转自: http://henryyang.iteye.com/blog/1188328
Java内存管理机制
在C++ 语言中,如果需要动态分配一块内存,程序员需要负责这块内存的整个生命周期。从申请分配、到使用、再到最后的释放。这样的过程非常灵活,但是却十分繁琐,程序员很容易由于疏忽而忘记释放内存,从而导致内存的泄露。 Java 语言对内存管理做了自己的优化,这就是垃圾回收机制。 Java 的几乎所有内存对象都是在堆内存上分配(基本数据类型除外),然后由 GC ( garbage collection)负责自动回收不再使用的内存。
上面是Java 内存管理机制的基本情况。但是如果仅仅理解到这里,我们在实际的项目开发中仍然会遇到内存泄漏的问题。也许有人表示怀疑,既然 Java 的垃圾回收机制能够自动的回收内存,怎么还会出现内存泄漏的情况呢?这个问题,我们需要知道 GC 在什么时候回收内存对象,什么样的内存对象会被 GC 认为是“不再使用”的。
Java中对内存对象的访问,使用的是引用的方式。在 Java 代码中我们维护一个内存对象的引用变量,通过这个引用变量的值,我们可以访问到对应的内存地址中的内存对象空间。在 Java 程序中,这个引用变量本身既可以存放堆内存中,又可以放在代码栈的内存中(与基本数据类型相同)。 GC 线程会从代码栈中的引用变量开始跟踪,从而判定哪些内存是正在使用的。如果 GC 线程通过这种方式,无法跟踪到某一块堆内存,那么 GC 就认为这块内存将不再使用了(因为代码中已经无法访问这块内存了)。
通过这种有向图的内存管理方式,当一个内存对象失去了所有的引用之后,GC 就可以将其回收。反过来说,如果这个对象还存在引用,那么它将不会被 GC 回收,哪怕是 Java 虚拟机抛出 OutOfMemoryError 。
Java内存泄露
一般来说内存泄漏有两种情况。一种情况如在C/C++ 语言中的,在堆中的分配的内存,在没有将其释放掉的时候,就将所有能访问这块内存的方式都删掉(如指针重新赋值);另一种情况则是在内存对象明明已经不需要的时候,还仍然保留着这块内存和它的访问方式(引用)。第一种情况,在 Java 中已经由于垃圾回收机制的引入,得到了很好的解决。所以, Java 中的内存泄漏,主要指的是第二种情况。
可能光说概念太抽象了,大家可以看一下这样的例子:
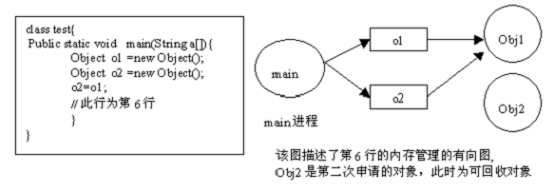
1 Vector v = new Vector( 10 );
2 for ( int i = 1 ;i < 100 ; i ++ ){
3 Object o = new Object();
4 v.add(o);
5 o = null ;
6 }
在这个例子中,代码栈中存在Vector 对象的引用 v 和 Object 对象的引用 o 。在 For 循环中,我们不断的生成新的对象,然后将其添加到 Vector 对象中,之后将 o 引用置空。问题是当 o 引用被置空后,如果发生 GC,我们创建的 Object 对象是否能够被 GC 回收呢?答案是否定的。因为, GC 在跟踪代码栈中的引用时,会发现 v 引用,而继续往下跟踪,就会发现 v 引用指向的内存空间中又存在指向 Object 对象的引用。也就是说尽管o 引用已经被置空,但是 Object 对象仍然存在其他的引用,是可以被访问到的,所以 GC 无法将其释放掉。如果在此循环之后, Object 对象对程序已经没有任何作用,那么我们就认为此 Java 程序发生了内存泄漏。
尽管对于C/C++ 中的内存泄露情况来说, Java 内存泄露导致的破坏性小,除了少数情况会出现程序崩溃的情况外,大多数情况下程序仍然能正常运行。但是,在移动设备对于内存和 CPU 都有较严格的限制的情况下,Java 的内存溢出会导致程序效率低下、占用大量不需要的内存等问题。这将导致整个机器性能变差,严重的也会引起抛出 OutOfMemoryError ,导致程序崩溃。
一般情况下内存泄漏的避免
在不涉及复杂数据结构的一般情况下,Java 的内存泄露表现为一个内存对象的生命周期超出了程序需要它的时间长度。我们有时也将其称为“对象游离”。
例如:
1 public class FileSearch{
2
3 private byte [] content;
4 private File mFile;
5
6 public FileSearch(File file){
7 mFile = file;
8 }
9
10 public boolean hasString(String str){
11 int size = getFileSize(mFile);
12 content = new byte [size];
13 loadFile(mFile, content);
14
15 String s = new String(content);
16 return s.contains(str);
17 }
18 }
在这段代码中,FileSearch 类中有一个函数 hasString ,用来判断文档中是否含有指定的字符串。流程是先将mFile 加载到内存中,然后进行判断。但是,这里的问题是,将 content 声明为了实例变量,而不是本地变量。于是,在此函数返回之后,内存中仍然存在整个文件的数据。而很明显,这些数据我们后续是不再需要的,这就造成了内存的无故浪费。
要避免这种情况下的内存泄露,要求我们以C/C++ 的内存管理思维来管理自己分配的内存。第一,是在声明对象引用之前,明确内存对象的有效作用域。在一个函数内有效的内存对象,应该声明为 local 变量,与类实例生命周期相同的要声明为实例变量……以此类推。第二,在内存对象不再需要时,记得手动将其引用置空。
