linux 静默安装 oracle 11
linux 版本
[root@oracle ~]# cat /etc/issue
CentOS release 6.5 (Final)
Kernel \r on an \m
环境检查
top - 16:05:23 up 8:34, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 152 total, 1 running, 151 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1906556k total, 1094320k used, 812236k free, 58280k buffers
Swap: 2097144k total, 0k used, 2097144k free, 839620k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1654 oracle -2 0 1185m 14m 13m S 0.7 0.8 1:52.05 oracle
1799 oracle 20 0 1190m 49m 44m S 0.3 2.7 0:05.11 oracle
16699 root 20 0 15036 1268 948 R 0.3 0.1 0:00.02 top
1 root 20 0 19364 1540 1228 S 0.0 0.1 0:02.77 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root RT 0 0 0 0 S 0.0 0.0 0:00.30 migration/0
4 root 20 0 0 0 0 S 0.0 0.0 0:00.11 ksoftirqd/0
5 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.05 watchdog/0
7 root RT 0 0 0 0 S 0.0 0.0 0:00.01 migration/1
8 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/1
9 root 20 0 0 0 0 S 0.0 0.0 0:00.11 ksoftirqd/1
10 root RT 0 0 0 0 S 0.0 0.0 0:00.05 watchdog/1
11 root RT 0 0 0 0 S 0.0 0.0 0:00.25 migration/2
df -h
检查 swap分区、内存、磁盘大小
官方下载
官方文档
安装 jdk
下载 jdk-8u73-linux-x64.rpm
jdk 下载
安装
rpm -ivh jdk-8u91-linux-x64.rpm
配置环境变量
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_91
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
测试
source /etc/profile
java -version
使用 root 用户配置环境变量
关闭 selinux
selinux 配置文件
[root@oracle ~]# cat /etc/sysconfig/selinux
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
临时关闭
setenforce 0
永久关闭
vim /etc/selinux/config
SELINUX=disabled
关闭防火墙
service iptables stop
systemctl stop firewalld
systemctl disable firewalld
修改主机名
hostname centos
在/etc/hosts文件中添加主机名
[root@centos ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.8.200 centos
ORA-00130: invalid listener address
添加与主机名与IP对应记录,不然在安装数据库时会报错
安装依赖包
yum install gcc
yum install gcc-c++
yum install libaio-devel
yum install compat-gcc-34
yum install compat-gcc-34-c++
建立用户和组
groupadd oinstall
groupadd dba
groupadd oper
useradd -g oinstall -G dba,oper oracle
echo "oracle" | passwd --stdin oracle
id oracle
[root@oracle ~]# id oracle
uid=500(oracle) gid=500(oinstall) groups=500(oinstall),501(dba),502(oper)
建立安装目录、设置文件权限
mkdir -p /u01/app/oracle /product/11.2.0/db_1
mkdir /u01/app/oracle/oradata
mkdir /u01/app/oracle/oraInventory
mkdir /u01/app/oracle/fast_recovery_area
chown -R oracle:oinstall /u01/app
chmod -R 775 /u01/app
修改参数
内核参数
vim /etc/sysctl.conf
fs.aio-max-nr = 1048576
fs.file-max = 6815744
kernel.shmall = 2097152
kernel.shmmax = 1073741824
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
net.ipv4.ip_local_port_range = 9000 65500
net.core.rmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048576
改好后,使之生效
sysctl -p
注:kernel.shmmax = 1073741824(byte)为本机物理内存的一半
修改系统资源限制
vim /etc/security/limits.conf
oracle soft nproc 2047
oracle hard nproc 16384
oracle soft nofile 1024
oracle hard nofile 65536
oracle soft stack 10240
修改用户验证选项
vim /etc/pam.d/login
session required /lib/security/pam_limits.so
session required pam_limits.so
