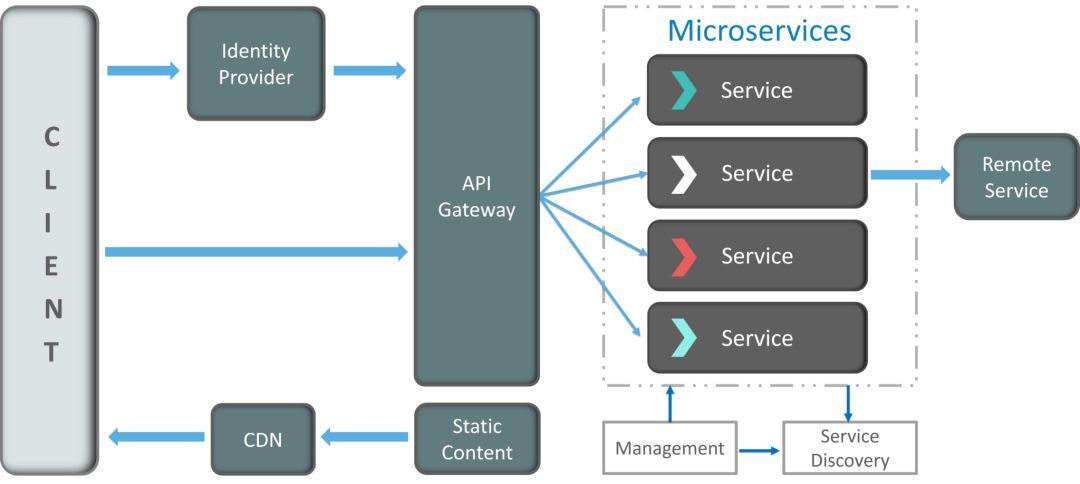
![]()
![]()
【原创声明】
作者:王一鸣
来源:物联江湖(iot521)
欢迎转载,请保留本声明,谢谢 !
作者文章链接:
物联网的网络视角∣ 物联网解析2∣ 物联网的价值
边缘计算1∣ 边缘计算2∣ 边缘网络接入方式
物联网平台∣ Predix∣ GE的物联网平台∣ Jasper
共享经济∣ 共享单车技术∣
物联网的技术本质∣ 物联网技术语言∣ 物联网技术全矩阵图景∣ 物联网技术概念
蓝牙技术∣ 蓝牙Mesh∣从M2M到物联网∣物联网网络结构∣网络的未来
![]()
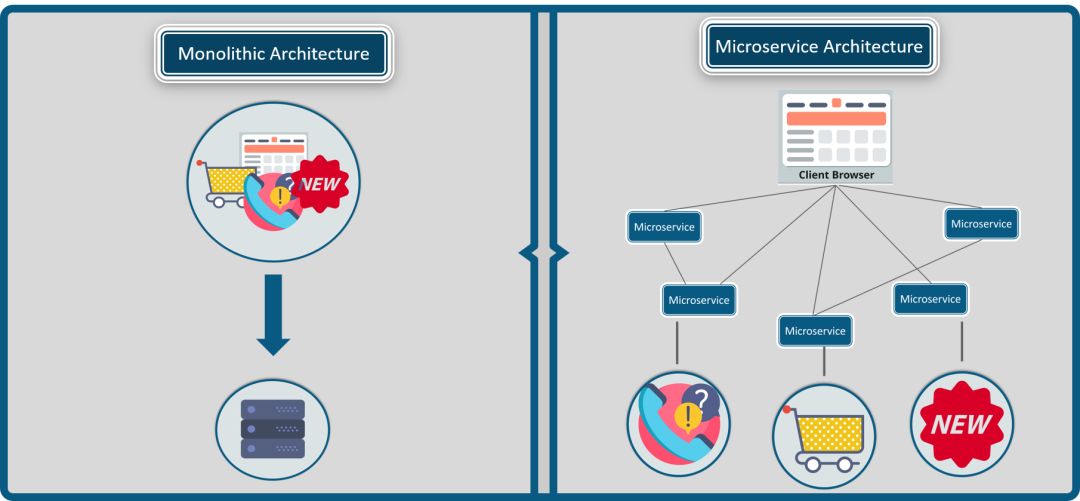
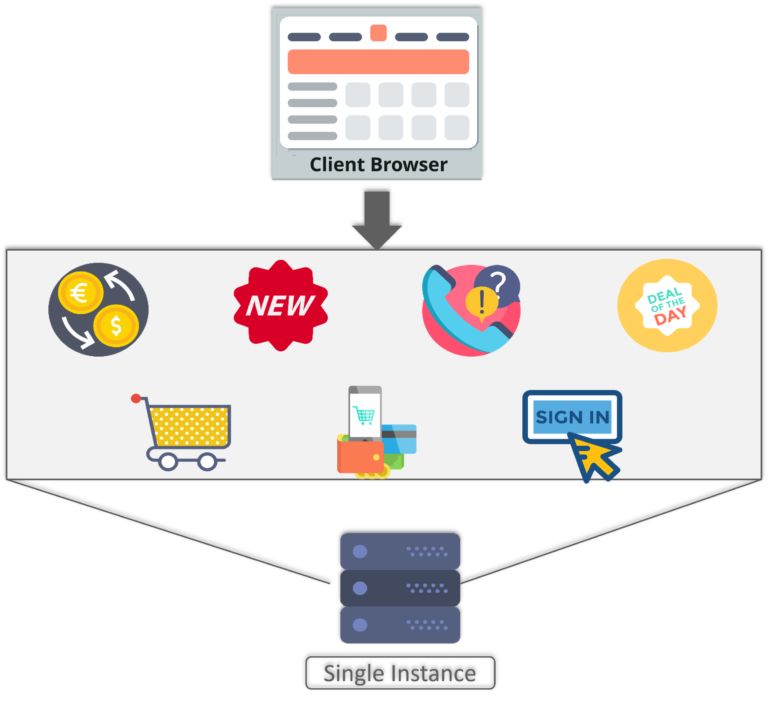
一直以来,人们通过相应的终端(电脑、手机、平板等)使用网络服务,“个人”一直是网络的用户主体。个人对网络质量的要求“高”且“统一”:玩网络游戏必需要低时延,下载文件或看网络视频则期望高带宽,通话需要声音清晰,而接收的短信绝不能有遗漏。
对于移动通信网络,运营商们尽可能地维系着低时延、高带宽、广覆盖、随取随用的网络特性,以保证良好的用户体验,以及营造出丰富多姿的移动应用生态。
对于个人通信业务,虽然用户的要求很高,但整体上对网络质量的需求是一致的,运营商只需要建立一套网络质量标准体系来建设、优化网络,就能满足大多数人对连接的需要。
随着网络中用户终端(手机、PAD等)数量的增长逐渐趋缓,M2M应用成为了运营商网络业务的增长发力点,大量的M2M应用终端则成为了网络的用户。M2M应用终端(传感设备、智能终端),本质上就是物联网终端,它们通过装配无线通信模组和SIM卡,连接到运营商网络,从而构建出各类集中化、数字化的行业应用。
不同于个人通信业务, 在物联网终端构建的行业应用中,各领域应用对信息采集、传递、计算的质量要求差异很大;系统和终端部署的环境也各不相同,特别是千差万别的工业环境;此外,企业在构建应用时,还需要考量技术限制(供电问题、终端体积等)和成本控制(包括建设成本和运营成本)。因此,千姿百态的行业应用具有“个性化”的一面,使得连接的需求朝着多样性的方向发展。
1.物联网业务需求的差异化,体现在两个方面
一方面,不同的终端和应用对网络特性有不同的要求。传统的网络特性包括:网络接入的距离、上下行的网络带宽、移动性的支持、还有数据收发的频率(或称为周期性)、以及安全性和数据传输质量(完整性、稳定性、时效性等)。这几个方面可浓缩成三个方面,为“接入距离”、“网络特性”、“网络品质”。“接入距离”主要分为近距接入和远距接入两种。网络的“特性”和“品质”则是体现需求差异化的主要因素,例如传感器终端的“网络特性”可能是:只有向云端发送的“上行数据”,而没有接收的“下行数据”。
另一方面,网络还需要“照顾”原本不太被关注的终端特性,以适应各类的行业应用需求:对“能耗”和“成本”的控制。
(1)能耗
个人用户大多数时间都是处于宜居的环境中,智能终端常伴左右,并且在人类活动的环境中总能找到充电的“电源插头”,所以这些终端的生产厂家对电池的电量并不敏感。