复杂数据结构中的内存泄露问题
在 实际的项目中,我们经常用到一些较为复杂的数据结构用于缓存程序运行过程中需要的数据信息。有时,由于数据结构过于复杂,或者我们存在一些特殊的需求(例 如,在内存允许的情况下,尽可能多的缓存信息来提高程序的运行速度等情况),我们很难对数据结构中数据的生命周期作出明确的界定。这个时候,我们可以使用Java 中一种特殊的机制来达到防止内存泄露的目的。
之前我们介绍过,Java 的 GC 机制是建立在跟踪内存的引用机制上的。而在此之前,我们所使用的引用都只是定义一个“ Object o; ”这样形式的。事实上,这只是 Java 引用机制中的一种默认情况,除此之外,还有其他的一些引用方式。通过使用这些特殊的引用机制,配合 GC 机制,就可以达到一些我们需要的效果。
Java中的几种引用方式
Java中有几种不同的引用方式,它们分别是:强引用、软引用、弱引用和虚引用。下面,我们首先详细地了解下这几种引用方式的意义。
强引用
在此之前我们介绍的内容中所使用的引用 都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空 间不足,Java 虚拟机宁愿抛出OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
软引用(SoftReference )
SoftReference 类的一个典型用途就是用于内存敏感的高速缓存。 SoftReference 的原理是:在保持对对象的引用时保证在 JVM 报告内存不足情况之前将清除所有的软引用。关键之处在于,垃圾收集器在运行时可能会(也可能不会)释放软可及对象。对象是否被释放取决于垃圾收集器的算法 以及垃圾收集器运行时可用的内存数量。
弱引用(WeakReference )
WeakReference 类的一个典型用途就是规范化映射( canonicalized mapping )。另外,对于那些生存期相对较长而且重新创建的开销也不高的对象来说,弱引用也比较有用。关键之处在于,垃圾收集器运行时如果碰到了弱可及对象,将释放 WeakReference 引用的对象。然而,请注意,垃圾收集器可能要运行多次才能找到并释放弱可及对象。
虚引用(PhantomReference )
PhantomReference 类只能用于跟踪对被引用对象即将进行的收集。同样,它还能用于执行 pre-mortem 清除操作。PhantomReference 必须与 ReferenceQueue 类一起使用。需要 ReferenceQueue 是因为它能够充当通知机制。当垃圾收集器确定了某个对象是虚可及对象时, PhantomReference 对象就被放在它的 ReferenceQueue 上。将 PhantomReference 对象放在 ReferenceQueue 上也就是一个通知,表明 PhantomReference 对象引用的对象已经结束,可供收集了。这使您能够刚好在对象占用的内存被回收之前采取行动。 Reference与 ReferenceQueue 的配合使用。
GC、 Reference 与 ReferenceQueue 的交互
A、 GC无法删除存在强引用的对象的内存。
B、 GC发现一个只有软引用的对象内存,那么:
① SoftReference对象的 referent 域被设置为 null ,从而使该对象不再引用 heap 对象。
② SoftReference引用过的 heap 对象被声明为 finalizable 。
③ 当 heap 对象的 finalize() 方法被运行而且该对象占用的内存被释放, SoftReference 对象就被添加到它的 ReferenceQueue (如果后者存在的话)。
C、 GC发现一个只有弱引用的对象内存,那么:
① WeakReference对象的 referent 域被设置为 null , 从而使该对象不再引用heap 对象。
② WeakReference引用过的 heap 对象被声明为 finalizable 。
③ 当heap 对象的 finalize() 方法被运行而且该对象占用的内存被释放时, WeakReference 对象就被添加到它的ReferenceQueue (如果后者存在的话)。
D、 GC发现一个只有虚引用的对象内存,那么:
① PhantomReference引用过的 heap 对象被声明为 finalizable 。
② PhantomReference在堆对象被释放之前就被添加到它的 ReferenceQueue 。
值得注意的地方有以下几点:
1、 GC 在一般情况下不会发现软引用的内存对象,只有在内存明显不足的时候才会发现并释放软引用对象的内存。
2、 GC 对弱引用的发现和释放也不是立即的,有时需要重复几次 GC ,才会发现并释放弱引用的内存对象。
3、软引用和弱引用在添加到 ReferenceQueue 的时候,其指向真实内存的引用已经被置为空了,相关的内存也已经被释放掉了。而虚引用在添加到 ReferenceQueue 的时候,内存还没有释放,仍然可以对其进行访问。
代码示例
通过以上的介绍,相信您对Java 的引用机制以及几种引用方式的异同已经有了一定了解。光是概念,可能过于抽象,下面我们通过一个例子来演示如何在代码中使用 Reference 机制。
1 String str = new String( " hello " ); // ①