修改用户配置文件
vim /etc/profile
if [ $USER = "oracle" ]; then
if [ $SHELL = "/bin/ksh" ]; then
ulimit -p 16384
ulimit -n 65536
else
ulimit -u 16384 -n 65536
fi
fi
修改 oracle 用户环境变量
vim ~oracle/.bash_profile
ORACLE_BASE=/u01/app/oracle
ORACLE_HOME=$ORACLE_BASE/product/11.2.0/db_1
ORACLE_SID=orcl
PATH=$ORACLE_HOME/bin:$PATH
export ORACLE_BASE ORACLE_HOME ORACLE_SID PATH
准备安装文件
上传安装包到 /tmp 目录下解压修改应答文件进行静默安装
oracle 安装文件名
linux.x64_11gR2_database_1of2.zip
linux.x64_11gR2_database_2of2.zip
修改权限
chown -R oracle:oinstall ./linux.x64_11gR2_database_1of2.zip
chown -R oracle:oinstall ./linux.x64_11gR2_database_2of2.zip
切换 oracle 用户、使修改的环境变量生效
su - oracle
source .bash_profile
解压安装包、复制应答文件到 oracle 用户的目录下
cd /tmp
unziap ./linux.x64_11gR2_database_1of2.zip
unziap ./linux.x64_11gR2_database_2of2.zip
cp -R /tmp/database/response/ /home/oracle/
cd /home/oracle/response/
应答文件
db_install.rsp:安装应答
dbca.rsp:创建数据库应答
netca.rsp:建立监听、本地服务名等网络设置的应答
Oracle 11g 静默安装-db_install.rsp详解
修改应答文件
vim ./db_install.rsp
oracle.install.option=INSTALL_DB_SWONLY
ORACLE_HOSTNAME= localhost.localdomain
UNIX_GROUP_NAME=oinstall
INVENTORY_LOCATION=/u01/app/oraInventory
SELECTED_LANGUAGES=en,zh_CN
ORACLE_HOME=/u01/app/oracle/product/11.2.0/db_1
ORACLE_BASE=/u01/app/oracle
oracle.install.db.InstallEdition=EE
oracle.install.db.DBA_GROUP=dba
oracle.install.db.OPER_GROUP=dba
DECLINE_SECURITY_UPDATES=true
部分参数含义
各参数含义如下:
-silent 表示以静默方式安装,不会有任何提示
-force 允许安装到一个非空目录
-noconfig 表示不运行配置助手netca
-responseFile 表示使用哪个响应文件,必需使用绝对路径
oracle.install.responseFileVersion 响应文件模板的版本,该参数不要更改
oracle.install.option 安装选项,本例只安装oracle软件,该参数不要更改
DECLINE_SECURITY_UPDATES 是否需要在线安全更新,设置为false,该参数不要更改
ORACLE_HOSTNAME 安装主机名
UNIX_GROUP_NAME oracle用户用于安装软件的组名
INVENTORY_LOCATION oracle产品清单目录
SELECTED_LANGUAGES oracle运行语言环境,一般包括引文和简繁体中文
ORACLE_HOME Oracle安装目录
ORACLE_BASE oracle基础目录
oracle.install.db.InstallEdition 安装版本类型,一般是企业版
oracle.install.db.isCustomInstall 是否定制安装,默认Partitioning,OLAP,RAT都选上了
oracle.install.db.customComponents 定制安装组件列表:除了以上默认的,可加上Label Security和Database Vault
oracle.install.db.DBA_GROUP oracle用户用于授予OSDBA权限的组名
oracle.install.db.OPER_GROUP oracle用户用于授予OSOPER权限的组名
静默安装
cd /tmp/database
./runInstaller -silent -responseFile /home/oracle/response/db_install.rsp -ignorePrereq
.
.
.
#Root scripts to run
/u01/app/oracle/oraInventory/orainstRoot.sh
/u01/app/oracle/product/11.2.0/db_1/root.sh
To execute the configuration scripts:
1. Open a terminal window
2. Log in as "root"
3. Run the scripts
4. Return to this window and hit "Enter" key to continue
Successfully Setup Software.
安装完毕后会提示上述的信息,按照要求使用 root 用户执行上面的两个脚本
静默配置监听程序
使用 oracle 用户
netca /silent /responsefile /home/oracle/response/netca.rsp
检验
1、在 /u01/app/oracle/product/11.2.0/db_1/network/admin/中生成 listener.ora和 sqlnet.ora
ll /u01/app/oracle/product/11.2.0/db_1/network/admin/
2、通过netstat命令可以查看1521端口正在监听
netstat -tnul | grep 1521
静默方式建库
dbca -silent -createDatabase -templateName General_Purpose.dbc -gdbname orcl -sid orcl -responseFile NO_VALUE -characterSet ZHS16GBK -memoryPercentage 30 -emConfiguration LOCAL
.