而物联网终端的工作环境相比较个人终端的工作环境,则要复杂的多。有些物联网终端会部署在高温高压的工业环境中,有些则远离城市、放置在人迹罕至的边远地区,还有一些可能深嵌地下或落户在溪流湖泊之中。
很多设备需要电池的长期供电来工作,因为地理位置和工作环境无法向它们提供外部电源,更换电池的成本也异常高昂。所以“低功耗”是保证他们持续工作的一个关键需求。在不少应用场景中,一小粒电池的电量需要维持某个终端“一生”的能量供给。
(2)成本
个人使用的终端,不论是电脑还是手机,其功能丰富、计算能力强大、应用广泛,通信模块只是其所有电子元件和机械构建中的一小部分,在总的制造成本中占比较低。
个人终端作为较高价值的产品,用户、厂家对其通信单元的固定成本并不特别敏感。而物联网终端则不同,许多不具备联网功能的终端原本只是简易的传感器设备,其功能简单、成本低廉,相对于传感设备,价格不菲的通信模块加入其中,就可能引起成本骤升。
在应用场景中大量部署联网的传感设备,往往需要企业下决心提高终端的成本投入。而与此矛盾的是:简单的传感器终端上传网络的数据量通常都很小;它们连接网络的周期长(网络的使用频次低);每一次上传信息的价值都很低。终端成本和信息价值不成比例,使得企业会在大量部署物联网终端的决策上犹豫不前。如何降低这些哑终端(单一的传感器终端)的通信成本,是一个迫在眉睫的难题。
此前提及的能耗问题,如果不妥善解决,也会影响到物联网应用的运营成本:如果终端耗电过快,就需要不断地重新部署投放或更换电池。
2.低功耗、低成本是物联网通信的一大需求
原本的网络对应用并不敏感,只要提供统一的高质量网络通道(标准唯一),就可以满足大多数用户的需求。不论用户喜欢使用什么样的业务,都可以通过高品质的网络质量来获得通信服务,网络能够满足个人用户的大多数要求。
然而随着行业应用的深入,网络设计和建设者必须关注到应用、终端的差异性,也就是网络需要针对终端、应用做出相应的调整和适配。
在此前提到的网络特性和终端特性中:“距离、品质、特性”和“能耗、成本”,前后两类特性存在密切的关联关系:通信基站的信号覆盖越广(“距离长”),则基站和终端的功耗越高(“能耗高”);要实现高品质、安全可靠的网络服务(“品质高”),需要健壮的通信协议实现差错效验、身份验证、重传机制、以建立端到端的可靠连接,保证的基础就是通信模块的配置就不能低(“成本高”)
![]()
运营商在推广M2M服务(物联网应用)的时候,发现企业对M2M的业务需求,不同与个人用户的需求。企业希望构建集中化的信息系统,与自身资产建立长久的通信连接,以便于管理和监控。
这些资产,往往分布各地,而且数量巨大;资产上配备的通信设备可能没有外部供电的条件(即电池供电,而且可能是一次性的,既无法充电也无法更换电池);单一的传感器终端需要上报的数据量小、周期长;企业需要低廉的通信成本(包括通信资费、装配通信模块的成本费用)。
以上这种应用场景在网络层面具有较强的统一性,所以通信领域的组织、企业期望能够对现有的通信网络技术标准进行一系列优化,以满足此类M2M业务的一致性需求。
2013年,沃达丰与华为携手开始了新型通信标准的研究,起初他们将该通信技术称为“NB-M2M(LTE for Machine to Machine)”。