2 ReferenceQueue < String > rq = new ReferenceQueue < String > (); // ②
3 WeakReference < String > wf = new WeakReference < String > (str, rq); // ③
4 str = null ; // ④取消"hello"对象的强引用
5 String str1 = wf.get(); // ⑤假如"hello"对象没有被回收,str1引用"hello"对象
6 // 假如"hello"对象没有被回收,rq.poll()返回null
7 Reference <? extends String > ref = rq.poll(); // ⑥
在以上代码中,注意⑤⑥两处地方。假如“hello ”对象没有被回收 wf.get() 将返回“ hello ”字符串对象,rq.poll() 返回 null ;而加入“ hello ”对象已经被回收了,那么 wf.get() 返回 null , rq.poll() 返回 Reference对象,但是此 Reference 对象中已经没有 str 对象的引用了 ( PhantomReference 则与WeakReference 、SoftReference 不同 )。
引用机制与复杂数据结构的联合应用
了解了GC 机制、引用机制,并配合上 ReferenceQueue ,我们就可以实现一些防止内存溢出的复杂数据类型。
例如,SoftReference 具有构建 Cache 系统的特质,因此我们可以结合哈希表实现一个简单的缓存系统。这样既能保证能够尽可能多的缓存信息,又可以保证 Java 虚拟机不会因为内存泄露而抛出 OutOfMemoryError 。这种缓存机制特别适合于内存对象生命周期长,且生成内存对象的耗时比较长的情况,例如缓存列表封面图片等。对于一些生命周期较长,但是生成内存对象开销不大的情况,使用WeakReference 能够达到更好的内存管理的效果。
附SoftHashmap 的源码一份,相信看过之后,大家会对 Reference 机制的应用有更深入的理解。
1
![]()
package com. *** .widget;
2
![]()
3
![]()
// : SoftHashMap.java
4
![]()
import java.util. * ;
5
![]()
import java.lang.ref. * ;
6
![]()
7
![]()
import android.util.Log;
8
![]()
9
![]()
public class SoftHashMap extends AbstractMap {
10
![]()
/** The internal HashMap that will hold the SoftReference. */
11
![]()
private final Map hash = new HashMap();
12
![]()
/** The number of "hard" references to hold internally. */
13
![]()
private final int HARD_SIZE;
14
![]()
/** The FIFO list of hard references, order of last access. */
15
![]()
private final LinkedList hardCache = new LinkedList();
16
![]()
/** Reference queue for cleared SoftReference objects. */
17
![]()
private ReferenceQueue queue = new ReferenceQueue();
18
![]()
19
![]()
// Strong Reference number
20
![]()
public SoftHashMap() { this ( 100 ); }
21
![]()
public SoftHashMap( int hardSize) { HARD_SIZE = hardSize; }
22
![]()
23
![]()
24
![]()
public Object get(Object key) {
25
![]()
Object result = null ;
26
![]()
// We get the SoftReference represented by that key
27
![]()
SoftReference soft_ref = (SoftReference)hash.get(key);
28
![]()
if (soft_ref != null ) {
29
![]()
// From the SoftReference we get the value, which can be
30
![]()
// null if it was not in the map, or it was removed in
31
![]()
// the processQueue() method defined below
32
![]()
result = soft_ref.get();
33
![]()
if (result == null ) {
34
![]()
// If the value has been garbage collected, remove the
35
![]()
// entry from the HashMap.