.
.
85% complete
96% complete
100% complete
Look at the log file "/opt/app/oracle/cfgtoollogs/dbca/ora11g/ora11g.log" for further details.
数据库成功安装之后默认是启动状态
参数说明
-silent 指以静默方式执行dbca命令
-createDatabase 指使用dbca
-templateName 指定用来创建数据库的模板名称,这里指定为General_Purposedbc,即一般用途的数据库模板
-gdbname 指定创建的全局数据库名称,这里指定名称为ocp11g
-sid 指定数据库系统标识符,这里指定为ocp11g,与数据库同名
-responseFile 指定安装响应文件,NO_VALUE表示没有指定响应文件
-characterSet 指定数据库使用的字符集,这里指定为AL32UTF8
-memoryPercentage 指定用于oracle的物理内存的百分比,这里指定为30%
-emConfiguration 指定Enterprise Management的管理选项。LOCAL表示数据库由Enterprise Manager本地管理
数据库成功安装之后默认是启动状态
检验
1、进行实例进程检查
ps -ef | grep ora_ | grep -v grep
2、查看监听状态
lsnrctl status
3、登录查看实例状态
sqlplus / as sysdba
设置Linux开机自启动七、 设置Linux开机自启动
修改ORACLE_HOME_LISTNER
将下面两个文件的ORACLE_HOME_LISTNER=$1修改为ORACLE_HOME_LISTNER=$ORACLE_HOME
vim /u01/app/oracle/product/11.2.0/db_1/bin/dbstart
vim /u01/app/oracle/product/11.2.0/db_1/bin/dbshut
配置oratab
vi /etc/oratab
找到testsid:/opt/oracle/102:N,改为testsid:/opt/oracle/102:Y
配置rc.local
vi /etc/rc.d/rc.local
添加如下行
su oracle -lc "/u01/app/oracle/product/11.2.0/db_1/bin/lsnrctl start"
su oracle -lc /u01/app/oracle/product/11.2.0/db_1/bin/dbstart
增加权限
chmod +x /etc/rc.d/rc.local
开放1521端口允许网络连接
service iptables stop
vi /etc/sysconfig/iptables
# Generated by iptables-save v1.4.7 on Fri Dec 16 07:29:41 2016
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [10:892]
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 1521 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
# Completed on Fri Dec 16 07:29:41 2016
service iptables save
service iptables restart
iptables设置详细
利用iptables防火墙允许1521端口被连接
附
参考文档
Oracle 11g R2静默安装(推荐)
Oracle11gR2 for Linux 静默安装(推荐)
CentOS 6.5下静默安装oracle(推荐)
oracle11G静默安装过程——linux环境
Linux下Oracle11g静默安装
CentOS 6.2 X64上64位Oracle11gR2 静默安装,静默设置监听,静默建库
常用命令
lsnrctl start启动监听
lsnrctl stop关闭监听
lsnrctl status查看监听状态
sqlplus /nolog登陆 sqlplus
startup启动数据库
conn /as sysdba用 sysdba 登陆数据库
iptables -L -niptables当前规则
mkdir -p /u01/app/oracle /product/11.2.0/db_1递归创建文件夹
chown -R oracle:oinstall /u01/app修改文件或文件夹的所有者所属组
chmod -R 775 /u01/app修改文件或文件夹权限
vi /etc/sysconfig/iptables修改文本文件
ps -ef | grep ora_ | grep -v grep
netstat -tnul | grep 1521
若有不正确的地方,望大神指教!!!
