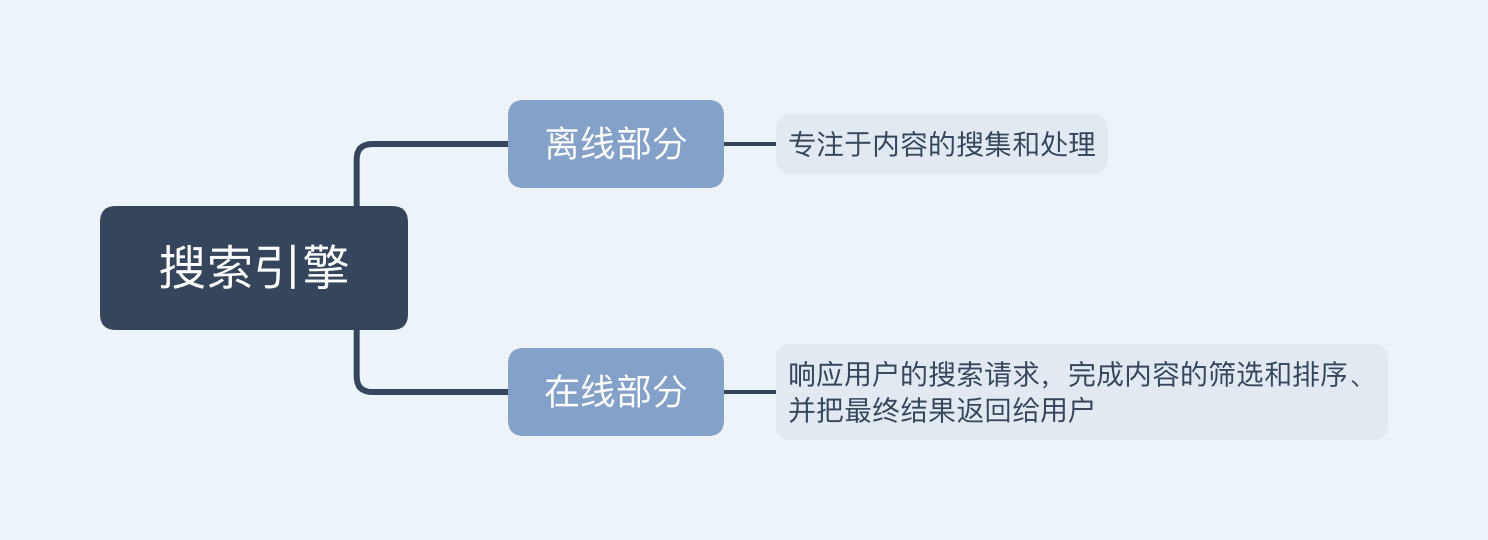
本文主要是针对人脸识别应用中出现的 人脸活体检测做简要调研及论述。有关人脸检测相关内容可以参考我的另一篇文章—— 人脸检测与深度学习传送门~ 知乎专栏
引言——人脸识别技术迈向更高层次的一大障碍:活体检测
随着线上支付的不断普及,相关的人脸识别等技术正在中国不断进步。近日,麻省理工科技评论评出全球十大突破技术,其中由“刷脸支付——Paying with Your Face ”榜上有名。
技术突破:人脸识别技术如今已经可以十分精确,在网络交易等相关领域已被广泛使用。
重大意义:该技术提供了一种安全并且十分方便的支付方式,但是或许仍存在 隐私泄露问题
目前基于深度学习的发展,我认为还有一个问题就是 存在被伪造合法用户人脸的攻击的风险。
——————————————- 更新补充分割线 ————————————————
评论区有问到这方面的开源代码,我这边没有仔细找过,在github找了一些相关代码,没有验证过,汇总了一下希望对大家有帮助:
1.C++代码 https://github.com/allenyangyl/Face_Liveness_Detection
2. https://github.com/rienheuver/face-antispoofing-LBP
3. https://github.com/OeslleLucena/FASNet
4.论文Person Specific Face Anti-Spoofing with Subject Domain Adaptation 对应的代码—— https://github.com/jwyang/Person-Specific-Face-Anti-Spoofing
6.论文Face anti-spoofing based on color texture analysis基于颜色纹理分析的代码—— https://github.com/zboulkenafet/Face-anti-spoofing-based-on-color-texture-analysis
7. https://github.com/pp21/Guided-Scale-Texture-for-Face-Presentation-Attack-Detection
8.3d头套的 https://github.com/Marco-Z/Spoofing-Face-Recognition-With-3D-Masks
9. https://github.com/number9473/nn-algorithm/issues/37
10.下文中提到的几个数据库的下载链接: https://github.com/number9473/nn-algorithm/issues/36
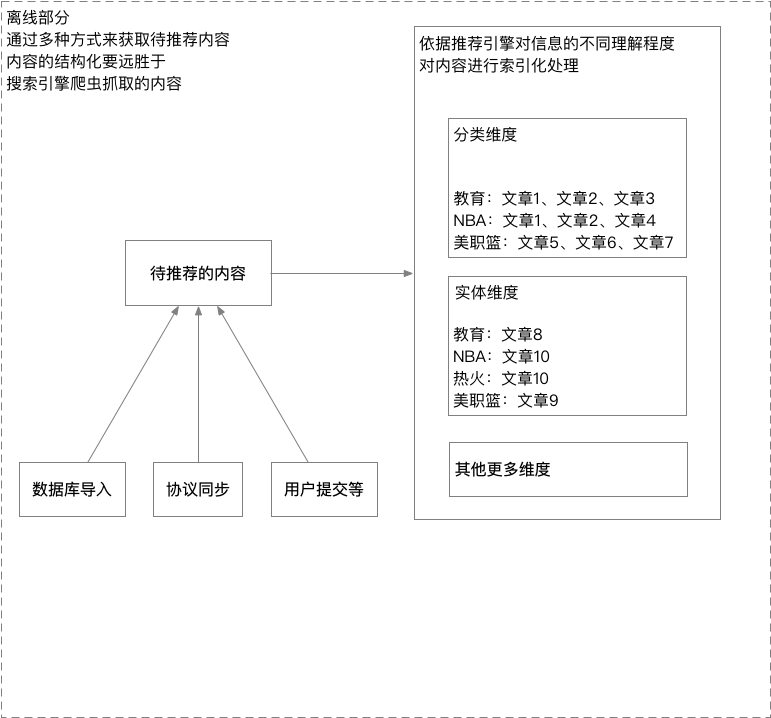
11.活体检测在人脸识别系统中处于的位置,大部分现有的系统是没有活体检测的:
