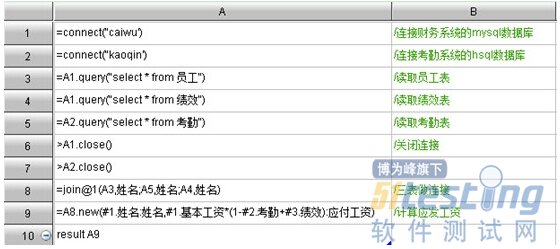
最近一朋友提了几个Android问题让我帮忙写个小分享,我觉得对新人还是挺有帮助的,所以有了这个小分享。
1. 目前, Android APP开发完成后,通常需要在哪些机型上进行测试?
2. 目前, 开发Android APP时,需要考虑的分辨率有哪些?
这两个问题可以合起来回答的。
http://developer.android.com/about/dashboards/index.html
源自Google Play的数据,每月都会进行update,可以及时了解Android版本比例趋势。

屏幕密度数据

OpenGL ES版本

也可以参考一下国内一个第三方数据: http://www.umindex.com/#android_device

目前三星和小米市场占有率是遥遥领先的,三星Note2、Note3、S3、S4、S5、小米123、红米必须测试,魅族也比较坑爹,加入测试名单吧。再选中小屏幕各一款(譬如华为C8650、Moto ME511)。
Android 1.5、1.6、2.0、2.1和小屏幕的属于古董级别的机器,市场存量也很少,新出的机器都是4.0以上的了,所以必要时需要舍弃对古董的支持,因为适配成本很高,对于新开发的应用,这个适配不值得投入。
3. 目前, 开发Android APP时,适应多个分辨率的技术方案有哪些?
http://developer.android.com/guide/practices/screens_support.html
Android的屏幕适配,可以在工程res目录下进行处理,无需写代码,Android自动找最适合的资源进行显示,相信大家都相当熟悉的了。
目前我使用的是ADT22.6,新建一个Android工程,会自动在res目录下生成这个目录结构。这里有5个前缀drawable的文件夹,对应不同密度屏幕时所取的图片资源或者样式。

做一个功能正常的App,开发者需要遵循一些开发守则,与此同时,设计师也需要有一套标准来设计Android UI,所有的Android UI设计指南都在这里了。
http://developer.android.com/design/style/devices-displays.html
9Path这个简单易用的工具,很实用,必须推荐。
画个图标,都要出N种分辨率,每次机械操作实在有点弱爆,推荐一个牛X的工具:
其中的功能可以自动切图输出各种屏幕密度的icon,可视化构建布局,自动生成布局文件。
http://android-ui-utils.googlecode.com/hg/asset-studio/dist/index.html
推荐这个,设计师应该会很喜欢,秒切图。

实际开发中,考虑到包体积大小,不会在所有drawable中都放不同size的图片资源,而是只使用一套图片资源,编写不同的布局。个别特殊的图片资源就每个drawable文件夹中放相应的size,譬如程序图标,不按文件夹放可能会导致在Launcher显示失真。

虽然不作任何改动也可以在Android Pad上跑,但由于Pad屏幕较大,操作体验不一样,建议重新设计。
4. 开发Android APP时,配置文件应放在哪里(APP本地、远程WeB Server中)?应该如何考虑?
这个就要看需求了,如果只是本机使用,譬如保存软件设置,不需要联网操作的,那首选当然是保存在本地。
如果业务需要和服务器交互,可以做成云配置方式。为了跨平台的兼容性,可以考虑使用Google的ProtoBuf,比XML更小更快更简单,后台和终端定义一套协议,自动生成C++、Java或者Python代码。
https://developers.google.com/protocol-buffers/docs/overview?hl=zh-CN
5. Android APP测试方案通常考虑哪些因素?有测试方案的参考实例吗?
机型适配:屏幕大小,这个只能人工检验了(程序不知道你的UI长得好不好看)
Android版本(某些API在低版本上没有的,会Crash,推荐Lint静态扫描)
网络质量:联通、电信、移动、WiFi、弱网络等
安全性:网络数据必定经过加密处理;本地不保存安全信息(帐号密码等),或者加密保存
代码中敏感信息尽量使用byte数组而不是字符串代码混淆处理(Proguard)
SD卡剩余空间很少,没SD卡,双SD卡,飞行模式,时间有误等。
性能:CPU、内存占用(开发可以使用Linux的top命令或者DDMS里面的工具)
网络流量消耗(有各种第三方流量监控软件)
6. 开发Android APP时,为了提高工作效率,提高项目质量、通常需要抽象出一些lib出来,请列出经常用到的接口的名称和用途。