8.4 静默建立新库(同时也建立一个对应的实例)
修改/etc/dbca.rsp,设置如下:
[GENERAL]
RESPONSEFILE_VERSION = "11.2.0" //不能更改
OPERATION_TYPE = "createDatabase"
GDBNAME = "orcl.test" //全局数据库的名字=SID+主机域名
SID= "orcl" //对应的实例名字
TEMPLATENAME = "General_Purpose.dbc" //建库用的模板文件
SYSPASSWORD = "123456" //SYS管理员密码
SYSTEMPASSWORD = "123456" //SYSTEM管理员密码
DATAFILEDESTINATION = /opt/oracle/oradata //数据文件存放目录
RECOVERYAREADESTINATION=/opt/oracle/ flash_recovery_area //恢复数据存放目录
CHARACTERSET = "ZHS16GBK" //字符集,重要!!! 建库后一般不能更改,所以建库前要确定清楚。(CHARACTERSET = "AL32UTF8"
NATIONALCHARACTERSET= "UTF8")
TOTALMEMORY = "5120" //oracle内存5120MB
然后静默运行:
$dbca -silent -responseFile etc/dbca.rsp
复制数据库文件
1% 已完成
3% 已完成
11% 已完成

 图 1 森林会议
图 1 森林会议 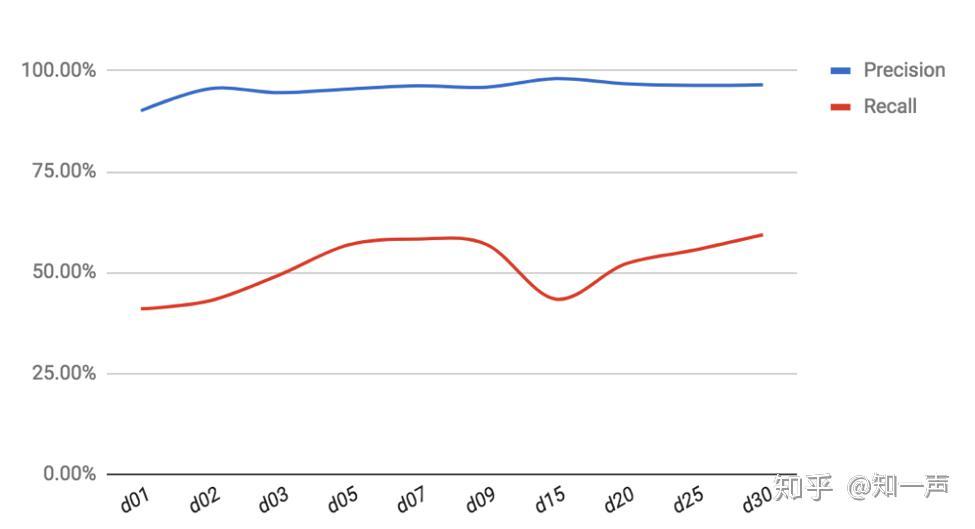 图 2 统计特征累积周期(天)对 Precision 和 Recall 的影响
图 2 统计特征累积周期(天)对 Precision 和 Recall 的影响  图 3 深度学习示意
图 3 深度学习示意 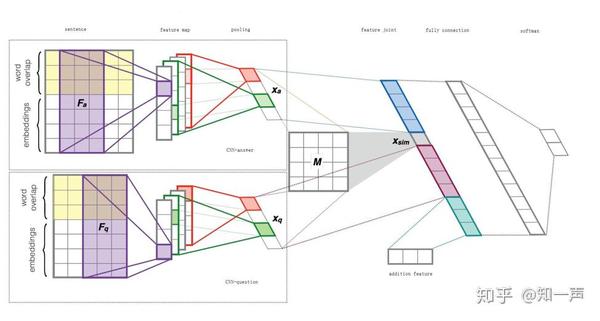 图 4 模型结构
图 4 模型结构 







































































 iPad 对比表格
iPad 对比表格 


 Free Rivers
Free Rivers  Froggipedia
Froggipedia 



 图/Apple 官网
图/Apple 官网
 图/Apple 官网
图/Apple 官网 
















































 尽管补贴下降、利润下滑是所有企业都面临的,但针对利润下滑这一问题,近年来比亚迪已经开始做出调整。在过去很长一段时间,比亚迪的零部件体系一直比较封闭。但由于电动汽车行业垂直整合红利开始下降,“每一颗螺丝钉都要自己做”的时代已经过去。
尽管补贴下降、利润下滑是所有企业都面临的,但针对利润下滑这一问题,近年来比亚迪已经开始做出调整。在过去很长一段时间,比亚迪的零部件体系一直比较封闭。但由于电动汽车行业垂直整合红利开始下降,“每一颗螺丝钉都要自己做”的时代已经过去。







 更多最新信息下载创业邦app
更多最新信息下载创业邦app