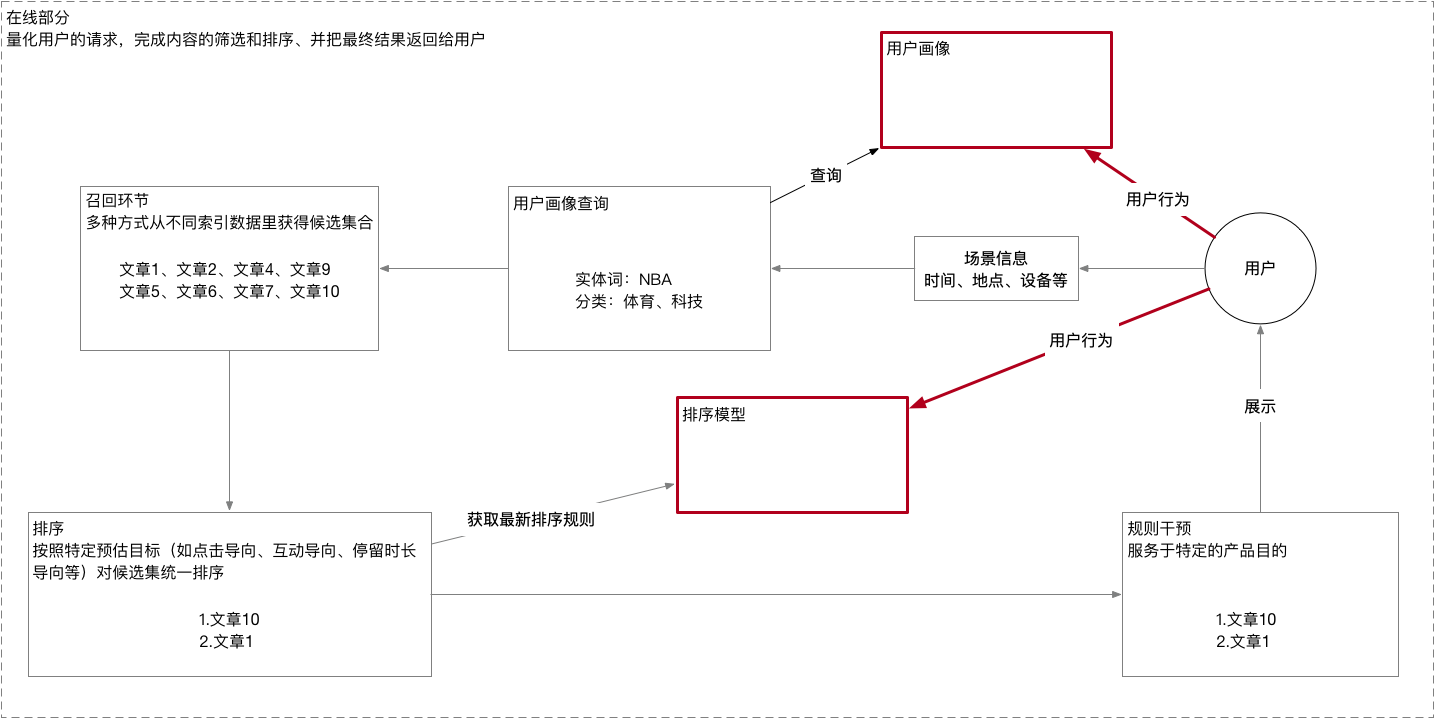
 12.文中文献[11]的基于图像失真特征提取分析的活体检测的整体框架图:
12.文中文献[11]的基于图像失真特征提取分析的活体检测的整体框架图:
(15年4月TIFS的提出一种基于图像失真分析(IDA)的人脸活体检测方法。IDA特征向量分别由镜面反射(打印纸张或者LCD屏幕3维)、模糊程度(重采集—散焦2维)、图像色度和对比度退化(对比度失真15维)、颜色多样性(打印机或LCD颜色分辨率有限等101维)四种典型特征组成(121维向量),通过输入基于SVM的集成分类器(ensemble classfier),训练分类出二值真伪结果(voting scheme——用于判断视频攻击的情况,超过50%帧数为真即认定为活体))

其他一些有意思的参考
1. https://github.com/4x7y/FakeImageKiller
2. https://github.com/waghaoxg/whx-temp/tree/c2801685b3188492b6693de1e361db3c52b9b7d6
——————————————— 以下正文 ——————————————————
和指纹、虹膜等生物特征相比,人脸特征是最容易获取的。人脸识别系统逐渐开始商用,并向着自动化、无人监督化的趋势发展,然而目前人脸识别技术能识别人脸图像的身份但无法准确辨别所输入人脸的真伪。那么如何自动地、高效地辨别图像真伪抵抗欺骗攻击以确保系统安全已成为人脸识别技术中一个迫切需要解决的问题。
通常意义上的活体检测是当生物特征信息从合法用户那里取得时,判断该生物信息是否从具有生物活体的合法用户身上取的。活体检测的方法主要是通过识别活体上的生理信息来进行,它把生理信息作为生命特征来区分用照片、硅胶、塑料等非生命物质伪造的生物特征。

人脸识别技术面临着三种欺诈手段:

下面通过学术论文、专利发明和企业研发等三方面进行调查:
(一) 学术论文方面
人脸活体检测的学术研究机构主要有中科院自动化所李子青团队、瑞士IDAIP研究室高级研究员Sebastien Marcel主导的Biometrics group、英国南安普顿大学机器视觉系教授Mark S. Nixon所属的视觉学习与控制研究组和国际生物特征识别著名专家Anil K. Jain所在的密歇根州立大学生物特征识别研究组。近些年上述机构所著的关于活体检测的高质量文章陆续发表在IEEE TIFS/TIP等一些顶级期刊,同时Springer于2014年出版了由Sebastien Marcel等编著的《Handbook of Biometric Anti-Spoofing》,书中深入介绍了指纹、人脸、声音、虹膜、步态等生物特征识别反欺骗的方法,还对涉及的性能评估指标、国际标准、法律层面、道德问题等作了阐述,为生物特征识别反欺骗技术的进一步发展作出重要贡献。