2014年5月份,3GPP的GERAN组成立了新的研究项目:“FS_IoT_LC”,该项目主要研究新型的无线电接入网系统,“NB-M2M”成为了该项目研究方向之一。稍后,高通公司提交了“NB-OFDM”(Narrow Band Orthogonal Frequency Division Multiplexing, 窄带正交频分复用)的技术方案。
(3GPP,“第三代合作伙伴计划(3rd Generation Partnership Project)”标准化组织;TSG-GERAN (GSM/EDGE Radio Access Network):负责GSM/EDGE无线接入网技术规范的制定)
2015年5月,“NB-M2M”方案和“NB-OFDM方案”融合成为“NB-CIoT”(Narrow Band Cellular IoT)。该方案的融合之处主要在于:通信上行采用FDMA多址方式,而下行采用OFDM多址方式。
2015年7月,爱立信联合中兴、诺基亚等公司,提出了“NB-LTE”(Narrow Band LTE)的技术方案。
在2015年9月的RAN#69次全会上,经过激烈的讨论和协商,各方案的主导者将两个技术方案(“NB-CIoT”、“NB-LTE”)进行了融合,3GPP对统一后的标准工作进行了立项。该标准作为统一的国际标准,称为“NB-IoT(Narrow Band Internet of Things,基于蜂窝的窄带物联网)”。自此,“NB-M2M”、“NB-OFDM”、“NB-CIoT”、“NB-LTE”都成为了历史。
2016年6月,NB-IoT的核心标准作为物联网专有协议,在3GPP Rel-13冻结。同年9月,完成NB-IoT性能部分的标准制定。2017年1月,完成NB-IoT一致性测试部分的标准制定。
![]()
在我看来,促成这几种低功耗蜂窝技术“结盟”的关键,并不仅仅是日益增长的商业诉求,还有其它新生的(非授权频段)低功耗接入技术的威胁。LoRa、SIGFOX、RPMA等新兴接入技术的出现,促成了3PGG中相关成员企业和组织的抱团发展。
![]()
和其竞争对手一样,NB-IoT着眼于低功耗、广域覆盖的通信应用。终端的通信机制相对简单,无线通信的耗电量相对较低,适合小数据量、低频率(低吞吐率)的信息上传,信号覆盖的范围则与普通的移动网络技术基本一样,行业内将此类技术统称为“LPWAN技术”(Low Power Wide Area,低功耗广域技术)。
NB-IoT针对M2M通信场景对原有的4G网络进行了技术优化,其对网络特性和终端特性进行了适当地平衡,以适应物联网应用的需求。
在“距离、品质、特性”和“能耗、成本”中,保证“距离”上的广域覆盖,一定程度地降低“品质”(例如采用半双工的通信模式,不支持高带宽的数据传送),减少“特性”(例如不支持切换,即连接态的移动性管理 )。
网络特性“缩水”的好处就是:同时也降低了终端的通信“能耗”,并可以通过简化通信模块的复杂度来降低“成本”(例如简化通信链路层的处理算法)。
所以说,为了满足部分物联网终端的个性要求(低能耗、低成本),网络做出了“妥协”。NB-IoT是“牺牲”了一些网络特性,来满足物联网中不同以往的应用需要。