更多精彩可以上github搜搜,这就不班门弄斧了。

7. Android APP开发中其它需要提醒的问题
android4.4在UI线程无法进行网络操作不单只android API版本不一定导致运行异常,有些机型还使用Java 1.5进行编译,使用某些Java 1.6的函数会Crash的。
注意OOM问题,目前android手机已经有3G内存了,但并非一个应用就能使用全部内存。了解一下堆内存,一个软件至少一个进程,一个进程跑一个虚拟机,进程使用的堆内存大小,每部手机不一定一样。
Show Dialog的问题,永远要判断Activity是否还在。
使用了高版本的API函数,在低版本机器上挂了。
非UI线程不能操作UI。可能有各种权限被禁的问题。
没有浏览器、没有软件安装器、没有Email等发生ActivityNotFoundexception。
超快速连续点击按钮可能触发跑多个线程的问题。
Android4.4短信权限设置,原生系统带有新接口,第三方系统可能裁剪掉了。
8. 什么情况下发生OOM,如何避免?
图片操作(图片缩放、bitmap生成等)、序列化反序列化数据等会消耗大量内存。合理使用数据结构(链表和数组),及时释放引用,使用弱引用等能降低OOM情况发生。
9. 出现ANR怎么办?
如果Android程序某个操作执行等待超过5s,会出现ANR(Application Not Responding)的对话框,对于执行耗时的操作,譬如网络操作,就不能在主线程上进行了(Android 4.4不让你这样做了),这些任务应该跑在主线程外,譬如新建一个线程处理,或者自己写一个网络引擎对所有网络请求进行管理。
10. 如何跟踪研发质量?
Coverity接入: https://scan.coverity.com/
代码缺陷扫描,不扫不知道,一扫吓一跳。满分推荐!Fro Free!如果你写的是开源代码,还能直接接入GitHub,超方便。
Crash是无法避免的,我们能做的是尽量把Crash的情况减少。发出去的版本,用户发生Crash了,我们需要把Crash数据收集起来。所以软件需要做一个Crash上报,汇总整理。统计每个版本的Crash率,并把Crash按优先级进行修复。
当然,版本检查更新也少不了。
11. 如果跟踪用户对产品的反馈?
不管你写软件所用的技术有多么牛B,用户是不知道的,也不关心的。用户关心的是你的产品体验到底有多牛B。加上用户可以轻松反馈的反馈功能,你会发现有时用户的idea还不错的。
做出来的产品好还是不好,需要有产品数据支撑,所以加插相关数据统计上报点,哪个功能热门,新增用户多少,活跃用户多少,一目了然。
12. 安全检查
为避免异常情况的跳转或者恶意攻击,Android组件在启动时都需要判断传入的参数是否为空。
敏感信息需要进行权限限制或者加密处理。
能不暴露的组件就不暴露,在AndroidManifest中为组件加上android:exported=”false”属性。
需要暴露的组件通过自定义权限进行调用,添加自定义权限android:permission=”yourapp.permission.CALL”检测WebView漏洞http://security.tencent.com/index.php/opensource/detail/1
13. 常用工具有哪些:
Lint(清理资源、安全检查、layout优化等)
一般在提测前清理一下冗余资源,查一下有没有用了一些高API Level才有的接口,查一下安全问题。

Findbugs(检查java代码缺陷)
在开发工程中就可以对单个文件进行检查,有问题可以及时处理。

MAT(内存泄漏调试工具)http://www.eclipse.org/mat/
遇到内存或者性能问题时,一般会结合几种工具来查问题,找解决方法。

Method Profiling(统计方法耗时)

Eclipse Class Decompiler(从此Eclipse不怕看不到jar包内的代码了) http://feeling.sourceforge.net/update

Hierarchy Viewer(查看Activity堆栈、layout加载层次、像素眼)
只能连接开发板手机或者模拟器,如果你的手机连不上,搜一下“Hierarchy Viewer 真机”,各种教程教你如何连上。
Activity太多,有时出问题了,但又想不起这个页面叫什么名字,插上去,一目了然。

很清晰看出Layout布局层次, 还能显示计算layout耗时,绘图耗时,UI性能优化好帮手。

TinyPNG(压缩图片资源利器,山崩地裂推荐) https://tinypng.com/

7z(压缩APK利器,上线前压一下就可以,简单实用,五星推荐)

Apktool、Dex2jar 、jd-gui(反编译套装,你懂的)

Mark Man(设计师何苦为难工程师)

Beyond Compare(各种神对比,我喜欢对比代码)

Tcpdump(Linux dump包工具)
adb shell tcpdump -p -vv-s 0 -w /sdcard/capturenet.pcap
WireShark(查看网络dump包)
遇到棘手问题时,还是需要他们帮忙解决的。

CMD (很简单的脚本却能大大提高效率,大家多学多分享)
一些经常操作的动作,使用手工操作又耗时又麻烦还可能出错,使用命令行去操作的话会极大提供效率。

拖放安装应用,不用再弹出xx助手xx宝来的蜗牛速度安装了(速度快了,心情好了):
adb install %1
pause
卸载应用:
adb uninstall com.tencent.qqpim
拉去SD卡目录文件
adb pull /sdcard/test/log c:testlog
获取联系人db
adb pull /data/data/com.android.providers.contacts/databases/contacts2.db C:contact2.db
tcpdump包
adb shell tcpdump -p -vv -s 0 -w /sdcard/capturenet.pcap
SDK裁剪打包
裁目录:rd/s/q S:tencentsrcAGJ
裁文件:del S:tencentsrccomtencenttestTestApplication.java