1. 综述文献[1]将活体检测技术分为运动信息分析、纹理信息分析、活体部位分析三种,文中讨论了基于真伪图像存在的非刚性运动、噪声差异、人脸背景依赖等特性形成的分类器性能。
2. 文献[2]介绍了一个公开的人脸活体检测验证数据库(PHOTO-ATTACK),在数据库(PRINT-ATTACK)的基础上进行了扩展,添加移动手机拍摄照片和高分辨率屏幕照片。同时文中提出了一种基于光流法的前后景相关性分析来辨别影像真伪,取得较好的性能。
3. 文献[3]针对多生物识别欺骗稳健性的提高,提出一种异常检测新技术,首先通过中值滤波器来提高传统集成方法中求和准则的容差,再通过一种基于bagging策略的检测算法提高检测拒绝度,该算法融合了2D-Gabor特征、灰度共生矩阵(GLCM)多种特征、傅里叶变换的频域信息,特征提取后得到3种特征向量,使用主成分分析(PCA)降维选取形成混合特征,输入bagging分类器并获得检测结果,实验表明算法具有较高准确性。
4. 文献[4]提出一种基于颜色纹理分析的活体检测算法,通过LBP描述子提取联合颜色(RGB、HSV和YCbCr)纹理信息来表征图像,将信息输入SVM分类器进行真伪辨别。
5. 14年TIP的文献[5]提出一种基于图像质量评价的方法来增强生物特征识别的安全性,使用25种图像质量分析指标(列出较关键的几个有:像素差异性分析、相关性分析、边缘特征分析、光谱差异性、结构相似性、失真程度分析、自然影像估计),该方法只需要一张图片就可以区别真伪,适用于多种生物特征识别场合,速度快,实时性强,且不需要附近设备及交互信息。
6. 14年12月发表在TIFS的文献[6]提出一种反欺骗能力评估框架—Expected Performance and Spoofability (EPS)Framework,针对现有反欺骗系统作性能评估,创新性地指出在一定条件下验证系统将失去二值特性转变为三类:活体合法用户、无用攻击者(zero-effort)和欺骗攻击者,EPS框架主要通过测量系统期望达到的FAR(错误接受无用率)和SFAR(错误接受欺骗率)及两者之间的范围,同时考虑系统被欺骗的成本和系统存在的弱点,并量化为单一的值用来评价系统优劣。
7. 15年5月发表在TIFS的文章[7]针对视频回放攻击提出一种基于visual rhythm analysis的活体检测方法,文中指出:由于静态背景易获得,基于背景的方法显得容易被破解;利用照片的旋转和扭曲也可以轻易模拟并欺骗基于光流法的活体检测系统;当攻击视频包含头部、嘴唇、眼睛等动作可以容易通过基于运动交互的系统;文中对傅里叶变换后的视频计算水平和垂直的视觉节奏,采用三种特征(LBP、灰度共生矩阵GCLM、HOG)来对visual rhythm表征与降维,利用SVM分类器和PLS(偏最小二乘)来辨别视频真伪。
8. 15年4月TIFS的文章[8]提出一种基于局部纹理特征描述子的活体检测方法,文中将现有的活体检测方法分为三类:动态特征分析(眨眼)、全局特征分析(图像质量)和局部特征分析(LBP、LBQ、Dense SIFT)。提出的方法对一系列特征向量进行独立量化或联合量化并编码得到对应的图像标量描述子,文中实验部分给出不同局部特征对应的性能。