1.部署方式
![]()
为了便于运营商根据自由网络的条件灵活运用,NB-IoT可以在不同的无线频带上进行部署,分为三种情况:独立部署(Stand alone)、保护带部署(Guard band)、带内部署(In band)。
Stand alone模式:利用独立的新频带或空闲频段进行部署,运营商所提的“GSM频段重耕”也属于此类模式;
Guard band模式:利用LTE系统中边缘的保护频段。采用该模式,需要满足一些额外的技术要求(例如原LTE频段带宽要大于5Mbit/s),以避免LTE和NB-IoT之间的信号干扰。
In band模式:利用LTE载波中间的某一段频段。为了避免干扰,3GPP要求该模式下的信号功率谱密度与LTE信号的功率谱密度不得超过6dB。
除了Stand alone模式外,另外两种部署模式都需要考虑和原LTE系统的兼容性,部署的技术难度相对较高,网络容量相对较低。
2.覆盖增强
为了增强信号覆盖,在NB-IoT的下行无线信道上,网络系统通过重复向终端发送控制、业务消息(“重传机制”),再由终端对重复接受的数据进行合并,来提高数据通信的质量。
这样的方式可以增加信号覆盖的范围,但数据重传势必将导致时延的增加,从而影响信息传递的实时性。在信号覆盖较弱的地方,虽然NB-IoT能够保证网络与终端的连通性,但对部分实时性要求较高的业务就无法保证了。
在NB-IoT的上行信道上,同样也支持无线信道上的数据重传。此外,终端信号在更窄的LTE带宽中发送,可以实现单位频谱上的信号增强,使PSD(Power Spectrum Density,功率谱密度)增益更大。通过增加功率谱密度,更利于网络接收端的信号解调,提升了上行无线信号在空中的穿透能力。
![]()
通过上行、下行信道的优化设计,NB-IoT信号的“耦合损耗(coupling loss)”最高可以达到164dB。
(备注: 耦合损耗,指能量从一个电路系统传播到另一个电路系统时发生的能量损耗。这里是指无线信号在空中传播的能量损耗)
为了进一步利用网络系统的信号覆盖能力,NB-IoT还根据信号覆盖的强度进行了分级(CE Level),并实现“寻呼优化”:引入PTW(寻呼传输窗),允许网络在一个PTW内多次寻呼UE,并根据覆盖等级调整寻呼次数。
常规覆盖(Normal Coverage),其MCL(Maximum Coupling Loss,最大耦合损耗)小于144dB,与目前的GPRS覆盖一致。
扩展覆盖(Extended Coverage),其MCL介于144dB与154dB之间,相对GPRS覆盖有10dB的增强
极端覆盖(Extreme Coverage),其MCL最高可达164dB,相对GPRS覆盖强度提升了20dB。
3. NB-IoT低功耗的实现
要终端通信模块低功耗运行,最好的办法就是尽量地让其“休眠”。NB-IoT有两种模式,可以使得通信模块只在约定的一段很短暂的时间段内,监听网络对其的寻呼,其它时间则都处于关闭的状态。这两种“省电”模式为:PSM(power saving mode,省电模式)和eDRX(Extended Discontinuous Reception,扩展的不连续接收)
(1) PSM模式
