
}
已有 0人发表留言,猛击->> 这里<<-参与讨论
ITeye推荐