9. 15年8月TIP的文章[9]在面向手机端的人脸识别活体检测的需求,根据伪造照片相对于活体照片有光照反射特性呈现出更加均衡扩散缓慢的特点,提出一种基于图像扩散(反射)速度模型(Diffusion Speed Model)的活体检测方法,通过引入全变差流(TV)来获得扩散速度,在得到的扩散速度图基础上利用LSP编码(类似LBP)获取的局部速度特征向量作为线性SVM分类器的输入,经分类区分输入影像的真伪。
10. 15年12月TIP文献[10]提出一种基于码本(codebook)算法的新型人脸活体检测方法,根据重采样导致伪造影像出现的条带效应和摩尔纹等噪声现象,文中通过三个步骤来完成分类,第一步:计算视频噪声残差,通过将原始视频和经高斯滤波以后的视频作残差得到噪声视频,再对其作二维傅里叶变换得到频域信息,可以看到伪造视频的幅度谱和相位谱中呈现出明显的摩尔纹及模糊等区别,计算得到相关时频描述子。第二步通过码本算法迭代选取最能表示的descriptor,经过编码将这些描述子转化成新的矩阵表示(矩阵不能直接拿来分类),故用池化(pooling)方法(列求和或取最大值)得到输入向量。第三步利用SVM分类器或PLS(偏最小二乘)对输入向量分类判断其真伪。
11. 15年4月TIFS的文献[11]提出一种基于图像失真分析(IDA)的人脸活体检测方法,同时给出了一个由多种设备采集的人脸活体检测数据库(MSU-MFSD)。IDA特征向量分别由镜面反射(打印纸张或者LCD屏幕3维)、模糊程度(重采集—散焦2维)、图像色度和对比度退化(对比度失真15维)、颜色多样性(打印机或LCD颜色分辨率有限等101维)四种典型特征组成(121维向量),通过输入基于SVM的集成分类器(ensemble classfier),训练分类出二值真伪结果(voting scheme——用于判断视频攻击的情况,超过50%帧数为真即认定为活体)。
12. 几种公开的人脸活体检测数据库:

(二)专利发明方面
对于以研发产品为主的公司来说,用户的体验是检验产品成功的最重要的标准之一。下面从用户的配合程度来分类人脸活体检测技术。
(1) 根据真人图像是一次成像的原理,其比照片包含更多的中频细节信息,专利1[12]首先采用DoG滤波器获取图像信息中的中频带信息,然后通过傅里叶变换提取关键特征,最后通过logistic回归分类器对提取和处理后的特征信息辨析和分类,已达到所识别的图像为真实人脸还是照片人脸的目的。优点:不添加额外的复制设备、不需要用户的主动配合、实现简单、计算量小且功能独立;缺点:采集的正反样本要全面,只针对照片。
(2) 专利2[13]是通过检测人脸的眼睛区域是否存在亮瞳效应来区分真实人脸和照片视频中的人脸。亮瞳效应的判断是利用亮暗瞳差分图像的眼睛区域是否存在圆形亮斑而定。另外,采集亮瞳图像所涉及的设备包括红外摄像头和由LED灯做成的红外光源。优点:照片和视频都可以,使可靠性增加;缺点:需额外的设备。