在PSM模式下,终端设备的通信模块进入空闲状态一段时间后,会关闭其信号的收发以及接入层的相关功能。当设备处于这种局部关机状态的时候,即进入了省电模式-PSM。终端以此可以减少通信元器件(天线、射频等)的能源消耗。
终端进入省电模式期间,网络是无法访问到该终端。从语音通话的角度来说,即“无法被叫”。
大多数情况下,采用PSM的终端,超过99%的时间都处于休眠的状态,主要有两种方式可以激活他们和网络的通信:
当终端自身有连接网络的需求时,它会退出PSM的状态,并主动与网络进行通信,上传业务数据。
在每一个周期性的TAU (Tracking Area Update,跟踪区更新)中,都有一小段时间处于激活的状态。在激活状态中,终端先进入“连接状态(Connect)”,与通信网络交互其网络、业务的数据。在通信完成后,终端不会立刻进入PSM状态,而是保持一段时间为“空闲状态(IDLE)”。在空闲状态状态下,终端可以接受网络的寻呼。
在PSM的运行机制中,使用“激活定时器(Active Timer,简称AT)”控制空闲状态的时长,并由网络和终端在网络附着(Attach,终端首次登记到网络)或TAU时协商决定激活定时器的时长。终端在空闲状态下出现AT超时的时候,便进入了PSM状态。
根据标准,终端的一个TAU周期最大可达310H(小时);“空闲状态”的时长最高可达到3.1小时(11160s)。
从技术原理可以看出,PSM适用于那些几乎没有下行数据流量的应用。云端应用和终端的交互,主要依赖于终端自主性地与网络联系。绝大多数情况下,云端应用是无法实时“联系“到终端的。
(2) PSM模式
在PSM模式下,网络只能在每个TAU最开始的时间段内寻呼到终端(在连接状态后的空闲状态进行寻呼)。eDRX模式的运行不同于PSM,它引入了eDRX机制,提升了业务下行的可达性。
(备注:DRX(Discontinuous Reception),即不连续接收。eDRX就是扩展的不连续接收。)
eDRX模式,在一个TAU周期内,包含有多个eDRX周期,以便于网络更实时性地向其建立通信连接(寻呼)。
eDRX的一个TAU包含一个连接状态周期和一个空闲状态周期,空闲状态周期中则包含了多个eDRX寻呼周期,每个eDRX寻呼周期又包含了一个PTW周期和一个PSM周期。PTW和PSM的状态会周期性地交替出现在一个TAU中,使得终端能够间歇性地处于待机的状态,等待网络对其的呼叫。
![]()
eDRX模式下,网络和终端建立通信的方式同样:终端主动连接网络;终端在每个eDRX周期中的PTW内,接受网络对其的寻呼。
在TAU中,最小的eDRX周期为20.48秒,最大周期为2.91小时
在eDRX中,最小的PTW周期为2.56秒,最大周期为40.96秒
在PTW中,最小的DRX周期为1.28秒,最大周期为10.24秒
总体而言,在TAU一致的情况下,eDRX模式相比较PSM模式,其空闲状态的分布密度更高,终端对寻呼的响应更为及时。eDRX模式适用的业务,一般下行数据传送的需求相对较多,但允许终端接受消息有一定的延时(例如云端需要不定期地对终端进行配置管理、日志采集等)。根据技术差异,eDRX模式在大多数情况下比PSM模式更耗电。