36
![]()
hash.remove(key);
37
![]()
} else {
38
![]()
// We now add this object to the beginning of the hard
39
![]()
// reference queue. One reference can occur more than
40
![]()
// once, because lookups of the FIFO queue are slow, so
41
![]()
// we don't want to search through it each time to remove
42
![]()
// duplicates.
43
![]()
// keep recent use object in memory
44
![]()
hardCache.addFirst(result);
45
![]()
if (hardCache.size() > HARD_SIZE) {
46
![]()
// Remove the last entry if list longer than HARD_SIZE
47
![]()
hardCache.removeLast();
48
![]()
}
49
![]()
}
50
![]()
}
51
![]()
return result;
52
![]()
}
53
![]()
54
![]()
/** We define our own subclass of SoftReference which contains
55
![]()
not only the value but also the key to make it easier to find
56
![]()
the entry in the HashMap after it's been garbage collected. */
57
![]()
private static class SoftValue extends SoftReference {
58
![]()
private final Object key; // always make data member final
59
![]()
/** Did you know that an outer class can access private data
60
![]()
members and methods of an inner class? I didn't know that!
61
![]()
I thought it was only the inner class who could access the
62
![]()
outer class's private information. An outer class can also
63
![]()
access private members of an inner class inside its inner
64
![]()
class. */
65
![]()
private SoftValue(Object k, Object key, ReferenceQueue q) {
66
![]()
super (k, q);
67
![]()
this .key = key;
68
![]()
}
69
![]()
}
70
![]()
71
![]()
/** Here we go through the ReferenceQueue and remove garbage
72
![]()
collected SoftValue objects from the HashMap by looking them
73
![]()
up using the SoftValue.key data member. */
74
![]()
public void processQueue() {
75
![]()
SoftValue sv;
76
![]()
while ((sv = (SoftValue)queue.poll()) != null ) {
77
![]()
if (sv.get() == null ) {
78
![]()
Log.e( " processQueue " , " null " );
79
![]()
} else {
80
![]()
Log.e( " processQueue " , " Not null " );
81
![]()
}
82
![]()
hash.remove(sv.key); // we can access private data!
83
![]()
Log.e( " SoftHashMap " , " release " + sv.key);
84
![]()
}
85
![]()
}
86
![]()
/** Here we put the key, value pair into the HashMap using
87
![]()
a SoftValue object. */
88
![]()
public Object put(Object key, Object value) {
89
![]()
processQueue(); // throw out garbage collected values first
90
![]()
Log.e( " SoftHashMap " , " put into " + key);
91
![]()
return hash.put(key, new SoftValue(value, key, queue));
92
![]()
}
93
![]()
public Object remove(Object key) {
94
![]()
processQueue(); // throw out garbage collected values first
95
![]()
return hash.remove(key);
96
![]()
}
97
![]()
public void clear() {
98
![]()
hardCache.clear();
99
![]()
processQueue(); // throw out garbage collected values
100
![]()
hash.clear();
101
![]()
}
102
![]()
public int size() {
103
![]()
processQueue(); // throw out garbage collected values first
104
![]()
return hash.size();
105
![]()
}
106
![]()
public Set entrySet() {
107
![]()
// no, no, you may NOT do that!!! GRRR
108
![]()
throw new UnsupportedOperationException();
109
![]()
}
110
![]()
}
111
![]()
112
![]()
113
![]()









 package com. *** .widget;
package com. *** .widget;  public class SoftHashMap extends AbstractMap {
public class SoftHashMap extends AbstractMap {  /** The internal HashMap that will hold the SoftReference. */
/** The internal HashMap that will hold the SoftReference. */  private final Map hash = new HashMap();
private final Map hash = new HashMap();  }
}  }
}