(3) 专利3[14]利用共生矩阵和小波分析进行活体人脸检测。该方案将人脸区域的灰度图像首先进行16级灰度压缩,之后分别计算4个灰度共生矩阵(取矩阵为1,角度分别为0。、45。、90。、135。),然后在灰度共生矩阵的基础上再提取能量、熵、惯性矩和相关性四个纹理特征量,再次分别对四个灰度共生矩阵的4个纹理特征量求均值和方差;同时对原始图像利用Haar小波基进行二级分解,提取子带HH1,HH2的系数矩阵后求均值和方差;最后将所有的特征值作为待检测样本送入训练后的支持向量机中进行检测,分类识别真实和假冒人脸图像。优点:不需添加额外的辅助设备、不需要用户降低了计算复杂度,提高了检测准确率;缺点:只针对照片欺骗。
(4) 专利4[15]是一种基于HSV颜色空间统计特征的人脸活体检测方法,该方案将人脸图像从RGB颜色空间转换到YCrCb;然后进行预处理(肤色分割处理、去噪处理、数学形态学处理和标定连通区域边界处理)后获取人脸矩形区域的坐标;再对待检测的人脸图像分图像块,并获取待检测的人脸图像中的左右图像块的三个颜色分量的特征值;最后将归一化的特征值作为待检测样本送入训练好的支持向量中进行检测,确定包含人脸的图像是否为活体真实人脸图像。优点:不需添加额外的辅助设备和用户的主动配合,降低了人脸认证系统延时和计算复杂度,提高了检测准确率;缺点:只针对照片欺骗,阈值的设置为经验值。
(5) 专利5[16]使用的活体识别方法为通过摄像头在一定时间内拍摄多张人脸照片,预处理后提取每张照片的面部本特征信息,将先后得到的面部特征信息进行对比分析获取特征相似度,设置合理阈值,若相似度在阈值范围内,则认为有微表情产生,识别为活体,否则为非活体。优点:不需要人脸部做大量的表情配合动作;缺点:只针对照片欺骗。
(6) 专利6[17]主要基于人脸3D模型对所述人脸形状进行归一化处理,并获得所述人脸形状相对于人脸3D模型的旋转角度,将连续多帧图像的旋转角度连成一条曲线,判断该曲线是否满足设定要求,若满足,判断角度最大的一帧图像中人脸肤色区域面积比例是否大于K,若是,则判断为真实人脸,否则为虚假人脸。优点:误报率降低,速度快,用户体验好;缺点:需较大的计算时间和空间开销。
(7) 专利7[18]公开一种基于背景比对的视频和活体人脸的鉴别方法。首先对输入视频的每一帧图像进行人脸位置检测,很据检测出的人脸位置确定背景比对区域;然后选取输入视频中和背景比对区域在尺度空间上的极致点作为背景比对区域的特征点,得到背景特征点集Pt;再用Gabor小波变换描述图像I在背景特征点集Pt的特征,根据此结果定义活体度量L;如果活体度量L大于阈值θ,判断为活体,否则视为假冒视频。优点:解决仅通过单个摄像头进行视频人脸和活体人脸的计算机自动鉴别问题,不需用户配合,实时性较好;缺点:只针对视频欺骗。