4. 终端简化带来低成本
针对数据传输品质要求不高的应用,NB-IoT具有低速率、低带宽、非实时的网路特性,这些特性使得NB-IoT终端不必向个人用户终端那样复杂,简单的构造、简化的模组电路依然能够满足物联网通信的需要。
NB-IoT采用半双工的通信方式,终端不能够同时发送或接受信号数据,相对全双工方式的终端,减少了元器件的配置,节省了成本。
业务低速率的数据流量,使得通信模组不需要配置大容量的缓存。低带宽,则降低了对均衡算法的要求,降低了对均衡器性能的要求。(均衡器主要用于通过计算抵消无线信道干扰)
NB-IoT通信协议栈基于LTE设计,但它系统性地简化了协议栈,使得通信单元的软件和硬件也可以相应的降低配置:终端可以使用低成本的专用集成电路来替代高成本的通用计算芯片,来实现协议简化后的功能。这样还能够减少通信单元的整体功耗,延长电池使用寿命。
5.业务在核心网络中的简化
在NB-IoT的核心网络(EPC- Evolved Packet Core,即4G核心网)中,针对物联网业务的需求特性,蜂窝物联网(CIoT)定义了两种优化方案:
CIoT EPS用户面功能优化(User Plane CIoT EPS optimisation)
CIoT EPS控制面功能优化(Control Plane CIoT EPS optimisation)
(1) 用户面功能优化
“用户面功能优化”与原LTE业务的差异并不大,它的主要特性是引入RRC (无线资源控制)的“挂起/恢复(Suspend/Resume)流程”,减少了终端重复进行网络接入的信令开销。
当终端和网络之间没有数据流量时,网络将终端置为挂起状态(Suspend),但在终端和网络中仍旧保留原有的连接配置数据。
当终端重新发起业务时,原配置数据可以立即恢复通信连接(Resume),以此减去了重新进行RRC重配、安全验证等流程,降低了无线空口上的信令交互量。
(2) 控制面功能优化
“控制面功能优化”包括两种实现方式(消息传递路径)。通过这两种方式,终端不必在无线空口上和网络建立业务承载,就可以将业务数据直接传递到网络中。
备注:通信系统的特性之一是控制与承载(业务)分离,直观的来说就是业务的控制消息(建立业务、释放业务、修改业务)和业务数据本身并不在同一条链路上混合传递。NB-IoT的控制面功能优化则简化了这种惯常的信息业务架构。
CP模式的两种实现方式,即两种数据传递的路径:
![]()
A.在核心网内,由MME、SCEF网元负责业务数据的转接
在该方式中,NB-IoT引入了新的网元:SCEF(Service Capa- bility Exposure Function,服务能力开放平台)。物联网终端接受或发送业务数据,是通过无线信令链路进行的,而非无线业务链路。
当终端需要上传数据时,业务数据由无线信令消息携带,直接传递到核心网的网元MME(Mobility Management Entity,4G核心网中的移动性管理实体),再由MME通过新增的SCEF网元转发到CIoT服务平台(CIoT Services,也称为AP-应用服务)。云端向终端发送业务数据的方向则和上传方向正好相反。
路径:UE(终端)-MME-SCEF- CIoT Services