(8) 专利8[19]提供了一种具有活体检测功能的双模态人脸认证方法。首先建立存储有已知身份人脸的可见光训练图像和近红外外训练图像的数据库;然后通过图像采集模块同时采集待认证人头部的可见光图像和近红外图像;采用人的脸部的人脸近红外图像与人脸可见光图像双模态特征的联合识别。优点:提高了识别认证精度,有效避免人脸存在较大变化情况下识别失败的问题,避免照片或者模型欺骗;缺点:需红外设备。
(9) 为更好地防止活体检测中的照片和视频剪辑方式等欺诈行为,专利9[20]不同之处在于,用户并不知道系统发出何种指令,要求用户做出何种动作,而且用户实现也并不知晓系统要求的动作完成次数。原因在于,预先定义了一个动作集(包括眨眼、扬眉、闭眼、瞪眼、微笑等),用户在进行活体检测时,系统每次都从动作集中选择一种或若干种动作,随机指定完成动作的次数,要求用户在规定的时间内完成它们。优点:更好地防止活体检测中的照片和视频剪辑方式等欺骗行为,活性检测的可靠性和安全性更高;缺点:需用户主动配合,容易受外部环境影响。
(10) 专利10[21]主要利用人脸面部运动和生理性运动来判断是照片还是真实人脸。人脸检测结果框内的人脸面部运动是在眼睛和嘴附近进行判断,依据运动区域中心坐标和人脸的眼睛的位置坐标之间,以及和嘴的位置坐标之间的欧式距离是否小于预定阈值。确定人脸生理性运动是根据运动区域内的运动方向为垂直方向的原理。优点:可靠性提高;缺点:只针对照片欺骗。
(11) 专利11[22]根据光流场对物体运动比较敏感,而真实人脸的眼部在姿势校正和眨眼过程中又比照片产生更大的光流,利用LK算法计算输入视频序列中相邻两帧的光流场,求得光流幅值,得到幅值较大的像素点数所占的比重,若比例足够大则标定为眼部发生了运动,从而判定为真实人脸。优点:系统的隐蔽性和安全性增强。缺点:只针对照片欺骗。
(12) 专利12[23]也是定位眼睛和嘴巴区域。根据采集的图片帧数(包含面部中眼睛和嘴巴等关键点)和特征平均差异值(由采集的两帧图片对应的特征值的加权欧式距离获得)的计算次数与预设值的比较,以及平均差异值与阈值的比较来判定是否为真实人脸。优点:解决了采用三维深度信息进行人脸活体检测时,计算量大的问题,以及应用场景约束的情况。
(13) 专利13[24]公开一种活体人脸的快速识别方法,其方案为:首先输入连续的人脸图像(若相邻两幅人脸图像不为同一状态则予以丢弃,重新多幅连续的人脸图像),对每幅人脸图像确定瞳孔位置并裁出人眼区域;然后通过支持向量机训练方法和AdaBoost训练方法对睁眼和闭眼样本进行训练,最后判断眼珠睁闭状态,若存在眨眼过程则通过活体判别。优点:有效拒绝非真实人脸欺骗识别,计算速度提高,不受应用场景的约束;缺点:需用户主动配合。
(14) 专利14[25]通过判断连续多帧图像中所获的眼睛或嘴巴区域的属性变化值(上眼皮的距离变化值或上下嘴唇间的距离变化值)的规律是否符合真实人脸的变化规律,若是,则判断为真实人脸,否则为虚假人脸。所采用的技术核心:将当前帧与前t帧的眼睛或嘴巴区域合并成一张图,采用基于深度学习的回归方法输出两帧图像中属性变化值,重复该步骤直至获得每帧图像的属性变化值;将所有属性变化值按帧时间顺序组成一向量,对各向量的长度进行设定,然后利用SVM分类器对所述向量进行分类,再判断分类结果是否满足设定动作下的真实人脸的变化规律。优点:检测精度高、速度快,针对照片和视频欺骗;缺点:需用户主动配合。
(15) 专利15[26]是通过眨眼动作进行活体检测。首先对人脸检测与眼睛定位;然后眼部区域截取,从归一化处理后的图像中图像中计算眼睛的开合程度;运用条件随机场理论建立用于判断眨眼动作的模型。优点:可仅通过单个摄像头进行鉴别;缺点:需用户主动配合,只针对照片欺骗。
(三)企业研发应用方面

对支付宝人脸登陆系统的活体检测功能进行了实际测试(iphone5S,支付宝最新版本9.5.1,人脸识别和活体检测模块是独立的,其活体检测只有采用了眨眼模式,之前还有点头),检测结果如下: 
结论:
1.根据调查结果的实际应用技术,针对三种主要的欺骗手段,目前有以下几种应用广泛的活体检测方法: 
2.从用户配合、对光照影响、是否需要附加设备、抵挡攻击、用户体验等方面对比了人脸识别系统中活体检测应用较多的7类具体方法,形成下表:

3.随着人脸识别系统的发展和演进,综上所述,研究开发一种新型高效鲁棒性好的人脸活体检测技术应该满足以下几个条件:
① 在线实时处理。活体检测过程应与人脸识别同时进行,越来越多的移动端需求给实时性提出越来越高的要求;
② 受光照等外界影响小。人脸识别验证系统的应用面临着许多场景,活体检测技术应满足多场景、多终端应用的要求,鲁棒性强;
③ 用户界面自然,交互少,欺骗代价高。基于运动等的检测方法对用户来说,增加一系列的交互操作,不仅复杂度增加,可能需要附加的硬件设备支撑,所以新型的活体检测技术应该具有良好的用户体验,同时使得欺骗攻击的代价尽可能的高,保证安全性;
④ 对欺骗有着优异的检测能力,同时对人脸识别特征提取起辅助作用。基于纹理或图像特征的活体检测方法是未来的主要趋势,那么这些特征的提取和分类同样能给人脸识别带来益处。
4. 一种可行的人脸活体检测框架:根据总结发现,纯粹的基于和(sum-rule)的理念可能并不适合活体检测,就好比“木桶效应”,伪造攻击只要抓住了短板,一样可以破解大部分基于sum-rule的方法。一种较好的方法是与此对应的多层次结合的概念,结合文献5、8、10、11所述的相关图像特性,可以着眼于图像全局特性分析(质量)和局部特性分析(LBP等)相结合。
参考文献
[1] O. Kahm and N. Damer, “2d face liveness detection: An overview,” inb Biometrics Special Interest Group (BIOSIG), 2012 BIOSIG-Proceedings of the International Conference of the. IEEE, 2012, pp. 1–12.