B.在核心网内,通过MME与业务面交互业务数据
在该方式中,终端同样通过无线信令链路收发业务数据。对于业务数据的上传,是由MME设备将终端的业务数据送入核心网的业务面网元SGW,再通过PGW进入互联网平台;对于下传业务数据,则由SGW传递给MME,再由MME通过无线信令消息送给终端。业务数据上传和下传的路径也是一致的。
路径:UE(终端)-MME-SGW-PGW-CIoT Services
按照传统流程(包括用户面优化方案),终端需要和网络先建立SRB(Signaling Radio Bearer)再建立DRB(Data Radio Bearer),才能够在无线通道上传输数据。而采用控制面优化方案(CP模式),只需要建立SRB就可以实现业务数据的收发。
(3)功能优化模式总结
CP方式借鉴了短距通信的一些设计思路,非常适合低频次、小数据包的上传业务,类似于短信业务。但网络中“信令面”的带宽有限,CP方式所以并不适合传递较大的业务数据包。UP模式则可以满足大数据业务的传递。
不论是UP模式,还是CP模式,本质上都是通过无线通信流程的简化,节省了终端的通信计算和能量消耗,提升了数据传递效率。
6.连接态的移动性管理
最初,NB-IoT的规范是针对静态的应用场景(如智能抄表)进行设计和制定的,所以在Rel-13版本(2016年6月)中它并不支持连接状态下的移动性管理,即不支持“无线切换”。在随后的Rel-14版本中,NB-IoT会支持基站小区间的切换,以保证业务在移动状态下的连续性。
![]()
从NB-IoT的特性中可以看出,其通过“信号增强”、“寻呼优化”加强了通信覆盖的深度。主要通过三个方面,来“照顾”终端对低耗电、低成本的要求:
1、引入了低功耗的“睡眠”模式(PSM、eDRX);
2、降低了对通信品质要求,简化了终端设计(半双工模式、协议栈简化等);
3、通过两种功能优化模式(CP模式、UP模式)简化流程,减少了终端和网络的交互量。
这些对广域移动通信技术的“优化”设计,使得NB-IoT更加适合于部分物联网的场景应用,也就是LPWA(低功耗广域网)类型的应用。并且由于引入了睡眠模式,降低了通信品质的要求(主要是实时性要求),使得NB-IoT的基站比传统基站,能够接入更多的(承载LPWA业务的)终端。
采用NB-IoT的终端可以在满足低功耗的需求下,用于较高密度部署、低频次数据采集的应用(包括固定位置的抄表、仓储和物流管理、城市公共设置的信息采集等),或者是较低密度部署、长距离通信连接的应用(包括农情监控、地质水文监测等)。
当然,作为一种LPWAN技术,NB-IoT有其固有的局限性,它显然并不适用于要求低时延、高可靠性的业务(车联网、远程医疗),而且中等需求的业务(智能穿戴、智能家居)对于它来说也稍显“吃力”。
在物联网技术生态中,没有一种通信接入技术能够“通吃”所有的应用场景,各种接入技术之间存在一定的互补效应,NB-IoT能够依靠其技术特性在物联网领域中占据着一席之地。
文:王一鸣
对你有什么借鉴意义吗,可以加我微信:ss05050228
我拉你进入江湖群聊
![]()

 Office 中就有许多可用的议程模板
Office 中就有许多可用的议程模板