[2] A. Anjos, M. M. Chakka, and S. Marcel, “Motion-based countermeasures to photo attacks in face recognition,” IET Biometrics, vol. 3,no. 3, pp. 147–158, 2013.
[3] Wild P, Radu P, Chen L, et al. Robust multimodal face and fingerprint fusion in the presence of spoofing attacks[J]. Pattern Recognition, 2016, 50: 17-25.
[4] Boulkenafet Z, Komulainen J, Hadid A. face anti-spoofing based on color texture analysis[C]//Image Processing (ICIP), 2015 IEEE International Conference on. IEEE, 2015: 2636-2640.
[5] Galbally J, Marcel S, Fierrez J. Image quality assessment for fake biometric detection: Application to iris, fingerprint, and face recognition[J]. Image Processing, IEEE Transactions on, 2014, 23(2): 710-724.
[6] Chingovska I, Rabello dos Anjos A, Marcel S. Biometrics evaluation under spoofing attacks[J]. Information Forensics and Security, IEEE Transactions on, 2014, 9(12): 2264-2276.
[7] Pinto A, Robson Schwartz W, Pedrini H, et al. Using visual rhythms for detecting video-based facial spoof attacks[J]. Information Forensics and Security, IEEE Transactions on, 2015, 10(5): 1025-1038.
[8] Gragnaniello D, Poggi G, Sansone C, et al. An investigation of local descriptors for biometric spoofing detection[J]. Information Forensics and Security, IEEE Transactions on, 2015, 10(4): 849-863.
[9] Kim W, Suh S, Han J J. Face Liveness Detection From a Single Image via Diffusion Speed Model[J]. Image Processing, IEEE Transactions on, 2015, 24(8): 2456-2465.
[10] Pinto A, Pedrini H, Robson Schwartz W, et al. Face Spoofing Detection Through Visual Codebooks of Spectral Temporal Cubes[J]. Image Processing, IEEE Transactions on, 2015, 24(12): 4726-4740.
[11] Wen D, Han H, Jain A K. Face spoof detection with image distortion analysis[J]. Information Forensics and Security, IEEE Transactions on, 2015, 10(4): 746-761.
[12] 李冀,石燕,谭晓阳.一种应用于人脸识别的活体检测方法及系统:中国,101999900.2013-04-17.
[13] 秦华标,钟启标.基于亮瞳效应的人脸活体检测方法:中国,103106397.2013-05-15.
[14] 毋立芳,曹瑜,叶澄灿等.一种基于灰度共生矩阵和小波分析的活体人脸检测方法:中国,103605958.2014-02-26.
[15] 严迪群,王让定,刘华成等.一种基于HSV颜色空间特征的活体人脸检测方法:中国,103116763.2013-05-22.
[16] 傅常顺,杨文涛,徐明亮等.一种判别活体人脸的方法:中国,104361326.2014-02-18.
[17] 陈远浩.一种基于姿态信息的活体检测方法:中国,104794465.2015-07-22.
[18] 潘纲,吴朝晖,孙霖.基于背景比对的视频和活体人脸的鉴别方法:中国,101702198.2011-11-23.
[19] 徐勇,文嘉俊,徐佳杰等.一种活体检测功能的双模态人脸认证方法和系统:中国,101964056.2012-06-27.
[20] 王先基,陈友斌.一种活体人脸检测方法与系统:中国,103440479.2013-12-11.
[21] 丁晓青,王丽婷,方驰等.一种基于人脸生理性运动的活体检测方法及系统:中国,101159016.2008-04-09.
[22] 马争鸣,李静,刘金葵等. 一种在人脸识别中应用的活体检测方法:中国,101908140.2010-12-08.
[23] 黄磊,任智杰. 一种人脸活体检测方法及系统:中国,103679118.2014-03-26.
[24] 彭飞. 一种活体人脸的快速识别方法:中国,103400122.2013-11-20.
[25] 陈元浩. 一种基于相对属性的活体检测方法:中国,104794464.2015-07-22.
[26] 吴朝晖,潘纲,孙霖. 照片人脸与活体人脸的计算机自动鉴别方法:中国,100592322.2010-02-24.